%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
使用场景
使用Diffree为风景照片添加飞鸟,增强画面生动性。
在产品宣传图中添加虚拟产品,进行市场测试。
在历史场景重建中,根据描述添加缺失的元素。
产品特色
文本到图像的模型,实现文本引导的对象添加
使用先进的图像修复技术生成的OABench数据集进行训练
具有独特的掩码预测模块,预测新对象的位置
能够保持添加对象时的背景一致性
支持迭代地在同一图像中添加多个对象
适用于多种自然场景中的对象添加
高成功率,保证添加对象的质量和相关性
使用教程
1. 访问Diffree的在线演示页面。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 阅读并理解Diffree的使用说明和要求。
3. 提供或输入希望添加到图像中的对象的文本描述。
4. 上传原始图像或选择已有的图像样本。
5. Diffree将根据文本描述和原始图像生成掩码和新对象的图像。
6. 检查生成的结果,确保新添加的对象符合预期。
7. 如有需要,进行迭代调整,直到满意为止。
8. 下载或直接使用生成的图像。

精选AI产品推荐
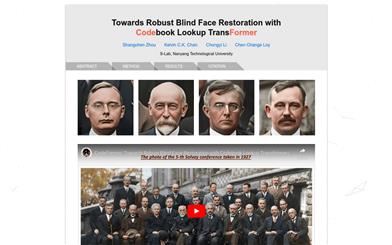
Codeformer
CodeFormer是一个基于 Transformer 的预测网络,用于图片马赛克恢复。通过学习离散码本和解码器,它能够减少恢复映射的不确定性,生成高质量人脸。它具有优秀的抗退化鲁棒性,适用于合成数据集和真实数据集。
AI图像修复
12.3M
SUPIR
SUPIR是一种开创性的图像修复方法,利用生成先验和模型扩展的力量。利用多模态技术和先进的生成先验,SUPIR在智能和逼真的图像修复方面取得了重大进展。作为SUPIR内的关键催化剂,模型扩展显著增强了其能力,并展示了图像修复的新潜力。我们收集了一个包含2000万高分辨率、高质量图像的数据集进行模型训练,每个图像都附有描述性文本注释。SUPIR能够根据文本提示修复图像,拓宽了其应用范围和潜力。此外,我们引入了负质量提示以进一步提高感知质量。我们还开发了一种修复引导采样方法,以抑制生成式修复中遇到的保真度问题。实验证明了SUPIR出色的修复效果及其通过文本提示操控修复的新能力。
AI图像修复
598.6K