%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


Longvu
紹介 :
LongVUは、革新的な長尺動画言語理解モデルです。時空間適応圧縮機構を通じて動画の標識数を削減しながら、長尺動画における視覚的なディテールを保持します。この技術の重要性は、大量の動画フレームを処理でき、限られたコンテキスト長の範囲内で視覚情報の損失を最小限に抑え、長尺動画の内容理解と分析能力を大幅に向上させる点にあります。LongVUは、複数の動画理解ベンチマークテストにおいて既存の手法を上回り、特に1時間の長さの動画を理解するタスクにおいて顕著な成果を上げています。さらに、LongVUは、最先端の動画理解性能を維持しながら、より小型のモデルサイズにも効率的に拡張できます。
ターゲットユーザー :
LongVUのターゲットユーザーは、動画コンテンツの分析と理解分野の研究者や開発者、特に長尺動画コンテンツを処理し、限られた計算資源下で効率的な動画理解を実現したい専門家です。さらに、動画分析分野に最新の人工知能技術を適用したい企業や機関にとっても、LongVUは先進的なソリューションを提供します。
使用シナリオ
ユーザーが動画コンテンツの詳細を尋ねると、LongVUは詳細な動画シーンの説明を提供する。
ユーザーが動画内の特定の行動に関する質問をすると、LongVUは正確に識別して回答する。
ユーザーが動画内の特定の物体の移動方向を知りたい場合、LongVUは正確に識別して物体の動きを説明する。
製品特徴
DINOv2特徴を用いて、高類似性の冗長フレームを除去する
テキストガイド付きのクロスモーダルクエリを用いて、選択的なフレーム特徴の縮減を行う
フレーム間の時間依存性に基づいて、空間標識の縮減を行う
限られたコンテキスト長内で大量の動画フレームを効率的に処理する
複数の動画理解ベンチマークテストにおいて、既存の手法を上回る
軽量な大規模言語モデルに対応し、高性能な動画理解を実現する
使用チュートリアル
ステップ1:LongVUの公式プロジェクトページにアクセスする。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
ステップ2:必要な依存ライブラリとフレームワークをダウンロードしてインストールする。
ステップ3:プロジェクトページに記載されているガイドラインに従って、動画データを準備する。
ステップ4:LongVUが提供するコードとモデルを用いて、動画コンテンツの理解と分析を行う。
ステップ5:必要に応じてモデルパラメータを調整し、異なる動画コンテンツと分析ニーズに適合させる。
ステップ6:モデルを実行し、動画理解の結果を確認する。
ステップ7:結果に基づいてさらに分析を行うか、実際の動画処理タスクに適用する。


おすすめAI製品
Deepseek R1 Distill Qwen 7B
DeepSeek-R1-Distill-Qwen-7Bは、Qwen-7Bを蒸留最適化し、強化学習によって最適化された推論モデルです。数学、コード、推論タスクにおいて優れた性能を発揮し、高品質な推論チェーンと解決策を生成できます。大規模な強化学習とデータ蒸留技術により、推論能力と効率性が大幅に向上しており、複雑な推論と論理分析が必要なシナリオに適しています。
モデルトレーニングとデプロイメント
138.8K
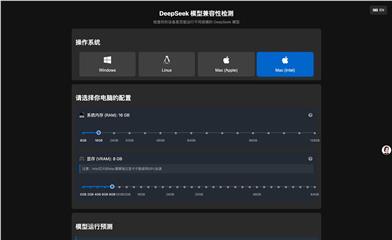
Deepseekモデル互換性チェック
DeepSeekモデル互換性チェックは、デバイスが様々な規模のDeepSeekモデルを実行できるかどうかを評価するためのツールです。デバイスのシステムメモリ、ビデオメモリなどの構成と、モデルのパラメータ数、精度ビット数などの情報を組み合わせることで、モデル実行の予測結果を提供します。このツールは、開発者や研究者がDeepSeekモデルをデプロイする際に適切なハードウェアリソースを選択する上で非常に重要であり、ハードウェア不足による実行問題を事前に回避するのに役立ちます。DeepSeekモデル自体は、自然言語処理などで広く利用されている高度な深層学習モデルであり、効率的で正確な特徴を持っています。このチェックツールを使用することで、ユーザーはDeepSeekモデルをより効果的にプロジェクト開発や研究に活用できます。
モデルトレーニングとデプロイメント
102.9K