%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Easevoice Trainer
EaseVoice Trainerは、音声合成と変換のトレーニングプロセスを簡素化および強化することを目的としたバックエンドプロジェクトです。このプロジェクトはGPT-SoVITSを改良したもので、ユーザーエクスペリエンスとシステムの保守性に重点を置いています。元のプロジェクトとは異なる設計理念に基づいており、小規模な実験から大規模な生産まで、幅広いシナリオに適した、よりモジュール化されカスタマイズ可能なソリューションを提供することを目指しています。このツールは、開発者や研究者が音声合成と変換の研究開発をより効率的に行うのに役立ちます。
["ヴィカス?オル?ウパカーラン],["モダ ルプラーシクシャン?オル?パリニヨージャン]
38.4K

Megatts 3
MegaTTS 3は、バイトダンスが開発したPyTorchベースの高効率音声合成モデルであり、超高品質の音声クローン機能を備えています。軽量のアーキテクチャはわずか0.45Bのパラメータで構成され、中国語、英語、コードの切り替えに対応し、入力テキストに基づいて自然で滑らかな音声を作成できます。学術研究や技術開発で幅広く利用されています。
["ファッション, AI モデル]
38.1K
Openai.fm
OpenAI.fm は、開発者が OpenAI API の最新のテキスト読み上げモデルである gpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-mini-tts を体験できるインタラクティブなデモプラットフォームです。この技術により、自然で滑らかな音声を生成し、テキストコンテンツを生き生きと理解しやすくすることができます。音声アシスタントやコンテンツ作成など、さまざまなアプリケーションシナリオに適しており、開発者がユーザーとより効果的にコミュニケーションを取り、ユーザーエクスペリエンスを向上させるのに役立ちます。この製品は、効率的な音声合成を目的としており、音声機能を統合したい開発者に適しています。
APIサービス
57.7K

Orpheus TTS
Orpheus TTSは、Llama-3bモデルに基づいたオープンソースのテキスト読み上げシステムであり、より自然な人間の音声合成を提供することを目指しています。強力な音声クローン作成機能と感情表現機能を備えており、様々なリアルタイムアプリケーションシナリオに適しています。この製品は無料で、開発者と研究者に便利な音声合成ツールを提供することを目的としています。
["パースウェア],["バックパック]
50.5K
CSM 1B
CSM 1BはLlamaアーキテクチャに基づいた音声生成モデルであり、テキストとオーディオ入力からRVQオーディオコードを生成できます。このモデルは主に音声合成分野で使用され、高品質の音声生成能力を備えています。その利点は、複数話者の会話シーンを処理し、コンテキスト情報を使用して自然で滑らかな音声を生成できることです。このモデルはオープンソースであり、研究と教育目的での使用を支援することを目的としていますが、なりすまし、詐欺、または違法行為に使用することを明確に禁止しています。
ファッションモデル
55.2K
高品質新製品
Sesame CSM
CSMは、Sesameが開発した対話型音声生成モデルであり、テキストと音声入力に基づいて高品質の音声を生成できます。このモデルはLlamaアーキテクチャに基づいており、Mimiオーディオエンコーダーを使用しています。主に音声合成とインタラクティブな音声アプリケーション(音声アシスタントや教育ツールなど)に使用されます。CSMの主な利点は、自然で滑らかな音声を生成できること、そしてコンテキスト情報を使用して音声出力を最適化できることです。このモデルは現在オープンソースであり、研究や教育目的で使用できます。
野菜料理
55.2K
Sesame AI
Sesame AIは次世代の音声合成技術を代表し、高度な人工知能技術と自然言語処理を組み合わせることで、非常にリアルな音声、本物のような感情表現、自然な会話の流れを生成できます。本プラットフォームは、人間のような音声パターンを生成することに優れており、同時に一貫した性格特性を維持できるため、コンテンツ制作者、開発者、企業がアプリケーションに自然な音声機能を追加するのに最適です。具体的な価格と市場における位置付けはまだ不明ですが、その強力な機能と幅広い用途により、市場で高い競争力を有しています。
