%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
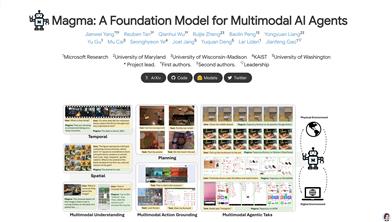
Magma
Magmaは、Microsoft Researchチームが開発した多モーダル基礎モデルです。視覚、言語、動作を組み合わせることで、複雑なタスクの計画と実行を目指しています。大規模な視覚言語データによって事前学習されており、言語理解、空間認識、動作計画能力を備え、UIナビゲーションやロボット操作などのタスクで優れた性能を発揮します。このモデルは、多モーダルAIエージェントタスクに強力な基礎フレームワークを提供し、幅広い応用が期待されます。
AI
46.1K
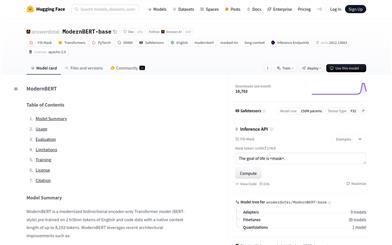
Modernbert Base
ModernBERT-baseは、2兆個の英語とコードデータで事前学習された最新の双方向エンコーダーTransformerモデルです。最大8192トークンのコンテキストをネイティブにサポートしています。Rotary Positional Embeddings (RoPE)、Local-Global Alternating Attention、Unpaddingなどの最新のアーキテクチャ改良を採用することで、長文テキスト処理タスクにおいて優れた性能を発揮します。ModernBERT-baseは、検索、分類、大規模コーパスにおける意味検索など、長文書を処理する必要があるタスクに適しています。モデルの訓練データは主に英語とコードであるため、他の言語での性能は低下する可能性があります。
AIモデル
47.5K
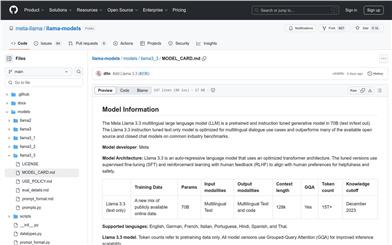
Meta Llama 3.3
Meta Llama 3.3は、70Bパラメーターの多言語大規模事前学習言語モデル(LLM)であり、多言語対話ユースケース向けに最適化されており、多くの既存のオープンソースおよびクローズドなチャットモデルを上回る性能を一般的な業界ベンチマークテストで示しています。このモデルは最適化されたTransformerアーキテクチャを採用し、教師ありファインチューニング(SFT)と人間からのフィードバックに基づく強化学習(RLHF)を使用して、人間の有用性と安全性の嗜好に合致するように設計されています。
チャットボット
47.2K
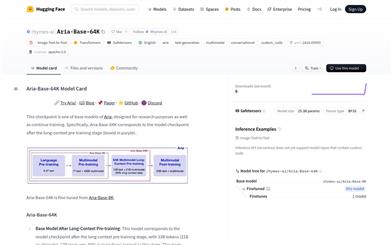
Aria Base 64K
Aria-Base-64KはAriaシリーズの基本モデルの一つであり、研究目的と継続的なトレーニングのために設計されています。このモデルは、長文テキストの事前学習段階を経て生成され、330億トークン(多モーダル210億、言語120億、69%が長文テキスト)のトレーニングを受けています。長尺動画質問応答データセットまたは長尺文書質問応答データセットの継続的な事前学習または微調整に適しており、リソースが限られた場合でも、短い指示による微調整データセットを用いて後続のトレーニングを行い、長文テキスト質問応答シーンに移行させることができます。このモデルは最大250枚の高解像度画像または最大500枚の中解像度画像を理解し、言語および多モーダルシーンにおいて強力な基本性能を維持します。
AIモデル
43.3K
Vitlp
ViTLPは、ドキュメントインテリジェンス処理の効率と精度向上を目指した、視覚誘導型テキストレイアウト生成事前学習モデルです。OCRによるテキスト位置特定と認識機能を統合し、ドキュメント画像上での迅速かつ正確なテキスト検出と認識を実現します。計算資源と事前学習データセット規模の制約下において、ViTLP-medium(3億8000万パラメータ)という事前学習済みバージョンは、モデル性能と推論速度?メモリ使用量の最適化のバランスを取ったソリューションを提供します。Nvidia 4090を用いたViTLPの推論速度は、1ページのドキュメント画像処理に通常5~10秒かかり、多くのOCRエンジンと比較して競争力があります。
文書
58.8K
Qwen2.5 Coder 32B Instruct GPTQ Int4
Qwen2.5-Coder-32B-Instruct-GPTQ-Int4は、Qwen2.5をベースとした32億5千万パラメーターのコード生成大規模言語モデルであり、長文処理に対応し、最大128Kトークンをサポートします。コード生成、コード推論、コード修正において顕著な性能向上を実現しており、現在オープンソースのコード言語モデルの中でもトップクラスです。コーディング能力の強化に加え、数学や一般能力においても優れた性能を維持しています。
コード推論
45.5K
Qwen2.5 Coder 0.5B Instruct
