%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
產品特色
將文字轉換為語音
提供多種語言和聲音選擇
調整語速和音量
流量來源
| 直接訪問 | 73.25% | 外鏈引薦 | 16.06% | 郵件 | 0.04% |
| 自然搜索 | 4.95% | 社交媒體 | 5.43% | 展示廣告 | 0.23% |
最新流量情況
| 月訪問量 | 26.21k |
| 平均訪問時長 | 44.83 |
| 每次訪問頁數 | 1.32 |
| 跳出率 | 58.15% |
總流量趨勢圖
地理流量分佈情況
| 月訪問量 | 26.21k |
| Ethiopia | 70.03% |
| United States | 4.28% |
| Germany | 3.50% |
| Spain | 2.89% |
| Russia | 2.41% |
地理流量分佈全球圖
同類開源產品

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 是一個 600 百萬參數的自動語音識別(ASR)模型,旨在實現高質量的英語轉錄,具有準確的時間戳預測和自動標點符號、大小寫支持。該模型基於 FastConformer 架構,能夠高效地處理長達 24 分鐘的音頻片段,適合開發者、研究人員和各行業應用。
語音識別

Kimi Audio
Kimi-Audio 是一個先進的開源音頻基礎模型,旨在處理多種音頻處理任務,如語音識別和音頻對話。該模型在超過 1300 萬小時的多樣化音頻數據和文本數據上進行了大規模預訓練,具有強大的音頻推理和語言理解能力。它的主要優點包括優秀的性能和靈活性,適合研究人員和開發者進行音頻相關的研究與開發。
語音識別
國外精選
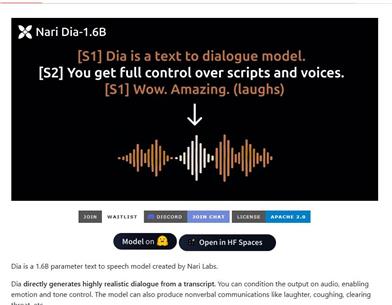
Dia AI
Dia 是一個由 Nari Labs 開發的文本到語音(TTS)模型,具有 1.6 億參數,能夠直接從文本生成高度逼真的對話。該模型支持情感和語調控制,並能夠生成非言語交流,如笑聲和咳嗽。它的預訓練模型權重託管在 Hugging Face 上,適用於英語生成。此產品對於研究和教育用途至關重要,能夠推動對話生成技術的發展。
文本轉聲音

Orpheus TTS
Orpheus TTS 是一個基於 Llama-3b 模型的開源文本轉語音系統,旨在提供更加自然的人類語音合成。它具備較強的語音克隆能力和情感表達能力,適合各種即時應用場景。該產品是免費的,旨在為開發者和研究者提供便捷的語音合成工具。
文本轉聲音

Spark TTS
Spark-TTS 是一種基於大語言模型的高效文本到語音合成模型,具有單流解耦語音令牌的特性。它利用大語言模型的強大能力,直接從代碼預測的音頻進行重建,省略了額外的聲學特徵生成模型,從而提高了效率並降低了複雜性。該模型支持零樣本文本到語音合成,能夠跨語言和代碼切換場景,非常適合需要高自然度和準確性的語音合成應用。它還支持虛擬語音創建,用戶可以通過調整參數(如性別、音高和語速)來生成不同的語音。該模型的背景是為了解決傳統語音合成系統中效率低下和複雜性高的問題,旨在為研究和生產提供高效、靈活且強大的解決方案。目前,該模型主要面向學術研究和合法應用,如個性化語音合成、輔助技術和語言研究等。
文本轉聲音

Llasa
Llasa是一個基於Llama框架的文本到語音(TTS)基礎模型,專為大規模語音合成任務設計。該模型利用16萬小時的標記化語音數據進行訓練,具備高效的語言生成能力和多語言支持。其主要優點包括強大的語音合成能力、低推理成本和靈活的框架兼容性。該模型適用於教育、娛樂和商業場景,能夠為用戶提供高質量的語音合成解決方案。目前該模型在Hugging Face上免費提供,旨在推動語音合成技術的發展和應用。
文本轉聲音

Indextts
IndexTTS 是一種基於 GPT 風格的文本到語音(TTS)模型,主要基於 XTTS 和 Tortoise 進行開發。它能夠通過拼音糾正漢字發音,並通過標點符號控制停頓。該系統在中文場景中引入了字符-拼音混合建模方法,顯著提高了訓練穩定性、音色相似性和音質。此外,它還集成了 BigVGAN2 來優化音頻質量。該模型在數萬小時的數據上進行訓練,性能超越了當前流行的 TTS 系統,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 適用於需要高質量語音合成的場景,如語音助手、有聲讀物等,其開源性質也使其適合學術研究和商業應用。
文本轉聲音

