%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


KEEP
紹介 :
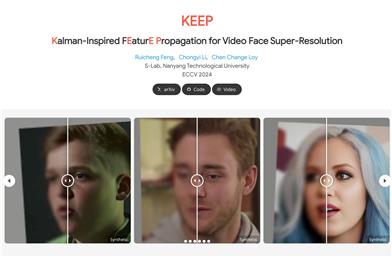
KEEPはカルマンフィルタリング原理に基づいたビデオ顔超解像度フレームワークです。時間的安定した顔の事前情報を特徴伝搬によって維持することを目指しています。以前の復元フレームの情報を融合することで、現在のフレームの復元プロセスを導き、調整し、ビデオフレームにおける一貫した顔の詳細を効果的に捉えます。
ターゲットユーザー :
対象ユーザーは、画像処理およびコンピュータビジョン分野の研究者や開発者、特にビデオ顔超解像度技術に特化した専門家です。KEEPモデルは時間的一貫性を維持する点で優れているため、ビデオシーケンスにおける高品質な顔の詳細の復元が必要なアプリケーションシナリオに最適です。
使用シナリオ
安全監視分野において、KEEPモデルを使用してビデオ監視における顔認識の精度を向上させる。
エンターテインメント業界において、古いビデオ素材の顔の鮮明度を改善し、視聴体験を向上させるために使用される。
ソーシャルメディア上で、ユーザーはKEEPモデルを使用してアップロードしたビデオの顔の鮮明度を高めることができる。
製品特徴
高品質な超解像画像を生成するための、エンコーダとデコーダで構成されたVQGAN生成モデル。
カルマンフィルタリング原理を統合し、時間的情報の伝搬を促進し、安定した潜在コード事前情報を維持するためのカルマンフィルタリングネットワーク。
カルマンゲインネットワークによって、現在のフレームの観測状態と前のフレームの予測状態を再帰的に融合し、現在の状態のより正確な事後推定を形成します。
局所的時間的一貫性をさらに促進し、情報伝搬を正規化するためのクロスフレームアテンション(CFA)レイヤー。
証拠の蓄積と時間的一貫性の強化により、顔ビデオ超解像度に適しています。
ECCV 2024で発表され、ビデオフレームにおける顔の詳細の捉え方の有効性を示しました。
使用チュートリアル
1. KEEPモデルの公式ウェブサイトにアクセスして、詳細情報とコードを入手してください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 関連する研究論文を読んで、KEEPモデルの動作原理と適用事例を理解してください。
3. KEEPモデルを実行するために必要なソフトウェア環境をダウンロードしてインストールしてください。
4. 超解像処理が必要なビデオ顔データセットを用意してください。
5. ドキュメントの指示に従って、モデルパラメータを構成し、データセットを読み込んでください。
6. KEEPモデルを実行し、超解像処理後の結果を観察および分析してください。
7. 必要に応じてモデルパラメータを調整して、超解像効果を最適化してください。
おすすめAI製品
高品質新製品
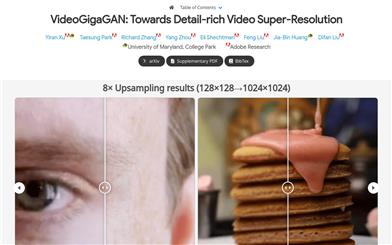
Videogigagan
VideoGigaGANは、大規模画像アップサンプラーGigaGANを基にしたビデオ超解像度(VSR)モデルです。高周波数ディテールと時間的一貫性のあるビデオを生成できます。時間的アテンション層と特徴量伝播モジュールを追加することで、ビデオの時間的一貫性を大幅に向上させ、アンチエイリアシングブロックを使用してジャギーアーティファクトを低減します。VideoGigaGANは、公開データセットにおいて最先端のVSRモデルと比較され、8倍の超解像度ビデオ結果を示しました。
AI動画強化
342.8K
Hitpaw オンライン動画エンハンサー
HitPaw Online Video Enhancer 4Kは、AIを活用した動画エンハンサーです。ワンクリックでぼやけを解消し、解像度を向上させます。最高のオンライン動画エンハンサーとして、低解像度動画の画質を1080P/4Kまで向上させることができ、操作も簡単で効果も抜群です。
AI動画強化
253.6K