%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
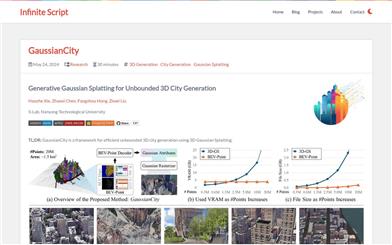
Gaussiancity
GaussianCityは、3Dガウス描画技術に基づいた、境界のない大規模な3D都市を効率的に生成することに特化したフレームワークです。この技術は、コンパクトな3Dシーン表現と空間認識型ガウス属性デコーダを通じて、従来の方法が大規模な都市景観を生成する際に直面するメモリと計算のボトルネックを解決します。主な利点として、単一の前方パスで高速に大規模な3D都市を生成できることがあり、既存技術を大幅に上回ります。本製品は南洋理工大学S-Labチームによって開発され、関連論文はCVPR 2025に掲載されています。コードとモデルはオープンソースであり、3D都市環境を効率的に生成する必要がある研究者や開発者向けです。
3Dモデリング
42.8K
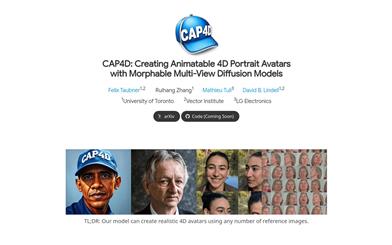
CAP4D
CAP4Dは、変形可能なマルチビュー拡散モデル(Morphable Multi-View Diffusion Models)を利用して4D人物アバターを作成する技術です。任意の数の参照画像から、様々な視点と表情の画像を生成し、それを4Dアバターに適合させることができます。このアバターは3DMMで制御され、リアルタイムでレンダリングされます。主な利点として、きわめてリアルな画像生成、マルチビューへの対応、リアルタイムレンダリング機能が挙げられます。CAP4Dの技術的背景は、深層学習と画像生成分野の最新技術、特に拡散モデルと3D顔面モデリングに基づいています。高画質の画像生成とリアルタイムレンダリング機能により、エンターテインメント、ゲーム開発、仮想現実などの分野で幅広い応用が期待されます。現在、コードは無料で提供されていますが、具体的な商業利用には、さらなるライセンスと価格設定が必要となる可能性があります。
数値人間
59.1K

長尺度体積ビデオ
Long Volumetric Videoは、多視点RGBビデオから長尺度の体積ビデオを再構成するための新技術です。本技術は、Temporal Gaussian Hierarchyという新規の4D表現手法を用いて長尺度体積ビデオをコンパクトにモデル化することで、従来の動的ビュー合成手法が長尺度ビデオ処理において抱えていたメモリ消費量の大幅増加やレンダリング速度の低下といった問題を解決します。本技術の主な利点として、低いトレーニングコスト、高速なレンダリング速度、少ないメモリ使用量が挙げられ、数分間に及ぶボクセルビデオデータを高画質でリアルタイムレンダリング処理できる初の技術です。
映像制作
43.9K
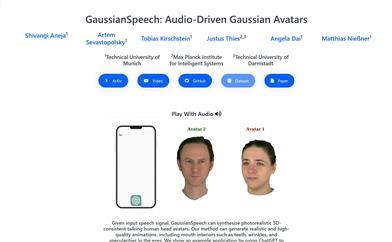
Gaussianspeech
GaussianSpeechは、音声信号から高忠実度のアニメーションシーケンスを合成し、リアルで個性的な3Dアバターを作成できる革新的な手法です。音声信号と3Dガウス描画技術を組み合わせることで、皮膚のしわや細かい表情筋の動きなど、人間の頭部の表情や細かい動作を捉えます。GaussianSpeechの主な利点としては、リアルタイムレンダリング速度、自然な視覚的ダイナミクス、そして多様な表情やスタイルの表現が挙げられます。この技術の背景には、大規模な多視点音声?視覚シーケンスデータセットの作成と、音声条件付き変換モデルの開発があり、これらのモデルは音声入力から直接唇や表情の特徴を抽出できます。
映像制作
46.9K
LTXV
LTXVは、Lightricks社が開発したリアルタイムAI動画生成オープンソースモデルであり、動画生成技術の最先端を代表するものです。LTXVは、拡張性の高い長尺動画制作を可能にし、GPUおよびTPUシステムを最適化することで動画生成時間を大幅に短縮しながら、高い画質を維持します。LTXVの最大の特徴は、フレーム間の整合性を確保し、ちらつきやシーン内の不一致を解消するフレーム間学習技術です。この技術は、効率性向上と動画品質向上を同時に実現するため、動画制作業界にとって大きな進歩と言えます。
動画生成
64.6K