Qwen2.5-Coderは、コード生成、コード推論、コード修正に特化したQwen大規模言語モデルの最新シリーズです。強力なQwen2.5をベースに、ソースコード、テキストコードベース、合成データなどを含む5.5兆トークンに拡張トレーニングを行い、Qwen2.5-Coder-32Bは現在最先端のオープンソースコードLLMとなり、そのコーディング能力はGPT-4oに匹敵します。このモデルはコーディング能力を向上させただけでなく、数学や一般能力における優位性も維持しており、コードエージェントなどの実用アプリケーションに、より包括的な基盤を提供します。
コードアシスタント
45.3K
Qwen2.5 Coder 3B
Qwen2.5-Coder-3Bは、Qwen2.5-Coderシリーズの大規模言語モデルであり、コード生成、推論、修正に特化しています。強力なQwen2.5をベースに、ソースコード、テキストコードベース、合成データなどを含む5.5兆トークンで追加トレーニングを行い、コード生成、推論、修正において著しい改善を実現しました。Qwen2.5-Coder-32Bは現在最先端のオープンソースコード大規模言語モデルであり、そのコーディング能力はGPT-4oに匹敵します。さらに、Qwen2.5-Coder-3Bはコードエージェントなど、現実世界のアプリケーションに包括的な基盤を提供し、コーディング能力の向上に加え、数学や一般的な能力における優位性も維持しています。
コードアシスタント
62.1K
Qwen2.5 Coder 技術レポート
Qwen2.5-Coderシリーズは、Qwen2.5アーキテクチャに基づくコード特化型モデルで、Qwen2.5-Coder-1.5BとQwen2.5-Coder-7Bの2つのモデルが含まれています。これらのモデルは、5.5兆トークンを超える大規模なコーパスで継続的に事前学習されており、精緻なデータクレンジング、拡張可能な合成データ生成、バランスの取れたデータミックスによって、汎用性を維持しながら、印象的なコード生成能力を発揮します。Qwen2.5-Coderは、コード生成、補完、推論、修正を含むさまざまなコード関連タスクにおいて、10以上のベンチマークテストで最先端の性能を達成し、同規模の他の大規模モデルを常に凌駕しています。このシリーズの公開は、コードインテリジェンス研究の限界を押し広げるだけでなく、そのライセンスによって、現実世界のアプリケーションにおけるより広範な採用を促進します。
コードアシスタント
62.7K
Aya Expanse 8b
Aya Expanseは、高度な多言語能力を備えたオープンウェイトの研究モデルです。高性能な事前学習モデルとCohere For AIによる1年間の研究成果(データアービトラージ、多言語的嗜好トレーニング、安全調整、モデルマージングを含む)を組み合わせることに重点を置いています。このモデルは、アラビア語、中国語(簡体字と繁体字)、チェコ語、オランダ語、英語、フランス語、ドイツ語、ギリシャ語、ヘブライ語、ヒンディー語、インドネシア語、イタリア語、日本語、韓国語、ペルシャ語、ポーランド語、ポルトガル語、ルーマニア語、ロシア語、スペイン語、トルコ語、ウクライナ語、ベトナム語など、23言語に対応した強力な多言語大規模言語モデルです。
AIモデル
46.9K
Olmoe
OLMoEは、1.3億の活性パラメーターと6.9億の総パラメーターを持つ、完全にオープンソースの最先端エキスパート混合モデルです。モデルのデータ、コード、ログはすべて公開されています。論文『OLMoE: Open Mixture-of-Experts Language Models』の全リソースの概要を提供しています。このモデルは、事前学習、微調整、適応、評価において重要な役割を果たし、自然言語処理分野の大きな進歩です。
AIモデル
44.4K
Opencity
OpenCityは、交通予測分野に特化したオープンソースの時空間基礎モデルです。Transformerアーキテクチャとグラフニューラルネットワークを統合することで、交通データにおける複雑な時空間依存関係を効果的に捉え、標準化し、様々な都市環境へのゼロショット汎化を実現します。大規模かつ異種混合の交通データセットで事前学習を行い、豊富で汎化可能な表現を獲得しており、様々な交通予測シナリオにシームレスに適用可能です。
AIモデル
43.6K
Meta Llama 3.1 405B
Meta Llama 3.1-405Bは、Metaが開発した大規模多言語事前学習済み言語モデルシリーズで、8B、70B、405Bの3種類の規模のモデルが含まれています。これらのモデルは最適化されたトランスフォーマーアーキテクチャを採用し、教師ありファインチューニング(SFT)と強化学習による人間のフィードバック(RLHF)を用いて、人間にとって有益で安全な特性に合わせて調整されています。Llama 3.1モデルは、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語など、複数の言語をサポートしています。このモデルは、様々な自然言語生成タスクにおいて優れたパフォーマンスを発揮し、業界ベンチマークテストにおいて、多くの既存のオープンソースおよびクローズドソースのチャットモデルを上回っています。
