%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
海外精選
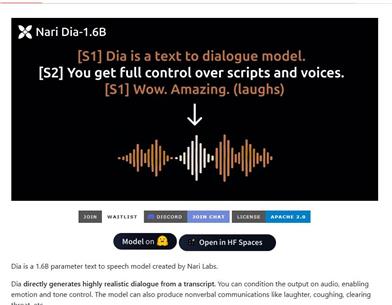
Dia AI
Diaは、Nari Labsが開発した1.6億パラメータのテキスト音声変換(TTS)モデルであり、テキストから直接、非常にリアルな会話を生成できます。このモデルは、感情やトーンのコントロールをサポートしており、笑い声や咳などの非言語的なコミュニケーションも生成できます。その事前学習済みモデルの重みはHugging Faceでホストされており、英語の生成に対応しています。この製品は、研究や教育用途にとって非常に重要であり、対話生成技術の発展を促進します。
パーソナルケア、ビューティー、ファッション
37.5K

Megatts 3
MegaTTS 3は、バイトダンスが開発したPyTorchベースの高効率音声合成モデルであり、超高品質の音声クローン機能を備えています。軽量のアーキテクチャはわずか0.45Bのパラメータで構成され、中国語、英語、コードの切り替えに対応し、入力テキストに基づいて自然で滑らかな音声を作成できます。学術研究や技術開発で幅広く利用されています。
["ファッション, AI モデル]
38.1K
CSM 1B
CSM 1BはLlamaアーキテクチャに基づいた音声生成モデルであり、テキストとオーディオ入力からRVQオーディオコードを生成できます。このモデルは主に音声合成分野で使用され、高品質の音声生成能力を備えています。その利点は、複数話者の会話シーンを処理し、コンテキスト情報を使用して自然で滑らかな音声を生成できることです。このモデルはオープンソースであり、研究と教育目的での使用を支援することを目的としていますが、なりすまし、詐欺、または違法行為に使用することを明確に禁止しています。
ファッションモデル
55.2K
Zonos TTS
Zonos TTSは、多言語対応、感情制御、ゼロサンプル音声クローンに対応した高度なAIテキスト音声変換技術です。自然で表現力豊かな音声生成が可能で、教育、オーディオブック、ビデオゲーム、音声アシスタントなど、さまざまな場面に適しています。高品質なオーディオ出力(44kHz)と高速リアルタイム処理機能により、効率的でパーソナライズされた音声生成ソリューションを提供します。製品自体は完全無料ではありませんが、さまざまなユーザーニーズに対応できる柔軟な価格体系を提供しています。
["パースウェア],["バックパック]
45.3K
Zonos
Zonosは、テキストプロンプトとスピーカーエンベディングまたはオーディオプレフィックスに基づいて自然な音声生成を行う、高度な多言語対応テキスト音声変換モデルです。数秒間の参照音声だけで、話者の声を正確に複製できる音声クローン機能も備えています。高品質な音声出力(44kHz)を特長とし、話速、イントネーション、音質、感情(喜び、恐怖、悲しみ、怒りなど)を細かく制御できます。PythonとGradioインターフェースを提供し、ユーザーは簡単に利用開始でき、Dockerによるデプロイにも対応しています。RTX 4090上でのリアルタイム係数は約2倍で、高品質な音声合成が必要なアプリケーションに最適です。
テキスト読み上げ音声
60.7K
Zonos V0.1
Zonos-v0.1は、Zyphraチームが開発したリアルタイムテキスト音声変換(TTS)モデルであり、高忠実度の音声クローン機能を備えています。このモデルは、Apache 2.0オープンソースライセンスの下で公開されている、16億パラメータのTransformerモデルと16億パラメータのハイブリッドモデル(Hybrid)で構成されています。テキストプロンプトに基づいて自然で表現力豊かな音声を作成でき、複数の言語をサポートしています。さらに、5~30秒の音声クリップで高品質の音声クローンを作成でき、話速、トーン、音質、感情などの条件に合わせて調整可能です。主な利点としては、生成品質が高く、リアルタイムのインタラクションに対応し、柔軟な音声制御機能を提供している点が挙げられます。このモデルの公開は、TTS技術の研究開発を促進することを目的としています。
言語克服
58.5K
Turbotts