Uravatar
URAvatarは、スマートフォンによるスキャンを用いて、未知の照明条件下でもリアルで再照明可能な頭部アバターを生成する新しい技術です。従来の逆レンダリングによる反射率パラメータ推定とは異なり、URAvatarは放射伝達を直接シミュレーション学習することで、グローバルイルミネーションをリアルタイムレンダリングに効率的に統合します。この技術の重要性は、単一環境のスマートフォンによるスキャンから、様々な環境下でもリアルに見える頭部モデルを再構築し、リアルタイムで駆動?再照明できる点にあります。
画像生成
48.6K
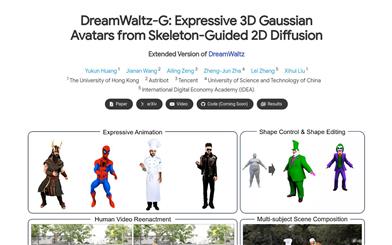
Dreamwaltz G
DreamWaltz-Gは、テキストから3Dアバターと表現力豊かな全身アニメーションを生成するための革新的なフレームワークです。その核心は、スケルトンガイド付きスコア蒸留と混合3Dガウスアバター表現にあります。本フレームワークは、3D人体テンプレートのスケルトン制御を2D拡散モデルに統合することで、視点と人体姿勢の一貫性を向上させ、高品質のアバターを生成します。これにより、複数の顔、余分な手足、ぼやけなどの問題を解決します。さらに、混合3Dガウスアバター表現は、ニューラルインプリシットフィールドとパラメトリック3Dメッシュを組み合わせることで、リアルタイムレンダリング、安定したSDS最適化、そして表現力豊かなアニメーションを実現します。DreamWaltz-Gは、3Dアバターの生成とアニメーションにおいて非常に効果的で、視覚的品質とアニメーション表現力の両方において既存の手法を凌駕しています。さらに、本フレームワークは、ヒューマンビデオリエンアクティングやマルチテーマシーンの組み合わせなど、様々な用途に対応しています。
AI画像生成
50.8K
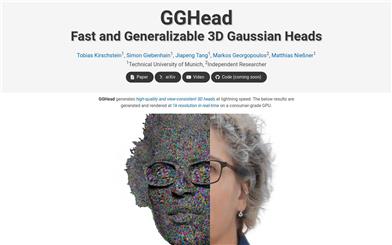
Gghead
GGHeadは、2D画像集合から3Dヘッドの事前情報を学習する、3Dガウス散乱表現に基づいた3D敵対的生成ネットワーク(GAN)です。本技術は、テンプレートヘッドメッシュのUV空間の規則性を活用することで、一連の3Dガウス属性を予測し、予測プロセスを簡素化します。GGHeadの主な利点には、高効率、高解像度生成、完全3D整合性、およびリアルタイムレンダリングの実現があります。新規の全変動損失を用いて生成される3Dヘッドの幾何学的忠実度を高め、隣接するレンダリングピクセルがUV空間で近いガウスに由来することを保証します。
AI画像生成
56.6K

Dualgs
Robust Dual Gaussian Splatting (DualGS) は、関節ガウスと皮膚ガウスを最適化することで複雑な人体パフォーマンスを捉え、堅牢な追跡と高忠実度レンダリングを実現する、新しいガウスベースのボリュメトリックビデオ表現手法です。SIGGRAPH Asia 2024で発表され、ローエンドモバイルデバイスやVRヘッドセットでのリアルタイムレンダリングを可能にし、ユーザーフレンドリーでインタラクティブな体験を提供します。DualGSは混合圧縮戦略により、最大120倍の圧縮率を実現し、ボリュメトリックビデオのストレージと転送をより効率的にします。
AI動画生成
47.7K

書生?天際landmark
書生?天際Landmarkは、NeRF技術に基づく実景3D大規模モデルです。100平方キロメートル、4K高解像度でのトレーニングを実現し、リアルタイムレンダリングと自由編集機能を備えています。この技術は、都市レベルの3Dモデリングとレンダリングにおいて新たな高みを示し、非常に高いトレーニングとレンダリング効率を誇ります。都市計画、建築設計、仮想現実などの分野に強力なツールを提供します。
3Dモデリング
52.2K

