%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
中国語精選
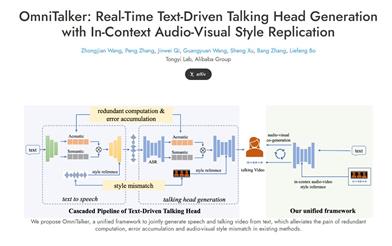
Omnitalker
OmniTalkerは、アリババTongyi研究所が提案した統一フレームワークであり、リアルタイムで音声と動画を生成し、人と機械のインタラクション体験を向上させることを目的としています。その革新的な点は、従来のテキストから音声、音声駆動型の動画生成方法でよくある、音声と動画の同期ずれ、スタイルの不一致、システムの複雑さなどの問題を解決したことにある。OmniTalkerは双方向拡散トランスフォーマーアーキテクチャを採用しており、効率性を維持しながら高忠実度の音声と動画出力を実現します。リアルタイム推論速度は毎秒25フレームに達し、様々なインタラクティブなビデオチャットアプリケーションに適用でき、ユーザー体験を向上させます。
映像制作
38.4K
Deepseek VL2 Small
DeepSeek-VL2は、前世代のDeepSeek-VLを大幅に改良した、高度な大規模混合専門家(MoE)ビジョン言語モデルシリーズです。このモデルシリーズは、ビジュアルクエスチョンアンサー、光学文字認識、文書/表/グラフの理解、およびビジュアルロケーションなど、様々なタスクにおいて卓越した能力を発揮します。DeepSeek-VL2は、DeepSeek-VL2-Tiny、DeepSeek-VL2-Small、DeepSeek-VL2の3つのバリアントで構成され、それぞれ10億、28億、45億の活性化パラメーターを持ちます。DeepSeek-VL2は、活性化パラメーターが同等か少ないにも関わらず、既存のオープンソースの密なモデルやMoEベースのモデルと比較して、競争力のある、あるいは最先端の性能を達成しています。
AIモデル
49.7K

Mmaudio
MMAudioは、高品質なビデオ音声合成を目指した、多様なモーダルを統合した学習技術です。ビデオとテキストの入力に基づき、同期音声の生成が可能で、映画制作、ゲーム開発など様々な用途に適用できます。音声生成の効率と品質を向上させることにより、音声合成を必要とするクリエイターや開発者にとって重要なツールとなります。
映像制作
53.3K
Florence VL
Florence-VLは、生成型視覚エンコーダと深層幅融合技術を導入することで、視覚情報と言語情報の処理能力を強化した視覚言語モデルです。この技術は、機械による画像とテキストの理解度を向上させ、マルチモーダルタスクにおいてより良い結果を得られるという点で重要です。Florence-VLはLLaVAプロジェクトを基に開発されており、事前学習済みモデルと微調整のためのコード、モデルチェックポイント、デモを提供しています。
AIモデル
49.4K
Llava O1
LLaVA-o1は、北京大学元組チームが開発した視覚言語モデルです。GPT-o1と同様に、自発的で体系的な推論を実行できます。Gemini-1.5-pro、GPT-4o-mini、Llama-3.2-90B-Vision-Instructなど、6つの難易度が高いマルチモーダルベンチマークテストにおいて、他のモデルを凌駕する成果を上げています。LLaVA-o1は段階的推論によって問題を解決し、視覚言語モデルにおける独自の強みを示しています。
段階的推論
49.1K
Ppllava
PPLLaVAは、高効率な動画大規模言語モデルです。細粒度ビジュアルプロンプトアライメント、ユーザー指示による畳み込みスタイルプーリングを用いたビジュアルトークンの圧縮、CLIPコンテキスト拡張を組み合わせることで実現しています。VideoMME、MVBench、VideoChatGPT Bench、VideoQA Benchなどのデータセットにおいて最先端の結果を達成し、ビジュアルトークンを1024個のみ使用することで、スループットを8倍に向上させています。
映像制作
46.6K
Agent S
