%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Dynamiccontrol
DynamicControlは、テキストから画像への拡散モデルの制御力を向上させるためのフレームワークです。多様な制御信号を動的に組み合わせることで、様々な数と種類の条件を適応的に選択し、より信頼性が高く詳細な画像合成を可能にします。このフレームワークはまず、事前学習済みの条件生成モデルと識別モデルを用いた二重ループコントローラーを使用して、すべての入力条件に対する初期の真偽スコア順序を生成します。次に、多様なモダリティを持つ大規模言語モデル(MLLM)を用いて効率的な条件評価器を構築し、条件の順序を最適化します。DynamicControlはMLLMと拡散モデルを統合的に最適化し、MLLMの推論能力を活用して多条件テキストから画像へのタスクを促進し、最終的に順位付けされた条件を入力として並列マルチコントロールアダプターに渡し、動的な視覚条件の特徴マップを学習し、それらを統合してControlNetを調整することで、生成画像の制御を強化します。
AIモデル
48.6K
Synthesys
Synthesysは、AIによる動画、音声、画像生成サービスを提供するAIコンテンツ生成プラットフォームです。高度なAI技術を活用することで、低コストかつ簡単な操作でプロレベルのコンテンツ制作を可能にします。市場における高品質?低コストなコンテンツ生成ニーズを背景に開発され、多言語対応の超リアルな音声合成、専門機器不要の高精細動画生成、ユーザーフレンドリーなインターフェースが主な特長です。無料トライアルと様々なレベルの有料サービスを提供し、規模の大小を問わずあらゆる企業のコンテンツ生成ニーズに対応します。
映像制作
61.3K
Sana 600M 1024px
SanaはNVIDIAが開発したテキスト画像生成フレームワークであり、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性と強力なテキスト画像アライメント機能を備えており、ノートパソコンのGPUでも展開可能です。線形拡散変換器(text-to-image generative model)に基づくモデルで、1648Mパラメータを持ち、1024pxをベースとしたマルチスケールな高解像度画像生成に特化しています。主な利点としては、高解像度画像生成、高速な合成速度、そして強力なテキスト画像アライメント機能が挙げられます。Sanaモデルはオープンソースコードに基づいて開発されており、GitHubでソースコードを入手でき、CC BY-NC-SA 4.0 Licenseに従います。
画像生成
48.9K
Sana 1600M 1024px 多言語対応
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。このモデルは驚異的な速度で高解像度かつ高品質な画像を合成し、強力なテキストと画像の整合性を維持しながら、ノートパソコンのGPUにも展開可能です。Sanaモデルは線形拡散トランスフォーマーに基づいており、事前学習済みのテキストエンコーダーと空間圧縮された潜在特徴エンコーダーを使用し、絵文字、中国語、英語、およびそれらを組み合わせたプロンプトにも対応しています。
画像生成
46.6K
Sana 1.6B
Sana-1.6Bは、線形拡散変換器技術に基づく、高効率で高解像度の画像合成モデルです。NVIDIA研究所によって開発され、DC-AE技術を用いており、32倍の潜在空間を持ち、複数GPU上で動作し、強力な画像生成能力を提供します。Sana-1.6Bは、その効率的な画像合成能力と高品質な出力結果で知られており、画像合成分野における重要な技術です。
画像生成
46.1K

Sana
Sanaは、最大4096×4096ピクセルの高解像度画像を効率的に生成できるテキストツーイメージフレームワークです。高速で高解像度?高品質の画像合成を実現し、強力なテキストと画像の整合性を維持しつつ、ノートパソコンのGPUでも展開可能です。Sanaの中核設計には、深層圧縮自己符号化器、線形拡散変換器(DiT)、デコーダーのみの小型言語モデル(テキストエンコーダーとして)、そして効率的な学習とサンプリング戦略が含まれています。Sana-0.6Bは、最新の巨大拡散モデルと比較して、モデルサイズは20分の1、スループットは100倍以上高速です。さらに、Sana-0.6Bは16GBのノートパソコンGPUで展開可能で、1024×1024ピクセルの画像を1秒未満で生成できます。Sanaは、低コストのコンテンツ制作を可能にします。
画像生成
50.8K
Onediffusion