AIモデル
94.9K
Vitmatte
ViTMatteは、事前学習済み純粋ビジョン変換器(Plain Vision Transformers、ViTs)に基づく画像切り抜きシステムです。混合アテンションメカニズムと畳み込みネックを組み合わせることで、性能と計算量のバランスを最適化し、さらに詳細捕捉モジュールを導入することで、切り抜きに必要な詳細情報を補完します。ViTMatteは、簡潔な適応によりViTの画像切り抜き分野における可能性を解き放った最初の取り組みであり、事前学習戦略、簡潔なアーキテクチャ設計、柔軟な推論戦略といったViTの利点を継承しています。最も一般的に使用されている画像切り抜きベンチマークテストであるComposition-1kとDistinctions-646において、ViTMatteは最先端の性能を達成し、従来の手法を大きく上回っています。
AI画像編集
56.9K
高品質新製品
Index 1.9B Pure
Index-1.9B-PureはIndexシリーズモデルの軽量版であり、テキスト生成のために設計されています。2.8Tの中英単語データで事前学習されており、同等のモデルと比較して、複数の評価基準で優れた性能を示しています。このモデルは、ベンチマークへの指示の影響を検証するために、すべての指示関連データを特別に除外しており、高品質なテキスト生成が必要な分野に適しています。
AIコンテンツ生成
49.1K
高品質新製品
Index 1.9B Chat
Index-1.9B-Chatは、19億パラメーターに基づく対話生成モデルです。SFTとDPOアライメント技術を用い、RAGを組み合わせることで、少ない例示によるロールプレイングのカスタマイズを実現し、高い対話性とカスタマイズ性を備えています。2.8Tの中英を主としたコーパスで事前学習されており、複数の評価基準において優れた性能を示しています。
AI会話機械人間
53.8K
高品質新製品
雅意情報抽出大規模モデル
雅意情報抽出大規模モデル(YAYI-UIE)は、中科聞歌アルゴリズムチームによって開発されたモデルです。百万件規模の人工構築による高品質な情報抽出データを用いて命令微調整が行われています。命名エンティティ認識(NER)、関係抽出(RE)、イベント抽出(EE)といった情報抽出タスクを統一的に学習しており、汎用、セキュリティ、金融、バイオ、医療、ビジネスなど、様々なシーンにおける構造化抽出に対応しています。本モデルのオープンソース化は、中国語事前学習大規模モデルのオープンソースコミュニティの発展を促進し、オープンソースによる共同開発を通じて雅意大規模モデルエコシステムを構築することを目的としています。
AIモデル
69.6K

Qwen2
Qwen2は、事前学習と指示調整が施された一連のモデルであり、英語や中国語を含む最大27の言語をサポートしています。これらのモデルは複数のベンチマークテストで優れたパフォーマンスを示しており、特にコーディングと数学において顕著な向上が見られます。Qwen2モデルは最大128Kトークンのコンテキスト長に対応し、長文処理タスクに適しています。さらに、Qwen2-72B-Instructモデルは、安全性においてGPT-4と同等であり、Mistral-8x22Bモデルを大きく上回っています。
AIモデル
156.2K
海外精選
GLM 4V 9B
GLM-4V-9Bは、智譜AIが発表した最新世代の事前学習モデルです。1120×1120の高解像度での中国語と英語の双方向多段階対話、および画像認識能力をサポートします。マルチモーダル評価において、GLM-4V-9BはGPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max、Claude 3 Opusを上回る優れた性能を示しました。
AIモデル
75.6K
高品質新製品
GLM 4 9B Chat 1M
GLM-4-9B-Chat-1Mは、智譜AIが発表した新世代の事前学習モデルであり、GLM-4シリーズのオープンソース版です。意味、数学、推論、コード、知識など、多様なデータセットの評価において高い性能を示しています。このモデルは複数回にわたる対話に対応するだけでなく、ウェブブラウジング、コード実行、カスタムツールの呼び出し、長文推論などの高度な機能も備えています。日本語、韓国語、ドイツ語を含む26言語に対応しており、特に1Mコンテキスト長のモデルバージョンも提供しています。大量のデータや多言語環境の処理が必要な開発者や研究者にとって最適です。
AIモデル
56.0K
高品質新製品
GLM 4 9B Chat