TurboTTSは、最先端の人工知能技術に基づいたテキスト音声変換ツールです。自然でリアルな音声に書面テキストを迅速に変換でき、70以上の言語と300以上のリアルな音声タイプに対応しています。主な特長は、高品質の音声出力、シンプルで使いやすいインターフェース、そして迅速かつ効率的なコンテンツ生成能力です。グローバルで228,000名を超えるクリエイターにご利用いただき、毎日5,000万件以上の音声テキストを処理し、99.9%の稼働時間と98%の顧客満足度を実現しています。TurboTTSは無料プランと有料プランを提供しており、個人ユーザーとプロフェッショナルユーザーの両方に最適です。
テキスト読み上げ音声
50.0K
高品質新製品

Kokoro TTS
Kokoro TTSは、テキストコンテンツを自然で滑らかな音声出力に変換することに特化したAIモデルです。StyleTTS 2アーキテクチャを基盤とし、8200万パラメーターを備えることで、高品質の音声合成を維持しながら、高いパフォーマンスと低いリソース消費を実現しています。多言語対応とカスタマイズ可能な音声パックにより、オーディオブック、ポッドキャスト、研修ビデオの作成など、様々なシーンにおけるニーズに対応します。特に教育分野において、コンテンツのアクセシビリティと魅力を高めるのに役立ちます。さらに、Kokoro TTSはオープンソースであるため、無料で利用でき、コストパフォーマンスに優れています。
テキスト音声変換
61.0K
Llasa 3B
Llasa-3Bは、LLaMAアーキテクチャに基づいて開発された強力なテキスト音声変換(TTS)モデルであり、中国語と英語の音声合成に特化しています。XCodec2の音声符号化技術と組み合わせることで、テキストを自然で滑らかな音声に効率的に変換できます。主な利点としては、高品質の音声出力、多言語合成のサポート、柔軟な音声プロンプト機能などが挙げられます。このモデルは、オーディオブック制作、音声アシスタント開発など、音声合成が必要な様々な場面に適しています。オープンソースであるため、開発者は自由に機能を探求?拡張することができます。
テキスト音声変換
62.1K
Kokoro 82M
Kokoro-82Mは、hexgradによって作成され、Hugging Faceでホストされているテキスト音声変換(TTS)モデルです。8200万パラメーターを備え、Apache 2.0ライセンスの下でオープンソースとして公開されています。2024年12月25日にv0.19版がリリースされ、10種類のユニークな音声パックを提供しています。TTS Spaces Arenaで1位を獲得しており、パラメーター規模とデータ使用における効率性の高さを示しています。アメリカ英語とイギリス英語に対応し、高品質の音声出力を生成できます。
テキスト読み上げ音声
91.1K

Tangoflux
TangoFluxは、5億1500万パラメータを持つ高効率なテキスト音声変換(TTA)モデルです。単一のA40 GPU上で、最長30秒の44.1kHzオーディオをわずか3.7秒で生成できます。CLAP-Ranked Preference Optimization (CRPO)フレームワークを提案することで、TTAモデルの整列における課題を解決し、反復的な生成と選好データの最適化を通じてTTAの整列を強化します。TangoFluxは、客観的および主観的ベンチマークテストにおいて最先端の性能を達成しており、すべてのコードとモデルはオープンソースとして公開され、TTA生成の更なる研究を支援します。
テキスト音声変換
52.4K
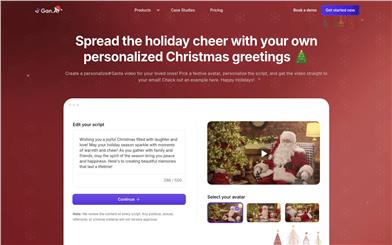
Gan.aiによるサンタビデオ作成ツール
Gan.AIによるText to Santa Videosは、ユーザーが個性的なサンタクロースビデオを作成し、親しい人や友人に祝いのメッセージを送ることができるオンラインプラットフォームです。このプラットフォームは、クリスマスをテーマにしたバーチャルキャラクター、パーソナライズされた脚本、そしてメールへの直接送信機能を通じて、斬新なパーソナライズビデオ作成と共有方法を提供します。テキスト音声変換やアバターAPIなど、最新のAI技術とビデオ録画?パーソナライズ機能を組み合わせることで、ユーザーは大規模なビデオ録画とパーソナライズを行うことができます。本プラットフォームは既に数百万本のビデオを何千人もの顧客のために生成しており、AIによる唇の同期や音声クローン、無料ビデオレコーダー、AIランディングページなどの強力な機能を備えています。料金に関しては、無料で利用開始でき、詳細な料金情報は公式サイトをご確認ください。