["料理-から-食べ物],["食べ物-から-料理]
46.6K
Kokorotts
Kokoro TTSは、複数の言語と音声合成機能に対応した強力なテキスト読み上げツールで、EPUB、PDF、およびTXTファイルを、高品質の音声出力に変換できます。開発者とユーザーは、柔軟な音声のカスタマイズオプションを利用して、プロフェッショナルなオーディオを簡単に作成できます。主な利点としては、多言語対応、音声合成、柔軟な入力形式、および無料の商用利用ライセンスなどが挙げられます。本製品は、クリエイター、開発者、企業に効率的で低コストの音声合成ソリューションを提供し、オーディオブックの作成、ビデオナレーション、ポッドキャストの作成、教育コンテンツの生成、顧客サービスなど、さまざまな場面で使用できます。
["料理-レシピ-その他],["野菜と果物]
48.6K

Spark TTS
Spark-TTSは大規模言語モデルに基づいた、効率的なテキスト音声変換モデルであり、シングルストリームデカップリング音声トークンの特徴を持っています。大規模言語モデルの強力な能力を活用して、コードから予測された音声データを直接再構築し、追加の音響特徴量生成モデルを省略することで、効率性を向上させ、複雑さを軽減しています。このモデルはゼロショットテキスト音声変換をサポートし、複数言語やコードの切り替えシナリオに対応できるため、高い自然さと正確性を必要とする音声合成アプリケーションに最適です。また、仮想音声の作成にも対応しており、ユーザーは性別、ピッチ、速度などのパラメーターを調整することで、さまざまな音声を作成できます。このモデルの背景には、従来の音声合成システムにおける非効率性と複雑性の問題解決があり、研究と生産に効率的で柔軟かつ強力なソリューションを提供することを目指しています。現在、このモデルは主に学術研究や合法的なアプリケーション、例えばパーソナライズされた音声合成、支援技術、言語研究などに焦点を当てています。
テキスト読み上げ音声
43.6K

Llasa
Llasaは、大規模な音声合成タスク向けに設計された、Llamaフレームワークに基づくテキスト音声変換(TTS)基礎モデルです。このモデルは16万時間のトークン化された音声データを使用してトレーニングされており、効率的な言語生成能力と多言語対応を備えています。主な利点としては、強力な音声合成能力、低い推論コスト、柔軟なフレームワークとの互換性などがあります。このモデルは、教育、エンターテインメント、ビジネスシーンに適用でき、ユーザーに高品質の音声合成ソリューションを提供します。現在、このモデルはHugging Faceで無料で提供されており、音声合成技術の発展と応用を促進することを目的としています。
テキスト読み上げ音声
44.7K
海外精選
Octave TTS
Octave TTSは、Hume AIによって開発された次世代の音声合成モデルです。テキストを音声に変換するだけでなく、テキストの意味と感情を理解し、表現力豊かな音声出力を生成します。この技術の中核となる強みは、言語に対する深い理解力であり、文脈に基づいて自然で生き生きとした音声を生成できるため、オーディオブック、バーチャルアシスタント、感情的な音声対話など、さまざまなアプリケーションシナリオに適しています。Octave TTSの登場は、音声合成技術が単純なテキスト朗読から、より表現力豊かでインタラクティブな方向への発展を示しており、ユーザーによりパーソナライズされ、感情豊かな音声体験を提供します。現在、この製品は主に開発者とクリエイターを対象としており、APIとプラットフォームを介してサービスを提供しており、将来的にはより多くの言語とアプリケーションシナリオに拡張される予定です。
テキスト読み上げ音声
47.7K

Indextts
IndexTTSは、GPTスタイルのテキスト音声変換(TTS)モデルであり、主にXTTSとTortoiseに基づいて開発されました。ピンインによる漢字の発音修正、句読点によるポーズ制御が可能です。中国語のシナリオでは、文字とピンインの混合モデリング手法を導入することで、トレーニングの安定性、音声の類似性、音質を大幅に向上させています。さらに、BigVGAN2を統合して音声品質を最適化しています。数万時間分のデータでトレーニングされており、XTTS、CosyVoice2、F5-TTSなどの現在普及しているTTSシステムを凌駕する性能を備えています。IndexTTSは、音声アシスタント、オーディオブックなど、高品質の音声合成が必要なシナリオに適しており、オープンソースであるため、学術研究や商業利用にも適しています。
