%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Image Synthesis
Synthesys
Synthesys is an AI content generation platform that offers AI video, AI voice, and AI image generation services. By utilizing advanced artificial intelligence technology, it assists users in producing professional-grade content at a lower cost and with simpler operations. The product portfolio of Synthesys is based on the current market demand for high-quality, cost-effective content generation, with key advantages including hyper-realistic voice synthesis supporting multiple languages, the ability to produce high-definition videos without professional equipment, and a user-friendly interface design. The platform's pricing strategy includes free trials and various levels of paid services, aimed at meeting the content generation needs of businesses of all sizes.
Video Production
63.5K
Sana 1600M 1024px MultiLing
Sana is a text-to-image framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at remarkable speeds while maintaining robust text-image alignment, making it deployable on laptop GPUs. The Sana model is based on linear diffusion transformers, utilizing pre-trained text encoders and spatially compressed latent feature encoders, supporting Emoji, Chinese, and English inputs, as well as mixed prompts.
Image Generation
46.4K
Sana 1.6B
Sana-1.6B is an efficient high-resolution image synthesis model based on linear diffusion transformer technology, capable of generating high-quality images. Developed by NVIDIA Labs, it employs DC-AE technology and boasts a potential space of 32 times, allowing it to run on multiple GPUs and deliver powerful image generation capabilities. Renowned for its efficient image synthesis and high-quality output, Sana-1.6B is a significant technology in the image synthesis field.
Image Generation
52.4K

Sana
Sana is a text-to-image framework capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an incredibly fast speed while maintaining strong text-image alignment and can be deployed on laptop GPUs. The core design of Sana includes a deep compressed autoencoder, a linear diffusion transformer (DiT), a small language model as a decoder-only text encoder, and efficient training and sampling strategies. Compared to modern large diffusion models, Sana-0.6B is 20 times smaller and measures throughput over 100 times faster. Additionally, Sana-0.6B can be deployed on a 16GB laptop GPU, generating images at 1024×1024 resolution in less than 1 second. Sana makes low-cost content creation feasible.
Image Generation
52.4K
Onediffusion
OneDiffusion is a versatile, large-scale diffusion model capable of seamlessly supporting bidirectional image synthesis and understanding across a variety of tasks. The model is expected to release its code and checkpoints in early December. The significance of OneDiffusion lies in its ability to handle tasks related to image synthesis and understanding, marking an important advancement in the field of artificial intelligence, especially in image generation and recognition. Background information indicates that this is a collaborative project developed by multiple researchers, and the research outcomes have been published on arXiv.
Image Generation
52.2K
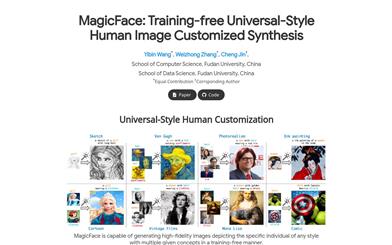
Magicface
MagicFace represents a technology for personalized portrait synthesis that operates without training, capable of generating high-fidelity portrait images based on multiple provided concepts. This technology integrates reference concept features at the pixel level into the generated images for personalized customization. It introduces a coarse-to-fine generation process consisting of two phases: semantic layout construction and concept feature injection, achieved through Reference-aware Self-Attention (RSA) and Region-grouped Blend Attention (RBA) mechanisms. This technology excels not only in portrait synthesis and multi-concept portrait customization but also extends to texture transfer, enhancing its versatility and practicality.
AI image generation
52.4K
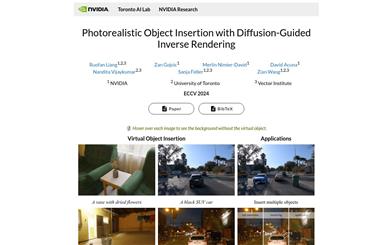
Dipir
DiPIR is a physics-based method co-developed by the Toronto AI Lab and NVIDIA Research, which recovers scene lighting from a single image, allowing virtual objects to be inserted realistically into both indoor and outdoor scenes. This technology not only optimizes material and tone mapping but also automatically adjusts to different environments to enhance the realism of the images.
AI image generation
51.6K
Chinese Picks
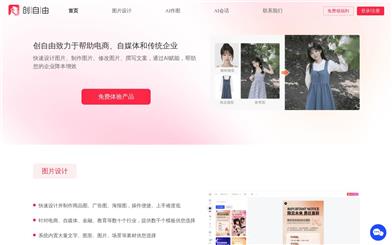
Chuangziyou
Chuangziyou is an online tool that leverages artificial intelligence technology to provide image design and copywriting services. It assists e-commerce, self-media, and traditional businesses in rapidly designing and creating product images, advertisements, posters, and more. Through built-in AI technologies such as AI model swapping, AI clothing fitting, and AI product image synthesis, it enables efficient image production and copywriting, reducing costs and enhancing efficiency.
AI design tools
58.8K
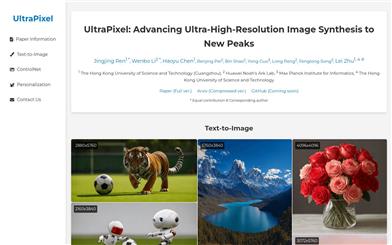
Ultrapixel
UltraPixel is an advanced ultra-high-definition image synthesis technology aimed at pushing image resolution to new heights. Developed jointly by institutions such as the Hong Kong University of Science and Technology (Guangzhou), Huawei Noah's Ark Laboratory, and the Max Planck Institute for Informatics, it excels in image synthesis, text-to-image conversion, and personalized customization. It can generate images with a resolution of up to 4096x4096, meeting the needs of professional image processing and visual art.
AI image generation
207.0K
Jector
Jector is an AI creation tool specializing in generating high-quality backgrounds for product photography. It simplifies the AI setup process, offers independent generation environment slots, and provides a node-based image generation history, allowing users to easily create and composite product images. Jector's key advantages include a user-friendly experience with no complex setup required, simple yet highly flexible generation options, automatic product compositing, and additional clearing and magnification features. It also offers unlimited saving and download functionality, enabling users to effortlessly create their own mood boards for product generation.
Image Generation
59.1K
Fresh Picks