Agent Sは、グラフィカルユーザーインターフェース(GUI)を通じてコンピューターとの自律的なインタラクションを実現することを目指した、オープンなエージェントフレームワークです。複雑な複数ステップのタスクを自動化することで、人間とコンピューターのインタラクションを変革します。経験強化型階層計画手法を取り入れ、オンラインのウェブ知識と叙述的記憶を活用し、過去のインタラクションから高度な経験を抽出し、複雑なタスクを管理可能なサブタスクに分解し、状況記憶を用いて段階的にガイドします。Agent Sは、自身の行動を継続的に最適化し、経験から学習することで、適応性が高く効率的なタスク計画を実現します。OSWorldベンチマークテストでは、ベースラインを成功率9.37%上回り(相対的に83.6%向上)、WindowsAgentArenaベンチマークテストでは幅広い汎用性を示しました。
自動化
46.6K
Slowfast LLaVA
SlowFast-LLaVAは、ビデオ理解と推論のために設計された、訓練不要のマルチモーダル巨大言語モデルです。いかなるデータに対してもファインチューニングを行うことなく、様々なビデオ質問応答タスクやベンチマークにおいて、最先端のビデオ巨大言語モデルと同等、あるいはそれ以上の性能を達成します。
AIモデル
49.4K
Llama3 S V0.2
Llama3-s v0.2は、Homebrew Computer Companyが開発したマルチモーダルチェックポイントであり、音声理解能力の向上に焦点を当てています。このモデルは、早期融合セマンティックマーキングの手法を用いて、コミュニティからのフィードバックを基に改善されています。これにより、モデル構造の簡素化、圧縮効率の向上、そして一貫した音声特徴抽出を実現しています。Llama3-s v0.2は複数の音声理解ベンチマークテストで安定したパフォーマンスを示しており、リアルタイムデモも提供されているため、ユーザーは実際にその機能を体験できます。モデルはまだ初期開発段階であるため、オーディオ圧縮に敏感であることや、10秒を超えるオーディオを処理できないなどの制限がありますが、チームは将来のアップデートでこれらの問題を解決する予定です。
言語識別
51.6K
Llama3 S
llama3-sは、テキストベースの大規模言語モデル(LLM)をネイティブの「聴覚」機能を持つように拡張することを目指した、オープンで進行中の研究実験です。MetaのChameleon論文に触発された技術を用いて、トークンの伝達性に焦点を当て、音声トークンをLLMの語彙に拡張しています。将来的には、様々な入力タイプへの拡張も予定されています。オープンソースの科学実験として、コードベースとデータセットは公開されています。
AIモデル
47.2K
MAVIS
MAVISは、マルチモーダル大規模言語モデル(MLLM)向けの数学ビジョン指令微調整モデルです。主に、視覚的コード化された数学図表、図表と言語の対応付け、数学的推論能力の向上を通じて、MLLMの視覚的数学問題解決能力を強化します。このモデルには、2つの新たに策定されたデータセット、数学ビジョンエンコーダ、数学MLLMが含まれており、3段階のトレーニングパラダイムを通じて、MathVerseベンチマークで最先端の性能を達成しています。
AIモデル
50.2K
MG LLaVA
MG-LLaVAは、低解像度、高解像度、オブジェクト中心の特徴を含む多粒度視覚処理パイプラインを統合することで、モデルの視覚処理能力を強化する機械学習言語モデル(MLLM)です。細部を捉えるために、高解像度視覚エンコーダを追加し、Conv-Gate融合ネットワークを通じて基本的な視覚特徴と融合させます。さらに、オフライン検出器によって識別されたバウンディングボックスを使用してオブジェクトレベルの特徴を統合することで、モデルのオブジェクト認識能力をさらに向上させます。MG-LLaVAは、公開されているマルチモーダルデータのみを使用して指示微調整によってトレーニングされ、優れた知覚能力を示します。
AIモデル
46.6K

Stable Diffusion 3 無料オンライン版
Stable Diffusion 3は、Stability AIが開発した最新のテキスト生成画像モデルです。画像の忠実度、複数主体処理、テキストの一致度が大幅に向上しています。マルチモーダル拡散トランスフォーマー(MMDiT)アーキテクチャを採用し、画像とテキスト表現を別々に処理することで、API、ダウンロード、オンラインプラットフォームへのアクセスをサポートし、様々な用途に適しています。