テキスト読み上げ音声
45.3K
中国語精選
星声AI
星声AIは、AIポッドキャストの生成に特化したツールです。kimiなどの高度なLLMモデルとMinimax Speech-01-TurboなどのTTSモデルを活用し、テキストコンテンツを生き生きとしたポッドキャストに迅速に変換します。この技術の主な利点は、効率的なコンテンツ生成能力であり、クリエイターはポッドキャストを迅速に制作し、時間と労力を節約できます。星声AIは、コンテンツクリエイター、ポッドキャスト愛好家、そして迅速にオーディオコンテンツを生成する必要があるユーザーに適しています。ユーザーに便利なポッドキャスト生成ソリューションを提供することを目指しており、現在、明確な価格情報は提供されていません。
音声生成
74.0K
Zonos V0.1 Hybrid
Zonos-v0.1-hybridは、Zyphraによって開発されたオープンソースのテキスト読み上げモデルであり、テキストプロンプトに基づいて自然な音声を出力します。このモデルは膨大な量の英語音声データでトレーニングされており、eSpeakを使用してテキストの正規化と音素化を行い、トランスフォーマーまたは混合バックボーンネットワークでDACトークンを予測します。英語、日本語、中国語、フランス語、ドイツ語など、複数の言語に対応しており、生成される音声の速度、トーン、音質、感情などを細かく制御できます。さらに、5~30秒の音声サンプルだけで高忠実度の音声クローンを作成できる、ゼロショット音声クローン機能も備えています。RTX 4090上でのリアルタイム係数は約2倍で、高速に動作します。使いやすいグラディオインターフェースも備えており、Dockerファイルで簡単にインストールとデプロイが可能です。現在、Hugging Faceで提供されており、ユーザーは無料で利用できますが、自身でデプロイする必要があります。
テキスト読み上げ音声
68.2K
Llasa Training
LLaSA_trainingは、LLaMAベースの音声合成訓練プロジェクトです。訓練時間と推論時間の計算資源を最適化することで、音声合成モデルの効率と性能を向上させます。本プロジェクトは、オープンソースデータセットと内部データセットを用いて訓練を行い、様々な設定と訓練方法に対応しており、高い柔軟性と拡張性を備えています。主な利点として、効率的なデータ処理能力、強力な音声合成効果、そして複数言語のサポートが挙げられます。高性能な音声合成ソリューションを必要とする研究者や開発者にとって最適であり、スマートスピーカー、音声放送システムなどのアプリケーション開発に活用できます。
モデルトレーニングとデプロイメント
49.7K
Llasa 1B
Llasa-1Bは、香港科技大学音声研究室によって開発されたテキスト読み上げモデルです。LLaMAアーキテクチャを基盤とし、XCodec2コードブックの音声トークンを組み合わせることで、自然で滑らかな音声へのテキスト変換を実現しています。25万時間の中国語と英語の音声データで訓練されており、テキストからの音声生成に加え、指定の音声プロンプトを利用した合成も可能です。主な利点として、高品質な多言語音声の生成能力があり、オーディオブック、音声アシスタントなど、様々な音声合成シーンに適しています。本モデルはCC BY-NC-ND 4.0ライセンスを採用しており、商用利用は禁止されています。
テキスト読み上げ音声
60.2K
Llasa 3B
Llasa-3Bは、LLaMAアーキテクチャに基づいて開発された強力なテキスト音声変換(TTS)モデルであり、中国語と英語の音声合成に特化しています。XCodec2の音声符号化技術と組み合わせることで、テキストを自然で滑らかな音声に効率的に変換できます。主な利点としては、高品質の音声出力、多言語合成のサポート、柔軟な音声プロンプト機能などが挙げられます。このモデルは、オーディオブック制作、音声アシスタント開発など、音声合成が必要な様々な場面に適しています。オープンソースであるため、開発者は自由に機能を探求?拡張することができます。
テキスト音声変換
62.1K
AI ContentCraft
AI ContentCraftは、クリエイターがストーリー、ポッドキャスト脚本、マルチメディアコンテンツを迅速に生成できるよう設計された強力なコンテンツ作成プラットフォームです。テキスト生成、音声合成、画像生成技術を統合することで、クリエイターにワンストップソリューションを提供します。日本語と英語のコンテンツ変換に対応しており、効率的なコンテンツ制作が必要なユーザーに最適です。DeepSeek AI、Kokoro TTS、Replicate APIなどの技術スタックを採用し、高品質なコンテンツ生成を確保しています。現在、オープンソースで無料で提供されており、個人およびチームでの使用に適しています。