Tryondiffusion
TryOnDiffusion is an innovative image synthesis technology that uses a combination of two UNets (Parallel-UNet) to simultaneously maintain clothing details and accommodate significant variations in body posture and shape within a single network. This technology addresses the limitations of previous methods in balancing detail preservation and pose adaptation, achieving industry-leading performance.
AI image generation
66.8K
Fresh Picks

Hyper SD
Hyper-SD is an innovative image synthesis framework that achieves efficient image synthesis through the advantages of trajectory segmentation consistency modeling and low-step inference. The framework combines the advantages of ODE trajectory preservation and reconstruction, while further enhancing performance through human feedback learning and strengthening low-step generation capabilities through score distillation. Hyper-SD achieves SOTA performance in 1 to 8 step inference steps, making it particularly suitable for application scenarios requiring fast and high-quality image generation.
AI image generation
99.9K
Magicclothing
MagicClothing is a novel network architecture based on Latent Diffusion Models (LDM) specifically designed for clothing-driven image synthesis tasks. It can generate customized character images wearing specific clothing based on text prompts while ensuring the preservation of clothing details and faithful representation of text prompts. The system achieves high image controllability through clothing feature extraction and self-attention fusion techniques, and can be combined with other technologies like ControlNet and IP-Adapter to enhance character diversity and controllability. Additionally, a matching point LPIPS (MP-LPIPS) evaluation metric has been developed to assess the consistency between the generated images and the original clothing.
AI image generation
142.7K
Masked Diffusion Transformer (MDT)
MDT explicitly enhances the ability of diffusion probability models (DPMs) to learn relationships between object parts in images by introducing a masked latent model scheme. MDT operates in the latent space during training, masking certain tokens, and then designs an asymmetrical diffusion transformer to predict masked tokens from unmasked tokens while maintaining the diffusion generation process. MDTv2 further improves the performance of MDT through more efficient macro network structures and training strategies.
AI image generation
58.2K
Trajectory Consistency Distillation (TCD)
TCD is a consistency distillation technique for text-to-image synthesis that leverages a Trajectory Consistency Function (TCF) and strategic random sampling (SSS) to reduce errors during the synthesis process. TCD significantly improves image quality at low NFE (noise-free energy) and maintains more detailed results than the teacher model at high NFE. TCD achieves superior generation quality at both low and high NFE without requiring additional discriminator or LPIPS supervision.
AI image generation
72.3K
Orthogonal Finetuning (OFT)
The study 'Controlling Text-to-Image Diffusion' explores how to effectively guide or control powerful text-to-image generation models for various downstream tasks. The orthogonal finetuning (OFT) method is proposed, which maintains the model's generative ability. OFT preserves the hypershell energy between neurons, preventing the model from collapsing. The authors consider two important fine-tuning tasks: subject-driven generation and controllable generation. Results show that the OFT method outperforms existing methods in terms of generation quality and convergence speed.
Image Generation
61.0K
Instantid
InstantID is a solution based on powerful diffusion models that enables personalized image processing of a single face image across various styles while ensuring high fidelity. We designed a novel IdentityNet that, through the application of strong semantic and weak spatial constraints, integrates face and landmark images with textual prompts to guide image generation. InstantID performs remarkably well in practical applications and can seamlessly integrate with popular pre-trained text-to-image diffusion models (such as SD1.5 and SDXL) as an adaptable plugin. Our code and pre-trained checkpoints will be provided at [URL].
AI image generation
620.2K

