%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Unwatermark AI
Unwatermark AIは、AI技術に基づく先進的な透かし除去ツールです。画像や動画の透かしをすばやく除去することが可能です。主な特徴には、自動透かし検出と定位、高品質保証、高速処理、マルチデバイス対応などがあります。本製品は無料の透かし除去サービスを提供することを目指しています。
ビデオ処理
38.1K

Memvid
Memvid は革命的なAIメモリ管理ソリューションであり、テキストデータをビデオにエンコードすることで、何百万ものテキストブロックに対する高速なセmanticサーチを可能にします。従来のベクトルデータベースよりも効率的で、データ量が小さく、データベースがない場合でも情報を迅速にアクセスできます。本製品の価格は無料で、知識管理や情報検索の効率を高めることを目的としています。
知識管理
38.4K

Keysync
KeySyncは高解像度ビデオ向けの無損失リップシンクフレームワークです。従来のリップシンク技術で問題視されている時間一貫性の問題を解決し、表情漏れや顔面被覆を巧妙に処理します。KeySyncの優れた点は、唇再構築とクロスシンクに関する先進的な成果であり、自動吹き替えなどの実アプリケーションに適応しています。
ビデオ編集
37.0K
Deeptrain
Deeptrainは、ビデオ処理に特化したプラットフォームであり、ビデオコンテンツを言語モデルやAIエージェントにシームレスに統合することを目指しています。強力なビデオ処理技術により、ユーザーはテキストや画像と同様に、ビデオコンテンツを簡単に活用できます。GPT-4o、Geminiなど200種類以上の言語モデルに対応しており、多言語ビデオ処理をサポートしています。Deeptrainは開発サポートを無料で提供しており、費用が発生するのは本番環境での利用時のみです。そのため、AIアプリケーション開発の理想的な選択肢となります。主な利点としては、強力なビデオ処理能力、多言語サポート、主要な言語モデルとのシームレスな統合が挙げられます。
映像編集
45.3K

Stereocrafter
StereoCrafterは、基礎モデルを事前情報として利用し、深度推定と立体ビデオ修復技術によって2Dビデオを没入型立体3Dビデオに変換する革新的なフレームワークです。この技術は従来の方法の限界を突破し、表示デバイスに必要な高忠実度な生成性能を向上させます。StereoCrafterの主な利点には、様々な長さや解像度のビデオ入力に対応できること、自己回帰戦略とブロック処理によってビデオ処理を最適化できることなどが挙げられます。さらに、大規模で高品質なデータセットを再構築するための複雑なデータ処理プロセスを開発し、トレーニングプロセスをサポートしています。このフレームワークは、Apple Vision Proや3Dディスプレイなどの3Dデバイス向けに没入型コンテンツを作成するための現実的なソリューションを提供し、デジタルメディアの体験方法を変える可能性を秘めています。
映像制作
52.4K
高品質新製品
Vidtok
VidTokは、マイクロソフトがオープンソースで公開している、一連の先進的なビデオ分割器です。連続分割と離散分割の両方において優れた性能を発揮します。アーキテクチャの効率性、量子化技術、トレーニング戦略において顕著なイノベーションを達成し、効率的なビデオ処理能力を提供しており、複数のビデオ品質評価指標において従来のモデルを上回っています。VidTokの開発は、ビデオ処理と圧縮技術の発展を促進することを目的としており、ビデオコンテンツの効率的な伝送と保存に大きな意味を持ちます。
映像編集
45.8K