OneDiffusionは、双方向の画像合成と理解をシームレスにサポートする、多機能で大規模な拡散モデルです。様々なタスクに対応できます。コードとチェックポイントは12月初旬に公開予定です。OneDiffusionの重要性は、画像合成と理解タスクの両方を処理できる点にあり、特に画像生成と認識において、人工知能分野における重要な進歩となります。製品の背景情報として、複数の研究者による共同開発プロジェクトであり、その研究成果はarXivに掲載されていることが挙げられます。
画像生成
50.0K
Any Image Anywhere
Any Image Anywhereは、AIを活用した画像処理ツールです。シンプルな指示で入力画像を様々なコンテキストに配置できます。例えば、エナジードリンクのロゴを製品写真に配置するなどです。この技術の重要性は、リアルな画像合成を迅速に作成できる点にあります。デザイナー、マーケター、コンテンツクリエイターにとって強力なツールであり、時間とリソースを大幅に節約できます。開発者はfab1anで、1日20回の無料利用制限があります。
AI編集
50.2K
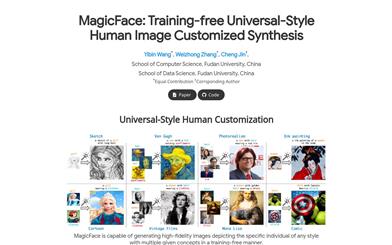
Magicface
MagicFaceは、トレーニング不要でパーソナライズされた人物画像合成を実現する技術です。複数の概念を指定することで、高精細な人物画像を生成できます。本技術は、参照概念の特徴をピクセルレベルで生成領域に正確に統合することで、複数の概念によるパーソナライズされたカスタマイズを実現しています。MagicFaceは、セマンティックレイアウト構築と概念特徴注入の2段階からなる粗から細への生成プロセスを導入し、Reference-aware Self-Attention (RSA)とRegion-grouped Blend Attention (RBA)メカニズムを用いています。本技術は、人物画像合成と多概念人物カスタマイズにおいて優れた性能を示すだけでなく、テクスチャ転送にも利用でき、多機能性と実用性を高めています。
AI画像生成
51.9K
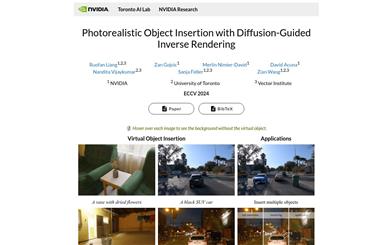
Dipir
DiPIRは、トロントAI研究所とNVIDIA Researchが共同開発した物理ベースの手法です。単一画像からシーンの照明を復元することで、仮想物体を屋内外シーンにリアルに挿入できます。材質と色調マッピングの最適化だけでなく、環境への自動調整も可能で、画像のリアリティを高めます。
AI画像生成
52.2K
中国語精選
創自由
創自由は、人工知能技術を活用して画像デザインと文案作成サービスを提供するオンラインツールです。EC事業者、自メディア、伝統企業などが商品画像、広告画像、ポスター画像などを迅速にデザイン?制作するお手伝いをします。AI換装、AI着せ替え、AI商品画像合成などのAI技術を内蔵しており、効率的な画像制作と文案作成を実現し、コスト削減と効率向上に貢献します。
AI設計ツール
57.1K
Ultrapixel
UltraPixelは、画像解像度を新たな高みへと押し上げることを目指した、高度な超高精細画像合成技術です。香港科技大学(広州)、ファーウェイ?ノアの方舟研究所、マックス?プランク情報学研究所など、複数の機関が共同で開発しました。画像合成、テキストから画像への変換、パーソナライズされたカスタマイズなどにおいて顕著な優位性を持ち、最大4096x4096ピクセルの高解像度画像を生成し、専門的な画像処理やビジュアルアートのニーズを満たします。
AI画像生成
205.6K
Jector
Jectorは、AIを活用したツールで、商品写真の背景を簡単に高品質に生成することに特化しています。AIの設定を簡素化し、独立した生成環境スロット、ノードベースの画像生成履歴を提供することで、ユーザーは簡単に商品画像を作成?合成できます。主な利点としては、複雑な設定不要ですぐに使用開始できること、シンプルながらも高度な柔軟性を備えた生成オプション、自動商品合成、追加のクリアリングと拡大機能などがあります。さらに、無制限の保存とダウンロード機能により、ユーザーは簡単に自分のスタイルに合わせた商品画像を生成し、保存できます。
画像生成
58.0K
高品質新製品

Tryondiffusion
TryOnDiffusionは、革新的な画像合成技術です。2つのUNet(Parallel-UNet)を組み合わせることで、単一のネットワーク内で衣服の細部と、顕著な体の姿勢や形状の変化への適応を同時に実現しています。この技術は、衣服の細部を維持しながら、様々な体の姿勢や形状に適応できるため、従来の方法が抱えていた細部維持と姿勢適応における不足点を解消し、業界をリードする性能を達成しています。
AI画像生成
67.3K
高品質新製品
Hidiffusion
