%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
使用場景
使用Diffree為風景照片添加飛鳥,增強畫面生動性。
在產品宣傳圖中添加虛擬產品,進行市場測試。
在歷史場景重建中,根據描述添加缺失的元素。
產品特色
文本到圖像的模型,實現文本引導的對象添加
使用先進的圖像修復技術生成的OABench數據集進行訓練
具有獨特的掩碼預測模塊,預測新對象的位置
能夠保持添加對象時的背景一致性
支持迭代地在同一圖像中添加多個對象
適用於多種自然場景中的對象添加
高成功率,保證添加對象的質量和相關性
使用教程
1. 訪問Diffree的在線演示頁面。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 閱讀並理解Diffree的使用說明和要求。
3. 提供或輸入希望添加到圖像中的對象的文本描述。
4. 上傳原始圖像或選擇已有的圖像樣本。
5. Diffree將根據文本描述和原始圖像生成掩碼和新對象的圖像。
6. 檢查生成的結果,確保新添加的對象符合預期。
7. 如有需要,進行迭代調整,直到滿意為止。
8. 下載或直接使用生成的圖像。

精選AI產品推薦
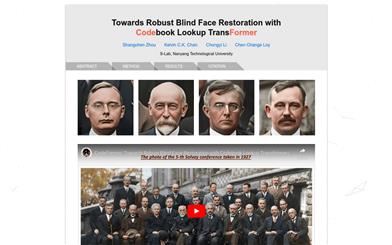
Codeformer
CodeFormer是一個基於 Transformer 的預測網絡,用於圖片馬賽克恢復。通過學習離散碼本和解碼器,它能夠減少恢復映射的不確定性,生成高質量人臉。它具有優秀的抗退化魯棒性,適用於合成數據集和真實數據集。
AI圖像修復
12.3M
SUPIR
SUPIR是一種開創性的圖像修復方法,利用生成先驗和模型擴展的力量。利用多模態技術和先進的生成先驗,SUPIR在智能和逼真的圖像修復方面取得了重大進展。作為SUPIR內的關鍵催化劑,模型擴展顯著增強了其能力,並展示了圖像修復的新潛力。我們收集了一個包含2000萬高分辨率、高質量圖像的數據集進行模型訓練,每個圖像都附有描述性文本註釋。SUPIR能夠根據文本提示修復圖像,拓寬了其應用範圍和潛力。此外,我們引入了負質量提示以進一步提高感知質量。我們還開發了一種修復引導採樣方法,以抑制生成式修復中遇到的保真度問題。實驗證明了SUPIR出色的修復效果及其通過文本提示操控修復的新能力。
AI圖像修復
596.7K