ライティングアシスタント
66.8K
Hailuo AI 音声合成
Hailuo AI 音声合成は、高度な音声合成技術を用いて、テキストを自然で滑らかな音声に変換します。高品質で表現力豊かな音声生成が可能な点が最大のメリットであり、オーディオブック制作、音声ナレーションなど、幅広い用途に適しています。本製品はプロフェッショナル向けの高度な音声合成ツールとして位置付けられており、現在、期間限定で無料体験を提供し、ユーザーに効率的で便利な音声生成ソリューションを提供することを目指しています。
テキスト読み上げ音声
63.5K
Kokoro Onnx
kokoro-onnxは、KokoroモデルとONNXランタイムに基づくテキスト読み上げ(TTS)プロジェクトです。英語に対応しており、フランス語、日本語、韓国語、中国語への対応も計画されています。macOS M1ではほぼリアルタイムの高速性能を実現し、ささやき声を含む様々な音声オプションを提供します。モデルは軽量で、約300MB(量子化後約80MB)です。このプロジェクトはGitHub上でオープンソースとして公開されており、MITライセンスを採用しているため、開発者は容易に統合して使用できます。
テキスト読み上げ音声
63.2K
Audiblez
Audiblezは、Kokoroの高品質音声合成技術を利用して、一般的な電子書籍(.epub形式)を.m4b形式のオーディオブックに変換するツールです。複数の言語と音声に対応しており、シンプルなコマンドライン操作で変換できます。電子書籍の読書体験を大幅に向上させ、運転中や運動中など、読書が困難な状況でも使用できます。このツールはClaudio Santini氏によって2025年に開発され、MITライセンスの下で無料でオープンソースとして公開されています。
テキスト読み上げ音声
56.6K
Kokoro 82M
Kokoro-82Mは、hexgradによって作成され、Hugging Faceでホストされているテキスト音声変換(TTS)モデルです。8200万パラメーターを備え、Apache 2.0ライセンスの下でオープンソースとして公開されています。2024年12月25日にv0.19版がリリースされ、10種類のユニークな音声パックを提供しています。TTS Spaces Arenaで1位を獲得しており、パラメーター規模とデータ使用における効率性の高さを示しています。アメリカ英語とイギリス英語に対応し、高品質の音声出力を生成できます。
テキスト読み上げ音声
91.1K
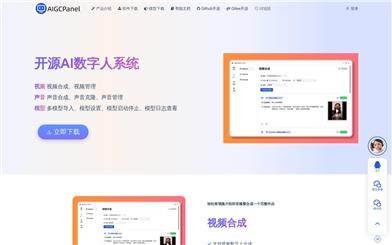
Aigcpanel オープンソースAIデジタルヒューマンシステム
AIGCPanelは、シンプルで使いやすいワンストップAIデジタルヒューマンシステムです。初心者でも簡単に使用できます。動画合成、音声合成、音声クローンに対応し、ローカルモデルの管理、AIモデルのワンクリックインポートと使用を簡素化します。製品の背景情報として、AIGCPanelは、様々なAI機能を統合することで、デジタルヒューマン素材の管理効率を向上させ、技術的ハードルを下げ、専門家でなくても簡単にAIデジタルヒューマンを管理?使用できるようにすることを目的としています。AGPL-3.0オープンソースに基づき、完全に無料で利用できます。
数値人間
69.8K
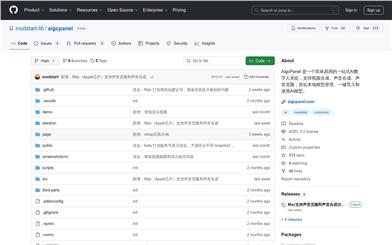
Aigcpanel
AigcPanelは、シンプルで使いやすいワンストップAIデジタルヒューマンシステムです。動画合成、音声合成、音声クローンなどの機能を備え、ローカルモデルの管理、AIモデルのワンクリックインポートと使用を簡素化します。最新のAI技術を活用し、ユーザーに効率的で便利なデジタルヒューマン制作ソリューションを提供します。特に、動画や音声コンテンツ制作が必要な専門家や企業に最適です。その使いやすさ、効率性、強力な機能により、デジタルヒューマン制作分野で確固たる地位を築いています。
数値人間
83.6K
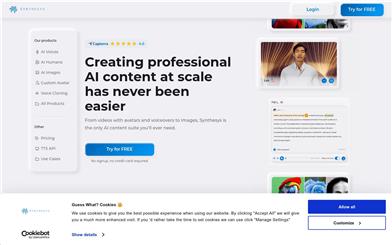
Synthesys