Mmaudio
MMAudioは、高品質なビデオ音声合成を目指した、多様なモーダルを統合した学習技術です。ビデオとテキストの入力に基づき、同期音声の生成が可能で、映画制作、ゲーム開発など様々な用途に適用できます。音声生成の効率と品質を向上させることにより、音声合成を必要とするクリエイターや開発者にとって重要なツールとなります。
映像制作
53.0K
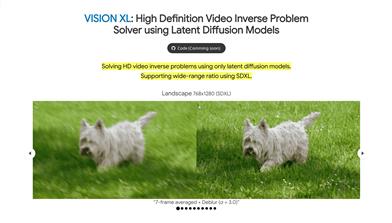
VISION XL
VISION XLは、潜在拡散モデルを利用して高解像度ビデオの逆問題を解決するフレームワークです。擬似バッチ整合サンプリング戦略とバッチ整合反転手法により、ビデオ処理の効率と時間を最適化し、様々な解像度と高解像度復元をサポートします。主な利点としては、多様な解像度と高解像度復元への対応、メモリとサンプリング時間の効率性、オープンソースの潜在拡散モデルSDXLの使用が挙げられます。SDXLを統合することで、複雑なフレーム平均や、ぼけ除去、超解像、修復などの様々な空間劣化の組み合わせを含む、様々な時空間逆問題において最先端のビデオ復元を実現しています。
映像制作
249.5K
Wav2lip
Wav2Lipは、深層学習技術を用いて、ビデオ中の人物の唇の動きを任意の目標音声と高精度に同期させることを目指したオープンソースプロジェクトです。本プロジェクトは、完全なトレーニングコード、推論コード、および事前学習済みモデルを提供しており、CGI顔や合成音声を含む、あらゆる人物、音声、言語をサポートしています。Wav2Lipの基盤技術は、ACM Multimedia 2020で発表された論文『A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild』に基づいています。プロジェクトは、インタラクティブなデモとGoogle Colabノートブックも提供しており、ユーザーは簡単に使用を開始できます。さらに、新規かつ信頼性の高い評価基準と指標、論文におけるそれらの算出方法についても提供しています。
映像編集
73.1K
KEEP
KEEPはカルマンフィルタリング原理に基づいたビデオ顔超解像度フレームワークです。時間的安定した顔の事前情報を特徴伝搬によって維持することを目指しています。以前の復元フレームの情報を融合することで、現在のフレームの復元プロセスを導き、調整し、ビデオフレームにおける一貫した顔の詳細を効果的に捉えます。
AI動画強化
91.6K
高品質新製品
SAM 2
Meta Segment Anything Model 2 (SAM 2)は、Meta社が開発した次世代モデルであり、ビデオおよび画像におけるリアルタイムでプロンプト可能なオブジェクトセグメンテーションに使用されます。最先端の性能を実現しており、ゼロショット汎化をサポートします。つまり、事前に見たことのない視覚コンテンツにも、カスタマイズされた適応なしで適用できます。SAM 2はオープンサイエンスのアプローチに従って公開され、コードとモデルウェイトはApache 2.0ライセンスで、SA-VデータセットはCC BY 4.0ライセンスで共有されています。
AI画像検出識別
54.6K
海外精選
デバイス上で動作するAI字幕/自動字幕生成ツール
AI技術を採用したオンライン字幕生成ツールです。ブラウザからビデオファイルをアップロードし、字幕生成とビデオレンダリングをローカルデバイス上で実行します。データはサーバーに送信されないため、ユーザーデータのプライバシーとセキュリティが確保されます。
映像編集
58.8K
Comfyui ProPainter ノード
ComfyUI ProPainterノードは、ProPainterフレームワークに基づいたビデオ修復プラグインです。フロー伝播と時空間変換器を利用して高度なビデオフレーム編集を実現し、シームレスな修復タスクに最適です。ユーザーフレンドリーなインターフェースと強力な機能を備え、ビデオ修復プロセスを簡素化します。
AI動画編集
74.0K

Actanywhere
ActAnywhereは、前景の主体動作や外観と一致するビデオ背景を自動生成するモデルです。このタスクは、前景の主体動作や外観と一致するだけでなく、アーティストの意図にも沿った背景を合成することを含みます。ActAnywhereは大規模ビデオ拡散モデルを活用し、このタスク向けに特化して開発されました。ActAnywhereは、前景の主体セグメンテーションのシーケンスを入力として、必要なシーンを記述する画像を条件として、条件フレームと整合性のある連続ビデオを生成し、現実的な前景と背景の相互作用を実現します。このモデルは大規模な人とコンピューターのインタラクションビデオデータセットでトレーニングされています。多くの評価により、このモデルは基準モデルよりも明らかに優れた性能を示し、人間以外の主体を含む様々な分布サンプルに対して汎化できることが示されています。
AI動画生成
165.6K

Hyfluid
HyFluidは、疎な多視点ビデオから流体の密度場と速度場を推定するニューラルな手法です。既存のニューロダイナミクス再構成手法とは異なり、HyFluidは密度を正確に推定し、基礎となる速度を明らかにすることで、流体速度の固有の視覚的な曖昧さを克服します。本手法は、物理に基づいた損失関数を導入することで、物理的に妥当な速度場を推定し、同時に流体速度の乱流性を処理します。また、大部分の非回転エネルギーを捉える基礎的なニューラル速度場と、残りの乱流速度をシミュレートする渦粒子速度を含む、混合ニューラル速度表現を設計しています。この手法は、流体再シミュレーションや編集、未来予測、ニューロダイナミックシーン合成など、3次元非圧縮性流体に関する様々な学習や再構成アプリケーションに適用できます。
研究機器
44.7K
Video LLaVA
Video-LLaVAは、先行投影アライメントによって学習された、統合視覚表現を学習するためのモデルです。ビデオと画像表現をアライメントすることで、より高度な視覚理解を実現します。このモデルは、効率的な学習と推論速度を備えており、ビデオ処理や視覚タスクに適しています。
AI動画検索
59.3K
Shipgpt AI
StartPは、AIモデルの迅速な展開と統合を可能にするウェブサイトテンプレートです。AI技術を統合することで、アプリケーションをスマートアプリケーションに変換したり、全く新しいAIアプリケーションを構築したりできます。StartPは、ドキュメント、音声、ビデオ、ウェブサイトなど様々なシナリオに対応したAPIを提供しており、使いやすく、効果も抜群です。柔軟な価格設定と生涯にわたる更新サポートも提供しています。
開発プラットフォーム
58.8K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M