%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
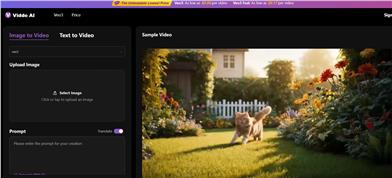
Viddo
Viddo AIはAIビデオジェネレーターで、テキストや画像を驚くべきビデオに変換します。テキストからビデオ、画像からビデオなどのさまざまな機能を持ち、創造力を無限に伸ばすための強力なツールです。
テキストからビデオ
38.4K
Vexub
Vexubは、人工知能技術を利用して高品質なビデオを迅速に生成するツールです。テキストやオーディオ素材を魅力的なビデオ作品に変換し、ビデオ制作の効率を向上させます。個人クリエイターや商業ユーザーに適しています。Vexubは、簡単で使いやすいビデオ作成ツールを提供し、創作をより簡単かつ効率的にします。料金はベーシック、プロフェッショナル、エンタープライズ版があり、さまざまなユーザーのニーズに対応します。
人工知能
37.5K

Pixverse MCP
PixVerse-MCPは、モデルコンテキストプロトコル(MCP)をサポートするアプリケーションを介して、PixVerseの最新のビデオ生成モデルにアクセスできるツールです。テキストからビデオへの変換などの機能を提供し、クリエイターと開発者がどこでも高品質のビデオを生成できます。PixVerseプラットフォームではAPIクレジットが必要であり、ユーザーが別途購入する必要があります。
ビデオ アップデート
38.1K
高品質新製品

Vidu Q1
Vidu Q1は、生数科技が開発した国産ビデオ生成大規模言語モデルで、ビデオクリエーター向けに設計されており、1080pの高解像度ビデオ生成に対応し、映画レベルのカメラワークと先頭と末尾のフレーム機能を備えています。この製品は、VBench-1.0とVBench-2.0の評価でトップにランクインしており、コストパフォーマンスに優れ、価格は競合製品の10分の1です。映画、広告、アニメーションなど、さまざまな分野に適用でき、制作コストの大幅な削減と制作効率の向上を実現します。
["ビデオ アップデート, AI モデル]
37.8K
Magic 1 For 1
Magic 1-For-1は、効率的なビデオ生成に特化したモデルであり、テキストと画像をビデオに高速に変換する機能がコアです。テキストからビデオへの生成タスクを、テキストから画像、画像からビデオの2つのサブタスクに分解することで、メモリ使用量を最適化し、推論の遅延を削減しています。主な利点としては、効率性、低遅延、拡張性があります。このモデルは北京大学DA-Groupチームによって開発され、インタラクティブな基礎ビデオ生成分野の発展を目指しています。現在、このモデルと関連コードはオープンソース化されており、ユーザーは無料で使用できますが、オープンソースライセンス契約を遵守する必要があります。
映像制作
54.1K
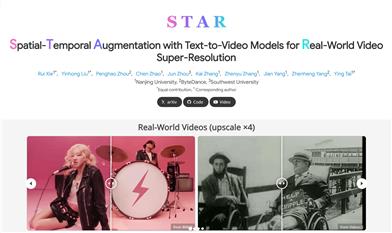
STAR
STARは、テキストからビデオへの拡散モデルとビデオ超解像度を組み合わせることで、従来のGAN方式における過剰な平滑化の問題を解決する革新的なビデオ超解像度技術です。この技術は、ビデオの細部を復元するだけでなく、ビデオの時空間の一貫性を維持し、様々な実世界のビデオシーンに適用できます。STARは南京大学、バイトダンスなどの機関が共同で開発し、高い学術的価値と応用前景を持っています。
映像制作
56.9K
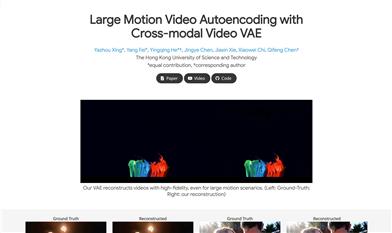
Videovaeplus