Step Audio
Step-Audio是首個生產級開源智能語音交互框架,整合了語音理解與生成能力,支持多語言對話、情感語調、方言、語速和韻律風格控制。其核心技術包括130B參數多模態模型、生成式數據引擎、精細語音控制和增強智能。該框架通過開源模型和工具,推動智能語音交互技術的發展,適用於多種語音應用場景。
語音識別

Fireredasr AED L
FireRedASR-AED-L 是一個開源的工業級自動語音識別模型,專為滿足高效率和高性能的語音識別需求而設計。該模型採用基於注意力的編碼器-解碼器架構,支持普通話、中文方言和英語等多種語言。它在公共普通話語音識別基準測試中達到了新的最高水平,並且在歌唱歌詞識別方面表現出色。該模型的主要優點包括高性能、低延遲和廣泛的適用性,適用於各種語音交互場景。其開源特性使得開發者可以自由地使用和修改代碼,進一步推動語音識別技術的發展。
語音識別
替代品
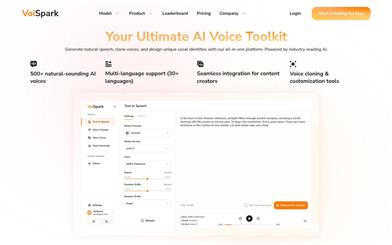
Voispark
VoiSpark是一個AI語音生成平臺,能生成逼真的文本轉語音,克隆聲音,併為視頻、播客等定製獨特AI聲音。該平臺具有100%免費試用。
文本轉聲音

Echopod
EchoPod是一個利用人工智能將文章、博客和故事轉換為專業品質播客的平臺。其重要性在於可以幫助用戶擴大影響力,提升受眾參與度,無需錄音室即可實現播客製作。EchoPod為Adformatie的數字媒體未來打開了無限可能。
文本轉聲音
Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 是一個 600 百萬參數的自動語音識別(ASR)模型,旨在實現高質量的英語轉錄,具有準確的時間戳預測和自動標點符號、大小寫支持。該模型基於 FastConformer 架構,能夠高效地處理長達 24 分鐘的音頻片段,適合開發者、研究人員和各行業應用。
語音識別
Kimi Audio
Kimi-Audio 是一個先進的開源音頻基礎模型,旨在處理多種音頻處理任務,如語音識別和音頻對話。該模型在超過 1300 萬小時的多樣化音頻數據和文本數據上進行了大規模預訓練,具有強大的音頻推理和語言理解能力。它的主要優點包括優秀的性能和靈活性,適合研究人員和開發者進行音頻相關的研究與開發。
語音識別
國外精選
Dia AI
Dia 是一個由 Nari Labs 開發的文本到語音(TTS)模型,具有 1.6 億參數,能夠直接從文本生成高度逼真的對話。該模型支持情感和語調控制,並能夠生成非言語交流,如笑聲和咳嗽。它的預訓練模型權重託管在 Hugging Face 上,適用於英語生成。此產品對於研究和教育用途至關重要,能夠推動對話生成技術的發展。
文本轉聲音

Amazon Nova Sonic
Amazon Nova Sonic 是一款前沿的基礎模型,能夠整合語音理解和生成,提升人機對話的自然流暢度。該模型克服了傳統語音應用中的複雜性,通過統一的架構實現更深層次的交流理解,適用於多個行業的 AI 應用,具有重要的商業價值。隨著人工智能技術的不斷發展,Nova Sonic 將為客戶提供更好的語音交互體驗,提升服務效率。
語音識別
Text To Bark
Text to Bark 是由 ElevenLabs 開發的首個 AI 驅動的文本轉語音模型,旨在幫助人們與狗狗進行更有效的溝通。該技術不僅展現了極高的語音合成質量,還能以自然的方式模擬狗的聲音,創造出適合狗狗理解的交流方式。這個創新產品的推出,將人與寵物之間的互動提升到了一個新的高度,讓主人與愛犬之間的交流更加有趣和有效。用戶可以通過簡單的文本輸入,生成相應的 “狗語”,從而更好地理解和與寵物互動。
文本轉聲音
Podcastle AI Voices
這是一個強大的文本轉語音生成器,擁有超過 1000 種高質量的 AI 語音。適合各種使用場景,如播客、教育和商業內容創作。用戶可以利用該平臺生成清晰、自然的語音內容,支持語音克隆和音頻視頻編輯,價格合理,每月僅需 39.99 美元,適合個人和企業使用。
文本轉聲音
Orpheus TTS
Orpheus TTS 是一個基於 Llama-3b 模型的開源文本轉語音系統,旨在提供更加自然的人類語音合成。它具備較強的語音克隆能力和情感表達能力,適合各種即時應用場景。該產品是免費的,旨在為開發者和研究者提供便捷的語音合成工具。
文本轉聲音