Xhand
XHandは、浙江大学が開発した、高精細で表現力豊かな手部アバターをリアルタイムで生成するモデルです。多視点ビデオを用いて作成され、MANO姿勢パラメータを利用して高精細なメッシュとレンダリング画像を生成することで、様々なポーズでのリアルタイムレンダリングを実現しています。XHandは画像のリアルさおよびレンダリング品質において顕著な優位性を持ち、特に拡張現実やゲーム分野において、リアルな手部画像を即座にレンダリングすることができます。
AI顔画像生成
50.2K
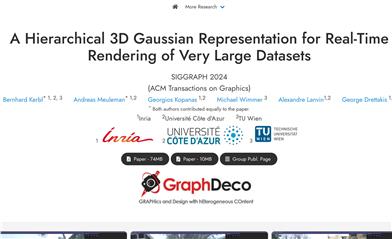
階層型3Dガウス
本研究では、非常に大規模なデータセットのリアルタイムレンダリングに用いる、新たな階層型3Dガウス表現手法を提案します。この手法は、3Dガウススプラッティング技術により、優れた画質、高速なトレーニング、リアルタイムレンダリングを実現します。階層構造と効率的なレベルオブディテール(LOD)ソリューションにより、遠景の効率的なレンダリングと、異なるレベル間の滑らかな遷移が可能です。本技術は利用可能なリソースに適応し、分割統治法を用いて大規模シーンをトレーニングし、視覚的な品質を向上させるためにガウスの結合を中間ノードに最適化できる階層構造に統合します。
3Dモデリング
68.4K
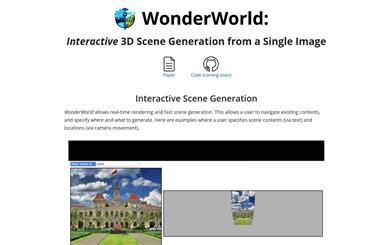
Wonderworld
WonderWorldは革新的な3Dシーン拡張フレームワークです。ユーザーは単一の入力画像とユーザー指定のテキストに基づいて、仮想環境を探求し、形成することができます。高速ガウシアンボクセルとガイド付き拡散による深度推定手法により、計算時間を大幅に削減し、幾何学的に整合性の取れた拡張を生成します。これにより、3Dシーンの生成時間を10秒未満に短縮し、リアルタイムでのユーザーインタラクションと探索を可能にします。これは、仮想現実、ゲーム、クリエイティブデザインなどの分野において、没入型仮想世界の迅速な生成とナビゲーションの可能性を提供します。
AI画像生成
57.7K
高品質新製品

E3gen
E3Genは、高忠実度のデジタルアバターをリアルタイムで生成できる、新しい手法です。精細な衣服のシワ表現、多様な視点と全身ポーズの包括的な制御、属性の転送と局所的な編集に対応しています。3Dガウスを構造化された2D UV空間にエンコードすることで、3Dガウスと現在の生成プロセスとの非互換性の問題を解決し、複数の主体を含むトレーニングにおける3Dガウスの表現力豊かなアニメーションの可能性を探求しています。
AI顔画像生成
54.1K
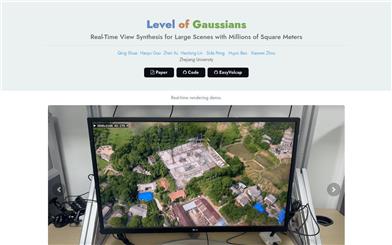
ガウシアンレベル(log)
ガウシアンレベル(LoG)は、3Dシーンを効率的にレンダリングするための新しい技術です。ツリー構造でガウシアンプリミティブを格納し、漸進的トレーニング戦略によって画像からエンドツーエンドで再構築することで、局所的最小値を効果的に克服し、数百万平方キロメートルにおよぶ領域のリアルタイムレンダリングを実現します。これは、大規模シーンレンダリングにおける重要な進歩です。
AI画像生成
54.1K
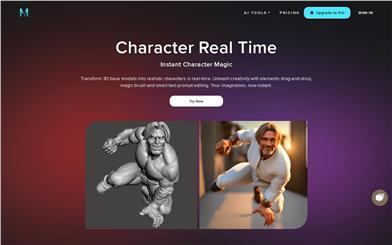
Museclip.ai
Museclipは、3Dモデルベースのリアルタイム人物デザインプラットフォームです。インテリジェントな編集機能、魔法のペン、テキストプロンプトなどを備え、数秒で3D人物の基本モデルをリアルなキャラクターに変換し、人物デザインの効率を大幅に向上させます。主な利点としては、リアルタイムレンダリング技術、迅速なカスタマイズ、スマートでシンプルなデザインワークフローがあり、ユーザーに大きな創作の自由度を提供します。
AI設計ツール
70.9K