これは、ビデオ冗長性を削減し、効率的なビデオ生成を促進することを目的としたビデオ変分オートエンコーダー(VAE)です。本モデルでは、画像VAEを直接3D VAEに拡張するとモーションブラーとディテール歪みが発生することを観察し、空間情報のエンコードとデコードを向上させるため、時間認識空間圧縮を提案しています。さらに、軽量なモーション圧縮モデルを統合し、時間圧縮をさらに実現しています。テキストからビデオのデータセットに固有のテキスト情報を活用し、モデルにテキストガイダンスを追加することで、特にディテール保持と時間安定性に関して、再構成品質が大幅に向上しました。また、画像とビデオで共同トレーニングを行うことで汎用性を高め、再構成品質の向上だけでなく、画像とビデオの自己符号化も可能にしました。広範な評価により、本手法が最新の強力なベースラインよりも優れた性能を示すことが明らかになりました。
動画制作
45.3K
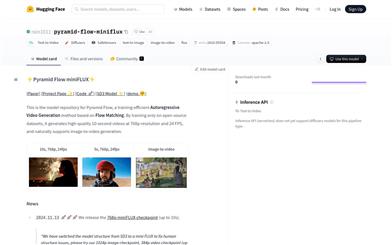
Pyramid Flow Miniflux
Pyramid Flow miniFLUXは、流マッチングに基づく自己回帰型ビデオ生成手法です。トレーニング効率とオープンソースデータセットの利用に重点を置いており、高品質な10秒間の768p解像度、24fpsのビデオ生成が可能です。画像からビデオへの生成も自然にサポートしており、動画コンテンツ制作や研究分野、特にシームレスな動画像生成が必要な場面で重要なツールとなります。
流マッチング
54.4K
Allegro
Allegroは、Rhymes AIによって開発された高度なテキストからビデオへの生成モデルです。シンプルなテキストプロンプトから高品質の短いビデオクリップを生成できます。オープンソースであるため、クリエイター、開発者、そしてAIビデオ生成分野の研究者にとって強力なツールとなっています。主な利点として、オープンソースであること、多様なコンテンツ作成、高品質な出力、そしてモデルサイズが小さく効率的であることが挙げられます。FP32、BF16、FP16など、複数の精度に対応しており、BF16モードではGPUメモリ使用量が9.3GB、コンテキスト長は79.2k(約88フレーム)です。Allegroの中核技術には、大規模なビデオデータ処理、ビデオの視覚トークンへの圧縮、拡張ビデオ拡散トランスフォーマーが含まれます。
映像制作
49.4K
高品質新製品
Cogvideox
CogVideoXは、商用モデルと同等の技術を用いたオープンソースのビデオ生成モデルです。テキストによる説明からビデオコンテンツを生成できます。テキストからビデオを生成する技術の最新成果であり、高品質なビデオ生成能力を備え、エンターテインメント、教育、商業広告など幅広い分野で活用できます。
AI動画生成
67.1K
Open Sora Plan V1.2
Open-Sora Plan v1.2は、テキストからビデオへの変換タスクに特化したオープンソースのビデオ生成モデルです。3D全注意機構を採用することで、ビデオの視覚表現を最適化し、推論効率を向上させています。このモデルはビデオ生成分野において革新的なものであり、空間と時間の特徴をより適切に捉えることで、ビデオコンテンツの自動生成に新たな技術的アプローチを提供します。
AI動画生成
97.7K
高品質新製品
Videotetris
VideoTetrisは、テキストからビデオを生成する斬新なフレームワークです。特に、複数のオブジェクトやオブジェクト数の動的な変化を含む複雑なビデオ生成シーンの処理に適しています。このフレームワークは、空間時間結合拡散技術を用いて複雑なテキストの意味を正確に追従し、ノイズ除去ネットワークの空間的および時間的なアテンションマップを操作および結合することで実現しています。さらに、自己回帰ビデオ生成の一貫性を向上させる新しい参照フレームアテンションメカニズムも導入しています。VideoTetrisは、テキストからビデオへの生成において、定性的かつ定量的に印象的な結果を得ています。
AI動画生成
82.5K
Mira
Mira(Mini-Sora)は、特にSora風のビデオ生成において、高画質で長時間のビデオ生成を探求する実験的なプロジェクトです。既存のテキストからビデオへの変換(T2V)生成フレームワークを基に、シーケンス長の拡張、ダイナミクス強化、3D整合性の維持という3つの重要な側面でブレークスルーを実現しています。現在、Miraプロジェクトは実験段階にあり、Soraなどのより高度なビデオ生成技術と比較して、改善の余地があります。