HiDiffusionは、事前学習済み拡散モデルを対象とした技術で、わずか一行のコード追加で、拡散モデルの解像度と速度を向上させます。Resolution-Aware U-Net (RAU-Net)とModified Shifted Window Multi-head Self-Attention (MSW-MSA)技術を用いて、特徴マップのサイズを動的に調整することでオブジェクト複製の問題を解決し、ウィンドウアテンションを最適化することで計算量を削減します。HiDiffusionは、画像生成解像度を4096×4096まで拡張しつつ、従来手法と比較して1.5~6倍の推論速度を実現します。
AI画像生成
82.0K
高品質新製品

Hyper SD
Hyper-SDは、軌跡分割一貫性モデルと低ステップ数推論の長所を活かした、革新的な画像合成フレームワークです。ODE軌跡の保持と再構成の利点を組み合わせ、人間のフィードバック学習によって性能をさらに向上させ、分数蒸留技術により低ステップ数での生成能力を強化しています。Hyper-SDは1~8ステップの推論ステップでSOTA性能を実現し、迅速かつ高品質な画像生成が必要なアプリケーションに最適です。
AI画像生成
98.3K
Magicclothing
MagicClothingは、潜在拡散モデル(LDM)に基づく革新的なネットワークアーキテクチャであり、衣服駆動型画像合成タスクに特化しています。テキストプロンプトに基づいて、特定の衣服を着たカスタマイズされたキャラクター画像を生成し、衣服の詳細を維持しつつ、テキストプロンプトに忠実に表現します。衣服特徴抽出器と自己注意機構融合技術により、高い画像制御性を実現しており、ControlNetやIP-Adapterなどの他の技術と組み合わせることで、キャラクターの多様性と制御性を向上させることができます。さらに、生成画像と元の衣服の一致性を評価するためのマッチングポイントLPIPS(MP-LPIPS)評価指標も開発されました。
AI画像生成
142.4K
マスキング拡散トランスフォーマー (MDT)
MDTは、マスクされた潜在モデルスキームを導入することで、拡散確率モデル(DPMs)が画像内におけるオブジェクト部分間の関係学習能力を明示的に強化します。MDTは訓練中に潜在空間で動作し、特定のトークンをマスクした後、非マスクトークンからマスクトークンを予測する非対称拡散トランスフォーマーを設計します。これは、拡散生成プロセスを維持しながら行われます。MDTv2は、より効率的なマクロネットワーク構造と訓練戦略によって、MDTの性能をさらに向上させています。
AI画像生成
57.4K
軌道一貫性蒸留 (TCD)
TCDは、テキストから画像への合成における一貫性蒸留技術です。軌跡一貫性関数(TCF)と戦略的ランダムサンプリング(SSS)を用いて、生成過程におけるエラーを低減します。TCDは、低いNFE(ノイズフリーエネルギー)において画像品質を大幅に向上させ、高いNFEにおいても教師モデルよりも詳細な結果を維持します。TCDは、追加の識別器やLPIPSの監視を必要とせずに、低NFEと高NFEの両方において優れた生成品質を維持します。
AI画像生成
74.5K
直交微調整 (OFT)
「Controlling Text-to-Image Diffusion」では、強力なテキストから画像への生成モデルを様々な下流タスクに効果的に誘導?制御する方法について研究されています。本研究では、モデルの生成能力を維持できる直交微調整 (OFT) 法が提案されています。OFTは、ニューロン間の超球面エネルギーを不変に保ち、モデルの崩壊を防ぎます。著者らは、主体駆動型生成と制御可能な生成という2つの重要な微調整タスクを検討しました。その結果、OFT法は、生成品質と収束速度において既存の方法を上回ることが示されました。
画像生成
60.7K
Instantid
InstantIDは、強力な拡散モデルに基づくソリューションであり、単一の人物画像を用いて様々なスタイルで画像のパーソナライズ処理を行いながら、高忠実度を維持できます。私たちは、強力な意味論的条件と弱い空間的条件を課すことで、顔画像とランドマーク画像をテキストプロンプトと統合し、画像生成を導く革新的なIdentityNetを設計しました。InstantIDは実用的なアプリケーションにおいて優れた性能を発揮し、SD1.5やSDXLなどの一般的な事前学習済みテキストツーイメージ拡散モデルとシームレスに統合できる、適応可能なプラグインとして機能します。コードと事前学習済みチェックポイントは、このURLで提供されます。
AI画像生成
621.3K

スコア蒸留サンプリング
スコア蒸留サンプリング(SDS)は、テキストプロンプトを用いた最適化問題を制御するために画像拡散モデルを利用する、最近広く普及している手法です。本論文ではSDS損失関数を詳細に分析し、その定式化における固有の問題点を特定し、驚くほど効果的な修正手法を提案しています。具体的には、損失を様々な要因に分解し、ノイズ勾配を生じる成分を分離しました。元の定式化では、ノイズを考慮するために高いテキストガイダンスを用いていましたが、これは望ましくない副作用を引き起こしていました。これに対し、我々は画像拡散モデルの時間ステップ依存的なノイズ除去不十分さを効果的に分離するために、浅層ネットワークを訓練してこれを模倣しました。最適化に基づく画像合成と編集、ゼロショット画像変換ネットワークの訓練、テキストから3Dへの合成など、複数の定性的および定量的実験を通じて、我々の新規な損失定式化の多様性と有効性を示しました。