映像制作
47.7K
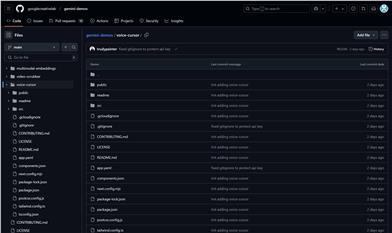
Voice Cursor
Voice Cursorは、Gemini 2.0のネイティブ音声機能をベースとした実験的なテキストエディタです。Geminiの新しいテキスト音声変換APIをテキストエディタに統合し、スムーズでコンテキストに合わせた音声生成を実現する方法を示しています。このプロジェクトは、Gemini 2.0の強力な新機能を紹介するだけでなく、開発者やユーザーが新しい技術を探求し活用できる実践的な例を提供します。Google Creative Labによる革新的なプロジェクトであり、技術の限界を押し広げ、新しいインタラクション方法を提供することを目指しています。現在無料で提供されており、主に開発者やテクノロジー愛好家を対象としています。生産性向上やアクセシビリティの向上のための革新的なソリューションを求める個人やチームに最適です。
開発とツール
51.3K
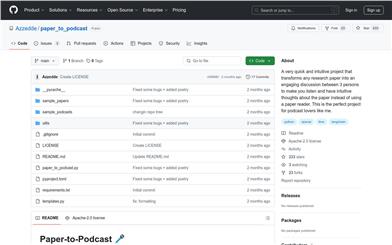
Paper To Podcast
Paper-to-Podcastは、学術論文をポッドキャスト形式に変換するツールです。3人の人物による議論をシミュレートすることで、聴取者がより自然で人間味のある方法で論文の内容を理解できるようにします。複雑な情報をより簡単に吸収できるだけでなく、貴重な洞察と批判的思考を提供します。このツールはOpenAI APIを使用してテキスト音声変換を行い、異なるキャラクター特性を持つリアルな音声を生成するため、通勤中や旅行中に論文の内容を読まずに聴くことで理解することができます。
テキスト読み上げ音声
55.5K
海外精選
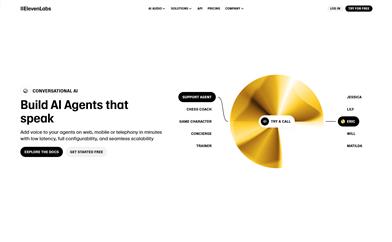
Elevenlabs 会話型AI
ElevenLabs 会話型AIは、ウェブサイト、モバイルデバイス、または電話に迅速に導入できる音声エージェント製品です。低遅延、完全な構成性、シームレスな拡張性を特長とし、自然な会話におけるターン制と割り込み処理に対応しており、雑音環境での予測不可能な会話にも適しています。音声テキスト変換、大規模言語モデル(LLM)、テキスト音声変換技術を統合し、多言語とカスタムボイスをサポートしており、カスタマーサポート、スケジューリング、アウトバウンドセールスなど、さまざまなシナリオに適しています。
チャットボット
59.1K
Auralis
Auralisは、テキストを自然な音声に高速変換できるテキスト音声変換(TTS)エンジンです。音声クローンに対応しており、処理速度が非常に速いため、長編小説であっても数分以内に処理できます。高速性、高効率性、容易な統合、高品質のオーディオ出力が主な特長であり、迅速なテキスト音声変換が必要な場面に最適です。AuralisはPython APIに基づいており、長テキストのストリーミング処理、組み込みオーディオエンハンサー、自動言語検出などの機能を備えています。製品背景情報によると、AuralisはAstraMind AIによって開発され、現実世界のアプリケーションに実用的なテキスト音声変換ソリューションを提供することを目的としています。価格についてはページ上に明示されていませんが、コードベースはApache 2.0ライセンスで公開されており、プロジェクトで無料で利用できます。
文章音声変換
76.2K
Outetts 0.2 500M
OuteTTS-0.2-500MはQwen-2.5-0.5Bを基盤としたテキスト音声合成モデルであり、より大規模なデータセットで訓練されたことで、正確性、自然さ、語彙数、音声クローン機能、多言語対応において顕著な向上を実現しました。本モデルの訓練はHugging FaceによるGPU支援のおかげで実現しました。
音声合成
95.5K
AI Voice Lab
AI Voice Labは、最新のGPT系AI音声モデル技術を活用した無料のAI音声合成ツールです。超リアルな音声合成結果を提供し、20種類以上の言語と100種類以上の音声に対応しています。毎日無料利用回数を提供しており、動画や音声制作など様々なシーンで活用でき、コンテンツの魅力向上に貢献します。
テキスト読み上げ音声
82.5K
Outetts