Score Distillation Sampling
Score Distillation Sampling (SDS) is a recently popular method that relies on image diffusion models to control optimization problems with text prompts. This paper conducts an in-depth analysis of the SDS loss function, identifies inherent problems in its formulation, and proposes an unexpected yet effective fix. Specifically, we decompose the loss into different factors and isolate the component that generates noisy gradients. In the original formulation, high text guidance is used to account for noise, leading to undesirable side effects. Instead, we train a shallow network to mimic the time-step-dependent denoising insufficiency of the image diffusion model, effectively decoupling it. We demonstrate the versatility and effectiveness of our novel loss formulation through multiple qualitative and quantitative experiments, including optimized image synthesis and editing, zero-shot image translation network training, and text-to-3D synthesis.
AI image generation
57.1K

Reconfusion
ReconFusion is a 3D reconstruction method that leverages diffusion priors to reconstruct real-world scenes from a limited number of photographs. It combines Neural Radiance Fields (NeRFs) with diffusion priors, enabling the synthesis of realistic geometry and textures at new camera poses beyond the input image set. This method is trained on diffusion priors with both limited-view and multi-view datasets, allowing it to synthesize realistic geometry and textures in unconstrained regions while preserving the appearance of the observed region. ReconFusion has been extensively evaluated on various real-world datasets, including forward and 360-degree scenes, demonstrating significant performance improvements.
AI image generation
60.2K
GAIA
GAIA aims to synthesize natural conversational videos from voice and a single portrait image. We introduce GAIA (Generative Avatar AI) which eliminates domain priors in conversational avatar generation. GAIA consists of two stages: 1) decomposing each frame into motion and appearance representations; 2) generating a motion sequence conditioned on voice and a reference portrait image. We collected a large-scale high-quality conversational avatar dataset and trained the model at different scales. Experimental results validate GAIA's superiority, scalability, and flexibility. The methods include variational autoencoders (VAEs) and diffusion models. Diffusion models are optimized to generate motion sequences conditioned on a voice sequence and random frames in a video clip. GAIA can be used for various applications such as controllable conversational avatar generation and text-guided avatar generation.
AI video generation
68.7K
Luosiallen LCM
Luosiallen/latent-consistency-model is a model for synthesizing high-resolution images. It uses a small number of inference steps to generate images with good consistency. The model supports custom input prompts and parameter adjustments, enabling the creation of realistic artwork and portraits.
AI image generation
237.9K
Runway Gen2
Gen-2 is a multi-modal artificial intelligence system that can generate new videos based on text, images, or video clips. It can apply the composition and style of images or textual prompts to the structure of source videos (Video to Video), or achieve this solely using text (Text to Video). It's like filming entirely new content without actually shooting anything. Gen-2 offers various modes to transform any image, video clip, or text prompt into captivating video works.
AI video generation
1.1M
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.6K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.9K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
45.3K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
44.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.2K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M