AI動画生成
79.5K
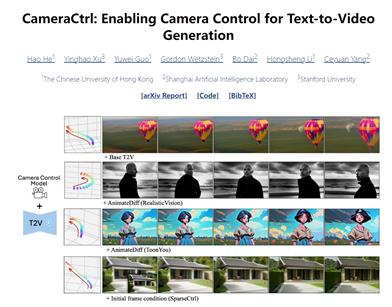
Cameractrl
CameraCtrlは、テキスト生成ビデオモデルに精密なカメラ姿勢制御を提供するために開発されました。カメラエンコーダのトレーニングを通じてパラメータ化されたカメラ軌跡を実現し、ビデオ生成プロセスにおけるカメラ制御を可能にします。様々なデータセットの効果を総合的に研究した結果、ビデオが多様なカメラ分布と類似した外観を持つことで、制御性と汎化能力が向上することが証明されました。実験により、CameraCtrlは正確で、ドメインに適応したカメラ制御において非常に有効であり、テキストとカメラ姿勢の入力から動的でカスタマイズされたビデオナラティブを実現するための重要な進歩であることが示されました。
AI動画生成
83.6K
VLOGGER
VLOGGERは、一枚の人物入力画像からテキストと音声で駆動される話す人間のビデオを生成する手法です。これは、近年の生成拡散モデルの成功に基づいています。私たちの手法は、1) ランダムな人物から3Dモーションへの拡散モデル、そして2) 時間と空間制御を強化した、新規の拡散ベースアーキテクチャによるテキストから画像へのモデルを含みます。この手法は、可変長の高品質ビデオを生成でき、人間の顔と体の高度な表現方法によって容易に制御できます。以前の研究とは異なり、私たちの手法は個人ごとにトレーニングする必要がなく、顔検出や切り抜きにも依存しません。全身像(顔や唇だけでなく)を生成し、人間らしいコミュニケーションに必要な幅広いシーン(例えば、見える体幹や多様な体格)を考慮しています。
AI動画生成
318.2K

Opendit
OpenDiTはオープンソースプロジェクトであり、Colossal-AIベースのDiffusion Transformer(DiT)の高性能実装を提供します。テキストからビデオへの生成やテキストから画像への生成といったDiTアプリケーションのトレーニングと推論効率を向上させるために設計されています。OpenDiTは以下の技術により性能を向上させます。GPU上で最大80%の高速化と50%のメモリ削減を実現し、FlashAttention、Fused AdaLN、Fused layernormといったコア最適化を含みます。ZeRO、Gemini、DDPの混合並列手法や、EMAモデルのシャーディングによるメモリコストの更なる削減、FastSeq(活性化サイズが大きくパラメータサイズが小さいDiTなどのワークロードに特に適した、新規のシーケンシャル並列手法)を採用しています。単ノードシーケンシャル並列処理により通信コストを最大48%削減し、単一GPUのメモリ制限を突破することで、トレーニングと推論の全体時間を短縮します。わずかなコード変更で大幅な性能向上を実現し、ユーザーは分散トレーニングの実装詳細を理解する必要がありません。テキストから画像への生成とテキストからビデオへの生成の完全なワークフローを提供し、研究者やエンジニアは容易に当社のワークフローを実際のアプリケーションに適用?調整でき、並列処理部分を変更する必要はありません。ImageNetを用いたテキストから画像へのトレーニングを行い、チェックポイントを公開しています。
AIモデル推論訓練
129.4K
Sora AIビデオ
Soraは、OpenAIが開発したテキストからビデオを生成するモデルです。テキストの説明に基づき、最大1分間のリアルな画像シーケンスを生成できます。物理世界の動きを理解しシミュレートする能力を備え、実物とのインタラクションが必要な問題解決を支援するモデルの開発を目指しています。長文のプロンプトにも対応し、テキスト入力に基づいて様々な人物、動物、風景、都市の情景を生成できます。ただし、複雑なシーンの物理現象や因果関係の正確な描写は苦手です。