OuteTTSは、純粋な言語モデリング手法を用いて音声生成を行う実験的なテキスト音声変換モデルです。高度な言語モデル技術により、テキストを自然に聞こえる音声に変換できる点が重要であり、音声合成、音声アシスタント、自動ナレーションなどの分野で大きな意義を持ちます。OuteAIによって開発され、Hugging FaceモデルとGGUFモデルに対応しており、インターフェースを通じて音声クローンなどの高度な機能も利用可能です。
テキスト読み上げ音声
88.0K
Outetts 0.1 350M
OuteTTS-0.1-350Mは、外部アダプタや複雑なアーキテクチャを必要としない、純粋な言語モデルに基づくテキスト音声合成技術です。精巧に設計されたプロンプトとオーディオトークンを用いて、高品質の音声合成を実現します。LLaMaアーキテクチャをベースとし、3億5000万パラメータを使用することで、言語モデルを直接音声合成に用いる可能性を示しています。音声処理は、WavTokenizerによるオーディオトークナイゼーション、CTC強制アライメントによる単語とオーディオトークンの正確なマッピング、そして特定のフォーマットに従った構造化プロンプトの作成という3つのステップで行われます。OuteTTSの主な利点としては、純粋な言語モデリング手法、音声クローン機能、llama.cppおよびGGUF形式との互換性などが挙げられます。
テキスト読み上げ音声
70.9K
Lightning
Lightningはsmallest.aiが開発した最新のテキスト音声変換モデルであり、その超高速とコンパクトなサイズで、マルチモーダルAIにおける性能とサイズの限界を突破しました。本モデルは英語やヒンディー語など複数のアクセントに対応し、さらに多くの言語への迅速な拡張を予定しています。Lightningの非自己回帰アーキテクチャにより、従来の自己回帰モデルのように段階的に音声生成を行うのではなく、オーディオクリップ全体を同時に合成できます。Lightningの主なメリットには、高速な生成速度、小さなモデルサイズ、多言語対応、そして新しいデータへの迅速な適応などが挙げられます。製品背景情報によると、Lightningの導入は、音声ロボット会社が遅延とコストを大幅に削減し、アーキテクチャを簡素化することを目的としています。価格については、Lightningの価格は1分あたり0.04ドルからとなっており、月間100,000分以上使用する企業のお客様には、カスタム価格プランを提供しています。
テキスト読み上げ音声
44.2K
Fish Speech
Fish Speechは、音声合成に特化した製品です。高度な深層学習技術を用いて、テキストを自然で滑らかな音声に変換します。中国語、英語など、複数の言語に対応しており、音声アシスタント、オーディオブック制作など、テキストの音声変換が必要な場面で活用できます。高品質の音声出力、使いやすさ、柔軟性が主な特長です。背景情報として、データセットのサイズ拡大や量子化器パラメーターの改善など、継続的なアップデートによりサービス向上に努めています。
テキスト音声変換
107.1K
Fish Agent V0.1 3B
Fish Agent V0.1 3Bは、これまでにない精度で環境音声情報を捕捉?生成できる画期的な音声合成モデルです。意味的トークン化アーキテクチャを採用することで、従来のsemantic encoder/decoderを必要としません。また、最先端のテキスト音声変換(TTS)モデルであり、70万時間の多言語音声データで学習されています。Qwen-2.5-3B-Instructの継続的プリトレーニング版として、2000億トークンの音声およびテキストデータで学習されました。英語、中国語を含む8言語をサポートしており、言語ごとに学習データ量は異なります。英語と中国語は約30万時間、その他の言語は約2万時間です。
テキスト読み上げ音声
50.0K
中国語精選
趣丸千音
趣丸千音は、AIによる音声生成サービスを提供するウェブサイトです。テキストコンテンツをプロフェッショナルなオーディオに変換できます。本製品は、目標とする音声の音響特性を完璧に複製するだけでなく、豊かな感情とリズムを維持します。ユーザーは年齢、感情、アクセント、コンテンツなどの設定を自由に調整でき、パーソナライズされたニーズを満たし、音声に価値を与えます。製品背景情報によると、趣丸千音は広州趣闖網絡科技有限公司が開発し、多言語合成と動画翻訳に対応しており、パーソナライズされた音声合成と動画翻訳サービスを必要とするユーザーに最適です。