AI画像生成
59.3K

Reconfusion
ReconFusionは、少量の写真のみを用いて現実世界のシーンを再構成する3D再構成手法です。ニューラル放射場(NeRF)と拡散事前情報を組み合わせることで、入力画像集合を超える新しいカメラ位置において、リアルな幾何形状とテクスチャを合成できます。少量のビューと多ビューのデータセットで拡散事前情報を学習させることで、制約のない領域でリアルな幾何形状とテクスチャを合成し、同時に観測領域の外観を維持できます。ReconFusionは、前方シーンと360度シーンを含む様々な現実世界のデータセットで幅広く評価されており、顕著な性能向上を示しています。
AI画像生成
57.1K
SDXL Turbo オンライン
SDXL Turboは、敵対的拡散蒸留(ADD)技術に基づいたテキストから画像を生成するモデルで、高品質な画像を迅速に生成できます。SDXL 1.0を改良したもので、一度のネットワーク評価で高品質でリアルな画像を合成します。
画像生成
54.6K
GAIA
GAIAは、音声と単一の肖像画像から自然な会話動画を合成することを目的としています。本研究では、会話アバター生成におけるドメイン固有の事前知識を排除するGAIA(Avatarの生成AI)を導入しました。GAIAは、1)各フレームをモーション表現と外観表現に分解する、2)音声と参照肖像画像を条件としてモーションシーケンスを生成する、という二段階のプロセスで構成されます。大規模で高品質な会話アバターデータセットを収集し、様々な規模でモデルを訓練しました。実験結果は、GAIAの優れた性能、拡張性、柔軟性を裏付けています。本手法には、変分オートエンコーダ(VAE)と拡散モデルが用いられており、拡散モデルは音声シーケンスとビデオクリップ内のランダムなフレームを条件としてモーションシーケンスを生成するように最適化されています。GAIAは、制御可能な会話アバター生成やテキストガイドによるアバター生成など、様々な用途に適用可能です。
AI動画生成
67.1K
Luosiallen LCM
luosiallen/latent-consistency-modelは、高解像度の画像を合成するためのモデルです。少ない推論ステップで、一貫性の高い画像を生成します。カスタム入力プロンプトとパラメータ調整に対応しており、リアルなアート作品や人物画像などを生成できます。
AI画像生成
238.5K
Deep Floyd
Deep Floydは、高い写実性と自然言語理解能力を備えたオープンソースのテキストツーイメージモデルです。凍結されたテキストエンコーダと3つのカスケード接続されたピクセル拡散モジュールで構成されています。基礎モデルはテキストプロンプトに基づいて64x64ピクセルの画像を生成し、2つの超解像度モデルはそれぞれ、256x256ピクセルと1024x1024ピクセルへと解像度を段階的に向上させた画像を生成します。モデルのすべての段階で、T5 Transformerベースの凍結されたテキストエンコーダを使用してテキスト埋め込みを抽出し、それをクロスアテンションとアテンションプーリングが強化されたUNetアーキテクチャに入力します。この効率的なモデルは、最先端モデルを上回る性能を示し、COCOデータセットにおいてゼロショットFIDスコア6.66を達成しました。本研究は、カスケード拡散モデルの第1段階におけるより大規模なUNetアーキテクチャの可能性を強調し、テキストツーイメージ合成の有望な未来を示しています。
AI画像生成
50.2K
Runway Gen 2
Gen-2は、テキスト、画像、またはビデオクリップから斬新なビデオを生成できるマルチモーダルAIシステムです。画像またはテキストプロンプトの構図とスタイルをソースビデオの構造に適用する(ビデオからビデオ)か、テキストのみを使用する(テキストからビデオ)ことで実現します。まるで新しいコンテンツを撮影したかのように見えますが、実際には何も撮影していません。Gen-2は、あらゆる画像、ビデオクリップ、またはテキストプロンプトを魅力的な映像作品に変換できる様々なモードを提供します。
AI動画生成
1.1M
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.1K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.0K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M