Gauhuman
GauHumanはガウス拡散に基づく3D人体モデルであり、短時間(1~2分)でトレーニングを完了し、リアルタイムレンダリング(最大189 FPS)を提供します。これは、NeRFベースの陰的表現モデリングフレームワークと比較して、数時間ものトレーニングとフレーム毎数秒のレンダリングが必要となる従来の方法とは大きく異なります。GauHumanは正規空間でガウス拡散をエンコードし、線形ブレンドスキニング(LBS)を用いて3Dガウスを正規空間からポーズ空間へ変換します。この過程で、計算コストをほとんど増やすことなく3D人体詳細を学習する効果的なポーズとLBSの最適化モジュールを設計しています。さらに、3D人体事前情報による初期化と3Dガウスのトリミング、KLダイバージェンスによる分割/複製、そして高速化のための新たなマージ操作によって、高速最適化を実現しています。
AIモデル
130.5K

Bakedavatar
BakedAvatarは、標準的な多角形ラスタ化パイプラインに展開可能な、リアルタイムニューラルアバター合成のための全く新しい表現です。この手法は、学習済みのヘッドアイソサーフェスから変形可能な多層メッシュを抽出し、静的テクスチャにベイクできる表情、姿勢、視点関連の外観を計算することで、リアルタイム4Dアバター合成を実現します。3段階のニューラルアバター合成パイプラインを提案します。これには、連続変形、マニフォルド、放射場を学習すること、階層メッシュとテクスチャを抽出すること、微分ラスタ化によるテクスチャ詳細の微調整が含まれます。実験結果は、当社の表現が他の最先端手法と同等の合成結果を生み出し、必要な推論時間を大幅に削減することを示しています。さらに、ビュー合成、顔の再現、表情編集、姿勢編集など、単眼ビデオから生成された様々なアバター合成結果を示します。これらは全てインタラクティブなフレームレートで行われます。
AI顔画像生成
70.4K
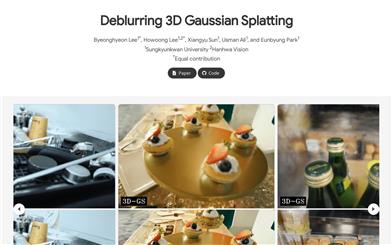
3Dガウシアン?スプラッティングによるデブラーリング
3D Gaussian Splattingによるデブラーリングは、新しく提案されたラスタ化手法、3Dガウス、およびラスタ化に基づく、神経場を用いた新しいデブラーリングフレームワークです。小型の多層パーセプトロン(MLP)を使用することで、ぼやけた画像から詳細な画像をリアルタイムでレンダリングしながら再構築できます。本手法は、トレーニング中にK-最近傍(KNN)アルゴリズムを用いて追加の点を付加することで点群をより高密度にし、相対深度に基づいて3Dガウスを疎に間引きすることで、より多くの3Dガウスを保持します。複数の実験により、そのデブラーリングにおける有効性が確認されています。
AI画像増強
72.9K
Human101
Human101は、単一視点から人体を高速に再構築するフレームワークです。100秒以内に3Dガウスモデルの学習を完了し、フレーム毎の高ス属性を事前に保存することなく、1024解像度の画像を60FPS以上でレンダリングできます。Human101のパイプラインは以下の通りです。まず、単一視点のビデオから2D人体姿勢を抽出します。次に、姿勢駆動型の3Dシミュレータを用いて、対応する3D骨格アニメーションを生成します。最後に、このアニメーションに基づいて時間的に関連付けられた3Dガウスモデルを構築し、リアルタイムレンダリングを行います。
AI画像生成
107.9K
Cyanpuppets
Cyanpuppetsは、2Dビデオから3Dモーションモデルを生成することに特化したAIアルゴリズム開発チームです。彼らのマーカーレスモーションキャプチャシステムは、2台のRGBカメラを用いて208個以上のキーポイントを捕捉し、UE5およびUnity 2021に対応、遅延はわずか0.1秒です。Cyanpuppetsは多くのボーン構造規格に対応しており、その技術はゲーム、映画、その他のエンターテイメント分野で幅広く活用されています。
AI設計ツール
197.9K
Sloyd
Sloydは、3Dモデルを迅速に生成するプラットフォームです。ジェネレーターを選択し、微調整するだけで完了します。リアルタイムプレビューでモデルを生成できます。Sloydは、継続的に拡張されるジェネレーターライブラリを提供し、モデルを迅速にカスタマイズできます。リアルタイムレンダリングや様々なレベルの詳細にも対応しています。生成されたモデルは必要に応じてカスタマイズ可能で、UV展開と最適化が済んでいるため、テクスチャリングと使用が容易です。Sloydはあらゆるスタイルのモデルに対応し、無限のバリエーションを提供し、リアルタイム生成をサポートします。
3Dモデリング
50.0K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.1K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.0K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M