テキスト読み上げ音声
82.8K
Maskgct TTS デモ
MaskGCT TTSデモは、Hugging Faceプラットフォーム上のamphionが提供するMaskGCTモデルに基づいたテキスト音声変換(TTS)デモです。このモデルは深層学習技術を利用し、テキストを自然で滑らかな音声に変換します。様々な言語とシーンに対応可能です。MaskGCTモデルは、その効率的な音声合成能力と多言語対応によって注目を集めています。音声認識と音声合成の精度向上だけでなく、様々な用途でパーソナライズされた音声サービスを提供できます。現在、Hugging Faceプラットフォームで無料トライアルを提供しており、価格や具体的な位置付けについては、さらなる情報が必要です。
テキスト読み上げ音声
129.4K

Maskgct
MaskGCTは、明示的なアライメント情報や音素レベルの継続時間予測を必要としない革新的なゼロショットテキスト音声変換(TTS)モデルです。自己回帰型と非自己回帰型のシステムにおける問題点を解決し、2段階モデルを採用しています。第1段階では、テキスト予測を使用して音声自己教師あり学習(SSL)モデルから抽出した意味的トークンを使用し、第2段階では、これらの意味的トークンに基づいて音響トークンを予測します。MaskGCTはマスクと予測の学習パラダイムに従い、トレーニング中に、与えられた条件とプロンプトに基づいてマスクされた意味的または音響トークンを予測する学習を行います。推論時には、指定された長さのトークンを並列に生成します。実験により、MaskGCTは、品質、類似性、および理解可能性の点で、最先端のゼロショットTTSシステムを上回ることが示されています。
テキスト音声変換
60.2K
海外精選
Elevenlabs ボイスデザイン
ElevenLabs ボイスデザインは、シンプルなテキストプロンプトでカスタムサウンドを設計?生成できるオンラインプラットフォームです。年齢、アクセント、トーン、キャラクター(架空のトロール、エルフ、エイリアンなども含む)など、特定の音声特性を迅速に作成できる点が重要です。オーディオコンテンツクリエイター、広告制作者、ゲーム開発者など、様々な商業およびクリエイティブプロジェクトに強力なツールを提供します。ElevenLabsでは無料トライアルを提供しており、登録後すぐにサービスを試用できます。
言語克服
53.3K
D1tools文字音声変換
文字音声変換ツールは、テキストコンテンツを自然で滑らかな音声出力に変換するオンラインサービスです。74種類の言語と318種類の異なる音声スタイルに対応しています。動画の吹き替え、オーディオブック制作、アナウンス、海外マーケティング、外国語学習など、幅広い用途にご利用いただけます。主な利点としては、多言語対応、豊富な音声選択肢、ダウンロードやインストール不要、回数と時間無制限、そして完全無料という点が挙げられます。コンテンツクリエーター、マーケター、教育関係者、語学学習者にとって非常に便利なツールです。
テキスト音声変換
64.6K
高品質新製品
F5 TTS
F5-TTSは、SWividチームが開発したテキスト音声合成(TTS)モデルです。深層学習技術を活用し、テキストを自然で流暢、かつ原文に忠実な音声出力に変換します。高自然度だけでなく、音声の明瞭性と正確性にもこだわり、音声合成の高品質を求める様々な用途(音声アシスタント、オーディオブック制作、自動ニュース速報など)に適しています。Hugging Faceプラットフォームで公開されており、ユーザーは簡単にダウンロードしてデプロイできます。複数の言語と音声タイプに対応し、柔軟性と拡張性に優れています。
AI文章翻訳音声
106.0K

Finevoice
FineVoiceは、最先端の人工知能技術を用いた多機能AI音声合成プラットフォームです。リアルでパーソナライズされた音声サービスを提供し、テキストの音声化、音声テキスト化、音声変換といった機能により、コンテンツ制作の可能性を大幅に広げます。高効率、低コスト、多言語対応、使いやすさが主な特長で、大量の音声コンテンツを迅速に生成する必要がある個人や企業ユーザーに最適です。
AI音声合成
61.0K
- 1
- 2
- 3
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M