映像制作
439.7K
Opus
Opusは、デジタル時代に向けたスマートラグジュアリーな製品です。テキストからビデオを生成する機能を提供します。AI技術を活用し、テキストをビデオに変換することで、シーンの迅速な生成、キャラクターの設定、特殊効果の追加などを実現し、ユーザーは想像力豊かな作品を簡単に作成できます。Opusはコストと速度において圧倒的な優位性を持ち、ユーザーは容易に自分のアイデアを実現できます。ゲーム、アート、音楽、ストーリーテリングなど、様々なシーンに適用可能です。
映像制作
57.7K
Lumiere
Lumiereは、リアルで多様性があり、連続した動きを示すビデオを合成することを目的とした、テキストからビデオへの拡散モデルです。ビデオ合成における主要な課題の解決を目指しています。本モデルでは、ビデオ全体の時間的持続を一度に生成できる時空間U-Netアーキテクチャを導入しました。これは、遠距離のキーフレームを合成し、その後時間的超解像度処理を行う既存のビデオモデルとは対照的であり、この手法ではグローバルな時間的一貫性を達成することが本質的に困難です。空間と(重要なことですが)時間のダウンサンプリングとアップサンプリングを導入し、事前学習済みのテキストから画像への拡散モデルを活用することで、当モデルは全フレームレートの低解像度ビデオを複数の時空間スケールで直接生成することを学習します。最先端のテキストからビデオへの生成結果を示し、当モデルの設計が、画像からビデオ、ビデオ修復、スタイル変換生成など、様々なコンテンツ制作タスクやビデオ編集アプリケーションを容易に促進することを示します。
AI動画生成
873.8K
中国語精選
Magicvideo V2
MagicVideo-V2は、テキストから画像生成モデル、ビデオモーションジェネレーター、参照画像埋め込みモジュール、フレーム補間モジュールを統合したエンドツーエンドのビデオ生成パイプラインです。そのアーキテクチャ設計により、MagicVideo-V2は、優れた忠実度と滑らかさを備えた、美しく高解像度のビデオを生成できます。大規模なユーザー評価を通じて、Runway、Pika 1.0、Morph、Moon Valley、Stable Video Diffusionなどの最先端のテキストからビデオ生成システムよりも優れた性能を示しています。
AI動画生成
6.7M
中国語精選

Instructvideo
InstructVideoは、人間からのフィードバックによる報酬強化学習を用いて、テキストからビデオへの拡散モデルを指導する手法です。編集方式による報酬強化学習を採用することで、微調整コストの削減と効率の向上を実現しています。確立された画像報酬モデルを用い、セグメント化された疎なサンプリングと時間減衰報酬によって報酬信号を提供することで、生成ビデオの画質を大幅に向上させています。InstructVideoは、生成ビデオの画質向上だけでなく、高い汎化能力も維持します。詳細については、公式ウェブサイトをご覧ください。
AI動画生成
130.5K
Shortvideogen
ShortVideoGenは、シンプルで使いやすいテキストからビデオへの変換アプリです。最先端のビデオおよび音声生成AIモデルを使用し、数秒でパーソナライズされたビデオを作成できます。テキストプロンプトを入力し、フレームレートと最大フレーム数を指定し、音声の有無を選択するだけで、魔法のように必要なビデオが生成されます。
映像制作
199.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.7K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.4K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.4K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M