%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


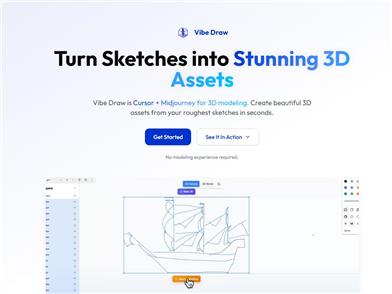
The Language Of Motion
Overview :
Developed by a research team at Stanford University, this multimodal language model framework aims to unify verbal and non-verbal communication within 3D human motion. The model can understand and generate multimodal data that includes text, voice, and actions, which is crucial for creating virtual characters capable of natural communication. It has broad applications in gaming, filmmaking, and virtual reality. Key advantages of this model include high flexibility, reduced training data requirements, and the ability to unlock new tasks such as editable gesture generation and emotion prediction from motions.
Target Users :
The target audience includes game developers, filmmakers, virtual reality content creators, and any professionals who need to create or understand 3D human motion. This product aids in the creation of more natural and realistic virtual characters by providing a unified model for verbal and non-verbal communication, enhancing user experience.
Use Cases
Game developers use this model to create natural movements and gestures for game characters, enhancing the immersive experience of the game.
In filmmaking, the model is utilized to automatically generate character actions based on the script, accelerating the animation production process.
In virtual reality applications, the model helps understand user actions and emotions, providing a more personalized interactive experience.
Features
- Multimodal language model: Capable of processing various input modalities like text, voice, and actions.
- Pre-training strategies: Innovative pre-training methods reduce the amount of training data needed while enhancing model performance.
- Synchronized gesture generation: The model can generate corresponding gestures based on voice input.
- Editable gesture generation: Users can edit and adjust the generated gestures.
- Text-to-motion generation: The model can create corresponding 3D human motions based on textual descriptions.
- Emotion understanding: The model can predict and comprehend emotions derived from motions.
- High performance: Achieves state-of-the-art performance in synchronized gesture generation tasks.
How to Use
1. Visit the official website or GitHub page of the model to learn about its basic information and functionalities.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Download and install the necessary software dependencies, such as a Python environment and a deep learning framework.
3. Prepare or gather the required training data, including text, voice, and motion data, following the provided documentation.
4. Train or fine-tune the model using the pre-training strategies provided.
5. Utilize the trained model to generate or edit 3D human motions, such as synchronized gesture generation or text-to-motion generation.
6. Edit and adjust the generated motions further as needed to meet specific application requirements.
7. Integrate the generated motions into games, films, or virtual reality projects to enhance content quality and user experience.


Featured AI Tools
English Picks

Luma AI
Luma AI is an AI-focused technology company that enables users to quickly generate 3D models using their phones through its innovative technology. Founded by a team with extensive experience in 3D computer vision, Luma AI's technology is based on Neural Radiance Fields, allowing for 3D scene modeling from a limited number of 2D images. Dream Machine is an AI model capable of directly generating high-quality, realistic videos from text and images. It is a highly scalable and efficient transformer model trained specifically for video, capable of generating physically accurate, consistent, and event-filled shots. Dream Machine represents the first step toward building a universal imagination engine, now accessible to everyone.
3D Modeling
3.6M
English Picks
Hedra
Hedra is an innovative creative lab dedicated to transforming foundational models into products that drive the next generation of human narrative technology. It offers a platform for users to create expressive and controllable character videos and build immersive virtual worlds that capture the imagination. Hedra's mission is to empower users to imagine worlds, characters, and stories by providing complete creative control.
AI Color Generation
826.1K