GLM-4-9B-Chatは、智譜AIが発表した次世代事前学習モデルGLM-4シリーズのオープンソース版です。多様な対話、ウェブ閲覧、コード実行、カスタムツール呼び出し、長文推論といった高度な機能を備えています。日本語、韓国語、ドイツ語を含む26言語に対応しており、1Mコンテキスト長のモデルも提供しています。
AIモデル
60.2K
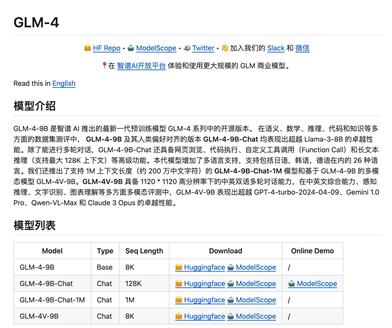
GLM 4シリーズ
GLM-4シリーズは、智譜AIが開発した次世代の事前学習済みモデルであり、GLM-4-9B、GLM-4-9B-Chat、GLM-4-9B-Chat-1M、GLM-4V-9Bが含まれます。これらのモデルは、意味理解、数学的推論、コード実行において優れた性能を発揮し、最大26言語に対応しており、ウェブ閲覧やコード実行などの高度な機能を備えています。GLM-4V-9Bモデルは、高解像度の画像認識能力も備えており、マルチモーダルなアプリケーションに適しています。
AIモデル
59.9K
Cogvlm2
CogVLM2は、清華大学チームによって開発された第二世代の多モーダル事前学習対話モデルです。複数のベンチマークテストで顕著な改善を示しており、8Kのコンテンツ長と1344×1344の高解像度画像に対応しています。CogVLM2シリーズモデルは、中国語と英語に対応したオープンソース版を提供しており、一部の非オープンソースモデルに匹敵する性能を備えています。
AIモデル
65.4K

HPT
HPT(Hyper-Pretrained Transformers)は、HyperGAI研究チームが開発した新型のマルチモーダル大規模言語モデルフレームワークです。大規模なマルチモーダル基盤モデルを効率的かつ拡張的に学習でき、テキスト、画像、ビデオなど、多様な入力モダリティを理解します。HPTフレームワークは、ゼロから学習することも、既存の事前学習済みビジュアルエンコーダや大規模言語モデルを効率的に適用することも可能です。
AIモデル
73.1K
Spactor T5
SpacTorは、(1) 段落破壊(SC)とトークン置換検出(RTD)を組み合わせた混合目標、(2) 最初のτ回の反復で混合目標を最適化し、その後標準的なSC損失に移行する二段階学習課程、を含む新しい訓練手法です。エンコーダ-デコーダアーキテクチャ(T5)を用いて様々なNLPタスクで実験した結果、SpacTor-T5は、下流タスクにおける性能は標準的なSC事前学習と同等でありながら、事前学習の反復回数を50%、総FLOPsを40%削減しました。さらに、同じ計算予算下では、SpacTorは下流ベンチマークの性能を大幅に向上させることが分かりました。
AIモデル
45.8K
Tinyllama
TinyLlamaプロジェクトは、3兆トークンで11億パラメーターのLlamaモデルを事前学習することを目指しています。適切な最適化により、「わずか」90日間で16台のA100-40G GPUを使用して学習を完了することができました。学習は2023年9月1日に開始されました。Llama 2と全く同じアーキテクチャとトークナイザーを採用しています。そのため、Llamaをベースとした多くのオープンソースプロジェクトでTinyLlamaを使用できます。さらに、TinyLlamaはパラメーター数が11億とコンパクトなため、計算資源やメモリ容量が限られたアプリケーションにも対応できます。
AIモデル
69.6K
Google Vision Transformer
Google Vision Transformerは、Transformerエンコーダーに基づく画像認識モデルです。大規模な画像データを用いて事前学習されており、画像分類などのタスクに使用できます。ImageNet-21kデータセットで事前学習され、ImageNetデータセットで微調整されており、優れた画像特徴抽出能力を備えています。このモデルは、画像を固定サイズの画像パッチに分割し、それらのパッチを線形に埋め込むことで画像データを処理します。また、Transformerエンコーダーでシーケンスデータを処理できるように、入力シーケンスの前に位置エンコーディングを追加しています。ユーザーは、事前学習済みのエンコーダーの上に線形層を追加することで、画像分類などのタスクを実行できます。Google Vision Transformerの利点は、強力な画像特徴学習能力と幅広い適用性です。このモデルは無料で使用できます。
AI画像検査識別
58.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
40.8K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
39.7K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.3K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M