Synthesysは、AIによる動画、音声、画像生成サービスを提供するAIコンテンツ生成プラットフォームです。高度なAI技術を活用することで、低コストかつ簡単な操作でプロレベルのコンテンツ制作を可能にします。市場における高品質?低コストなコンテンツ生成ニーズを背景に開発され、多言語対応の超リアルな音声合成、専門機器不要の高精細動画生成、ユーザーフレンドリーなインターフェースが主な特長です。無料トライアルと様々なレベルの有料サービスを提供し、規模の大小を問わずあらゆる企業のコンテンツ生成ニーズに対応します。
映像制作
61.0K
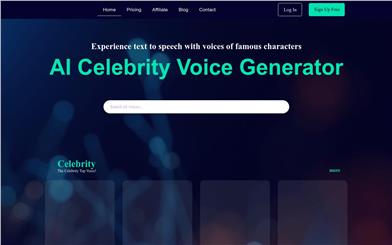
Voxdazz
Voxdazzは、人工知能技術を用いて有名人の声を模倣するオンラインプラットフォームです。ユーザーは有名人の音声テンプレートを選択し、話したい言葉を入力すると、Voxdazzが対応する動画を生成します。この技術は高度なアルゴリズムに基づいており、自然なイントネーション、リズム、強調を再現し、人間の音声に非常に近いクオリティを実現しています。エンターテインメントやユーモラスな動画制作だけでなく、有名人のモノマネコンテンツを共有する際にも活用できます。Voxdazzは高品質の音声生成とユーザーフレンドリーな操作インターフェースにより、ユーザーに全く新しいエンターテインメントと創造的な表現方法を提供します。
言語克服
70.1K
海外精選
Elevenlabs Flash
FlashはElevenLabsが最新リリースしたテキスト読み上げ(Text-to-Speech、TTS)モデルです。75ミリ秒で音声生成(アプリとネットワークの遅延時間含む)を実現し、低遅延の会話型音声エージェントに最適なモデルです。Flash v2は英語のみ対応ですが、Flash v2.5は32言語に対応しており、2文字につき1クレジット消費します。ブラインドテストで、同様の超低遅延モデルを継続的に上回り、速度と品質を両立したモデルです。
テキスト読み上げ音声
56.6K
海外精選
Gemini 2.0 Flash Experimental
Gemini 2.0 Flash Experimentalは、Google DeepMindが開発した最新のAIモデルであり、低遅延と性能向上を実現したインテリジェントエージェント体験を提供することを目指しています。このモデルはネイティブツールを使用でき、初めてネイティブで画像作成と音声生成が可能になり、マルチメディアコンテンツの理解と生成におけるAI技術の大きな進歩を表しています。Gemini Flashモデルファミリーは、その効率的な処理能力と幅広い適用シーンにより、AI分野の発展を推進する重要な技術の1つとなっています。
AIモデル
66.2K

Cosyvoice 2
CosyVoice 2は、アリババグループのSpeechLab@Tongyiチームが開発した音声合成モデルです。教師あり離散音声トークンに基づき、言語モデル(LM)とフローマッチングという2つの一般的な生成モデルを組み合わせることで、高い自然度、内容の一貫性、話者類似性を備えた音声合成を実現しています。本モデルは、マルチモーダル大規模言語モデル(LLM)において、特にインタラクティブな体験において応答遅延とリアルタイム性が重要な音声合成に大きな役割を果たします。CosyVoice 2は、有限標量量子化によって音声トークンのコードブック利用率を高め、テキスト音声変換の言語モデルアーキテクチャを簡素化し、ブロック認識因果フローマッチングモデルを設計することで、さまざまな合成シナリオに対応しています。大規模多言語データセットでトレーニングされており、人間並みの合成品質、極めて低い応答遅延、リアルタイム性を備えています。
言語音声翻訳
64.3K
Cosyvoice音声生成大規模モデル2.0 0.5B
CosyVoice音声生成大規模モデル2.0-0.5Bは、高性能の音声合成モデルです。ゼロショット、クロスリンガルの音声合成に対応しており、テキストコンテンツから直接対応する音声出力を生成できます。通義实验室提供で、強力な音声合成能力と幅広い用途を備え、インテリジェントアシスタント、オーディオブック、バーチャルアバターなどを含みますが、これらに限定されません。このモデルの重要性は、自然で滑らかな音声出力を提供し、人機インタラクションの体験を大幅に豊かにすることです。
テキスト音声変換
69.6K
- 1
- 2
- 3
- 4
- 5
- 6
- 7
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M