%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Audio-driven

Liteavatar
LiteAvatar is an audio-driven real-time 2D avatar generation model primarily designed for real-time chat scenarios. Through efficient speech recognition and viseme parameter prediction technology combined with a lightweight 2D face generation model, it achieves 30fps real-time inference using only CPU. Key advantages include efficient audio feature extraction, a lightweight model design, and mobile device-friendly support. This technology is suitable for real-time interactive virtual avatar generation scenarios such as online meetings and virtual live streaming. It was developed based on the need for real-time interaction and low hardware requirements. Currently, it is open-source and free, positioned as an efficient, low-resource-consuming real-time avatar generation solution.
Chatbot
62.9K

Syncanimation
SyncAnimation is an innovative audio-driven technology capable of real-time generation of highly realistic speaking avatars and upper body movements. By combining audio with synchronized pose and expression techniques, it addresses the shortcomings of traditional methods in terms of real-time performance and detail representation. This technology primarily targets application scenarios that require high-quality real-time animation generation, such as virtual streaming, online education, remote conferencing, and holds significant practical value. Its pricing and specific market positioning have yet to be determined.
Digital Human
50.8K
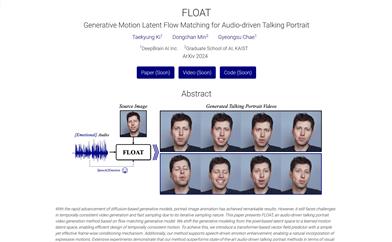
FLOAT
FLOAT is an audio-driven avatar video generation technique that utilizes a flow matching generative model, transitioning the generative modeling from pixel-based latent space to learned motion latent space, achieving temporally coherent motion design. This technology incorporates a transformer-based vector field predictor and features a straightforward yet effective per-frame conditioning mechanism. Additionally, FLOAT supports speech-driven emotional enhancement, allowing for the natural integration of expressive motion. Extensive experiments demonstrate that FLOAT outperforms existing audio-driven avatar methods in visual quality, motion fidelity, and efficiency.
Video Production
57.4K

Hallo2
Hallo2 is a facial animation technology based on a latent diffusion generative model, generating high-resolution, long-duration videos driven by audio. It expands upon Hallo's capabilities by incorporating several design improvements, including the generation of long videos, 4K resolution outputs, and enhanced expression control through textual prompts. Key advantages of Hallo2 include high-resolution output, long-duration stability, and enhanced control via textual prompts, making it significantly beneficial for generating diverse and rich portrait animation content.
AI image generation
68.7K
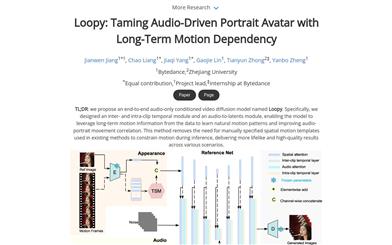
Loopy Model
Loopy is an end-to-end audio-driven video diffusion model that features time modules designed for cross-clip and intra-clip interactions, as well as an audio-to-latent representation module. This enables the model to leverage long-term motion information within the data to learn natural movement patterns and enhance the correlation between audio and portrait motion. This approach eliminates the need for manually specified spatial motion templates required by existing methods, achieving more realistic and high-quality results across various scenarios.
AI video generation
109.8K
Aniportrait
AniPortrait is a project that generates dynamic videos of speaking and singing faces based on audio and image input. It can create realistic facial animations synchronized with audio and static face images. Supports multiple languages and facial redrawing, head pose control. Features include audio-driven animation synthesis, facial reenactment, head pose control, support for self-driven and audio-driven video generation, high-quality animation generation, and flexible model and weight configuration.
AI video generation
701.6K

Vividtalk
VividTalk is a one-shot audio-driven avatar generation technique based on 3D mixed prior. It can generate realistic rap videos with rich expressions, natural head poses, and lip synchronization. This technique adopts a two-stage general framework to generate high-quality rap videos with all the above characteristics. Specifically, in the first stage, audio is mapped to a mesh by learning two types of motion (non-rigid facial motion and rigid head motion). For facial motion, a mixed shape and vertex representation is used as an intermediate representation to maximize the model's representational capability. For natural head motion, a novel learnable head posebook is proposed, and a two-stage training mechanism is adopted. In the second stage, a dual-branch motion VAE and a generator are proposed to convert the mesh into dense motion and synthesize high-quality videos frame by frame. Extensive experiments demonstrate that VividTalk can generate high-quality rap videos with lip synchronization and realistic enhancement, outperforming previous state-of-the-art works in both objective and subjective comparisons. The code for this technique will be publicly released after publication.
AI head image generation
134.4K
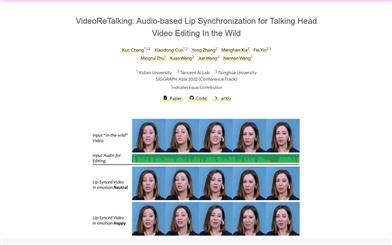
Videoretalking
VideoReTalking is a novel system that can edit real-world talking head videos to produce high-quality lip-sync output videos based on input audio, even with varying emotions. The system breaks down this goal into three consecutive tasks: (1) Generating facial videos with normalized expressions using an expression editing network; (2) Audio-driven lip-sync synchronization; (3) Facial enhancement to improve photorealism. Given a talking head video, we first use an expression editing network to modify the expressions of each frame according to a standardized expression template, resulting in a video with normalized expressions. This video is then input into a lip-sync network along with the given audio to generate a lip-sync video. Finally, we use an identity-aware facial enhancement network and post-processing to enhance the photorealism of the synthesized face. We utilize learning-based methods for all three steps, and all modules can be processed sequentially in a pipeline without any user intervention.
AI video editing
319.9K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M