画像生成
69.3K
Videollama2 7B Base
VideoLLaMA2-7B-Baseは、DAMO-NLP-SGが開発した大規模ビデオ言語モデルであり、ビデオコンテンツの理解と生成に特化しています。このモデルは、ビジュアルクエスチョン?アンサーとビデオ字幕生成において卓越した性能を発揮し、高度な時空間モデリングと音声理解能力により、ユーザーに新たなビデオコンテンツ分析ツールを提供します。Transformerアーキテクチャに基づいており、マルチモーダルデータの処理が可能で、テキストと視覚情報を組み合わせ、正確で洞察力のある出力を生成します。
AIビデオ生成
74.5K
Emo Visual Data
emo-visual-dataは、glm-4vとstep-free-apiプロジェクトによって作成されたビジュアルアノテーションを用いて収集された、5329個の表情包を含む公開データセットです。本データセットは、マルチモーダル大規模言語モデルの訓練とテストに使用でき、画像コンテンツとテキスト記述間の関係の理解に重要な意味を持ちます。
AI画像検出識別
50.2K

Cumo
CuMoは、視覚エンコーダとMLPコネクタにスパースTop-Kゲーテッドエキスパートミックス(MoE)ブロックを統合することで、多様なモダリティに対応する大規模言語モデル(LLM)の拡張アーキテクチャです。これにより、モデルの拡張性を向上させながら、推論時の活性化パラメータの増加をほぼ抑制します。CuMoは、事前学習済みのMLPブロックの後、MoEブロック内の各エキスパートを初期化し、視覚指示調整段階で補助損失を使用してエキスパートの負荷バランスを確保します。CuMoは、様々なVQAおよび視覚指示追従ベンチマークにおいて、他の同種モデルを凌駕しており、完全にオープンソースデータセットに基づいてトレーニングされています。
AIモデル
48.9K
Bunny
Bunnyは、軽量ながらも強力な機能を備えたマルチモーダルモデルシリーズです。様々なプラグアンドプレイ式の視覚エンコーダと言語バックボーンネットワークを提供します。より広範なデータソースから厳選されたデータを用いて、より豊富なトレーニングデータを構築することで、モデルサイズの小ささを補っています。Bunny-v1.0-3Bモデルは、同等のサイズ、あるいはそれ以上のMLLM(7B)モデルを性能で上回り、13Bモデルと同等の性能を示します。
AIモデル
53.3K
高品質新製品
Llava Llama 3 8b V1 1
llava-llama-3-8b-v1_1は、XTunerで最適化されたLLaVAモデルです。meta-llama/Meta-Llama-3-8B-InstructとCLIP-ViT-Large-patch14-336をベースに、ShareGPT4V-PTとInternVL-SFTでファインチューニングされています。画像とテキストの連携処理に特化しており、強力なマルチモーダル学習能力を備えています。様々な下流のデプロイメントや評価ツールキットに対応しています。
AIモデル
70.1K
Moe LLaVA
MoE-LLaVAは、大規模視覚言語モデルに基づくエキスパート混合モデルであり、マルチモーダル学習において優れた性能を発揮します。パラメータ数は少ないにもかかわらず、高い性能を示し、短時間でトレーニングを完了できます。Gradio Web UIとCLI推論に対応しており、モデルライブラリ、要件とインストール、トレーニングと検証、カスタマイズ、可視化、APIなどの機能を提供します。
AIモデル
64.0K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.7K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.4K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.4K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M