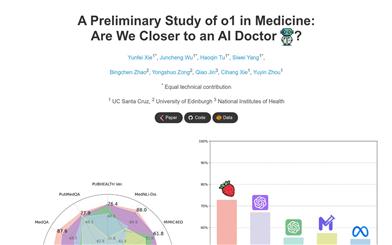
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Hear
簡介 :
Health Acoustic Representations (HeAR) 是由谷歌研究團隊開發的生物聲學基礎模型,旨在通過分析人體發出的聲音,如咳嗽聲,來識別疾病的早期跡象。該模型經過了3億條音頻數據的訓練,特別針對咳嗽聲音使用了約1億條數據。HeAR 能夠識別與健康相關的聲音模式,為醫療音頻分析提供了強大的基礎。HeAR 模型在多種任務中的表現優於其他模型,並在不同麥克風上具有更好的泛化能力。此外,使用 HeAR 訓練的模型在訓練數據較少的情況下也能達到高性能,這對於數據稀缺的醫療研究領域至關重要。HeAR 目前已向研究人員開放,以加速開發定製的生物聲學模型,減少數據、設置和計算的需求。
需求人群 :
HeAR 模型適用於醫療研究人員和開發人員,特別是那些專注於呼吸健康和疾病早期檢測的專業人士。它能夠幫助他們利用智能手機的麥克風,通過分析咳嗽聲音來識別疾病的早期跡象,從而提高診斷的準確性和便捷性。
使用場景
Salcit Technologies 使用 HeAR 模型來增強其 Swaasa® 產品,通過分析咳嗽聲音來評估肺健康,並研究如何提高結核病的早期檢測能力。
HeAR 模型可以用於改善全球範圍內的結核病診斷,尤其是在醫療資源有限的地區。
The StopTB Partnership 支持使用 HeAR 模型,以實現到2030年結束結核病的目標。
產品特色
識別咳嗽聲音中的疾病模式
在多種任務中表現優於其他模型
在不同麥克風上具有更好的泛化能力
使用較少訓練數據達到高性能
加速開發定製的生物聲學模型
減少數據、設置和計算的需求
支持對特定疾病和人群的研究
使用教程
1. 研究人員可以請求訪問 HeAR API,開始探索模型的功能。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 使用 HeAR 模型分析咳嗽聲音或其他生物聲學數據。
3. 根據模型的分析結果,識別出可能的疾病跡象。
4. 進一步研究和驗證模型的準確性和可靠性。
5. 將 HeAR 模型集成到現有的醫療健康應用中,以提高疾病檢測的效率。
6. 根據研究結果,優化和調整模型,以適應不同的疾病檢測需求。