%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Videopainter
VideoPainter 是一款基于深度学习的视频修复和编辑工具,采用预训练的扩散变换器模型,结合轻量级背景上下文编码器和 ID 重采样技术,能够实现高质量的视频修复和编辑。该技术的重要性在于它突破了传统视频修复方法在长度和复杂度上的限制,为视频创作者提供了一种高效、灵活的工具。产品目前处于研究阶段,暂未明确价格,主要面向视频编辑领域的专业用户和研究人员。
视频编辑
65.1K
优质新品
Melodyflow
MelodyFlow是一个基于文本控制的高保真音乐生成和编辑模型,它使用连续潜在表示序列,避免了离散表示的信息丢失问题。该模型基于扩散变换器架构,经过流匹配目标训练,能够生成和编辑多样化的高质量立体声样本,且具有文本描述的简单性。MelodyFlow还探索了一种新的正则化潜在反转方法,用于零样本测试时的文本引导编辑,并展示了其在多种音乐编辑提示中的优越性能。该模型在客观和主观指标上进行了评估,证明了其在标准文本到音乐基准测试中的质量与效率上与评估基线相当,并且在音乐编辑方面超越了以往的最先进技术。
音乐生成
53.8K
Diffree
Diffree是一个基于文本引导的图像修复模型,它能够通过文本描述来添加新对象到图像中,同时保持背景的一致性、空间适宜性和对象的相关性和质量。该模型通过训练在OABench数据集上,使用稳定扩散模型和额外的掩码预测模块,能够独特地预测新对象的位置,实现仅通过文本指导的对象添加。
AI图像编辑
94.9K
优质新品
Clothedreamer
ClotheDreamer是一个基于3D高斯的文本引导服装生成模型,能够从文本描述生成高保真的、可穿戴的3D服装资产。它采用了一种新颖的表示方法Disentangled Clothe Gaussian Splatting (DCGS),允许服装和人体分别进行优化。该技术通过双向Score Distillation Sampling (SDS)来提高服装和人体渲染的质量,并支持自定义服装模板输入。ClotheDreamer的合成3D服装可以轻松应用于虚拟试穿,并支持物理精确的动画。
AI服装生成工具
77.6K
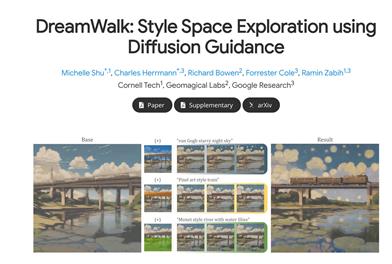
Dreamwalk
DreamWalk是一种基于扩散指引的文本感知图像生成方法,可对图像的风格和内容进行细粒度控制,无需对扩散模型进行微调或修改内部层。支持多种风格插值和空间变化的引导函数,可广泛应用于各种扩散模型。
AI图像生成
69.6K
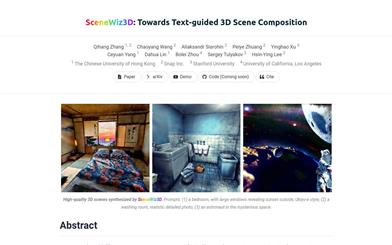
Scenewiz3d
SceneWiz3D是一种新颖的方法,可以从文本中合成高保真的3D场景。它采用混合的3D表示,对对象采用显式表示,对场景采用隐式表示。用户可以通过传统的文本到3D方法或自行提供对象来生成对象。为了配置场景布局并自动放置对象,我们在优化过程中应用了粒子群优化技术。此外,在文本到场景的情况下,对于场景的某些部分(例如角落、遮挡),很难获得多视角监督,导致几何形状劣质。为了缓解这种监督缺失,我们引入了RGBD全景扩散模型作为额外先验,从而实现了高质量的几何形状。广泛的评估支持我们的方法实现了比以前的方法更高的质量,可以生成详细且视角一致的3D场景。
AI图像生成
50.5K
RERENDER A VIDEO
RERENDER A VIDEO是一种新颖的零样本文本引导的视频到视频翻译框架,用于将图像模型应用于视频领域。该框架包括两个部分:关键帧翻译和完整视频翻译。第一部分使用适应性扩散模型生成关键帧,并应用分层跨帧约束来确保形状、纹理和颜色的一致性。第二部分通过时间感知的补丁匹配和帧混合将关键帧传播到其他帧。我们的框架以低成本实现了全局风格和局部纹理的时间一致性(无需重新训练或优化)。该适应性与现有的图像扩散技术兼容,使我们的框架能够利用它们,例如使用LoRA自定义特定主题,并使用ControlNet引入额外的空间引导。大量实验证明了我们提出的框架在呈现高质量和时间一致性视频方面的有效性。
视频编辑
66.0K
Magicavatar
MagicAvatar是一个多模态框架,能够将各种输入模式(文本、视频和音频)转换为运动信号,从而生成/动画化头像。它可以通过简单的文本提示创建头像,也可以根据给定的源视频创建遵循给定运动的头像。此外,它还可以动画化特定主题的头像。MagicAvatar的优势在于它能够将多种输入模式结合起来,生成高质量的头像和动画。
AI头像生成
65.1K
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.3K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M