%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Level Navi Agent Search
Level-Navi Agentは、複雑な問題を分解し、インターネット上の情報を段階的に検索してユーザーの質問に答えることができる、オープンソースの汎用ウェブ検索エージェントフレームワークです。金融、ゲーム、スポーツ、映画、イベントなど5つの分野を網羅するWeb24データセットを提供することで、検索タスクにおけるモデルのパフォーマンス評価の基準を提供します。このフレームワークはゼロショット学習と少ショット学習をサポートし、大規模言語モデルの中国語ウェブ検索エージェント分野における応用にとって重要な参考資料となります。
AI検索
44.2K
Videograin
VideoGrainは、時空間的注意機構の調整により多粒度動画編集を実現する、拡散モデルに基づく動画編集技術です。この技術は、従来の方法におけるセマンティックアライメントと特徴量のカップリングの問題を解決し、動画コンテンツを精密に制御できます。主な利点としては、ゼロショット編集機能、効率的なテキストから領域への制御、および特徴量の分離機能が含まれます。映画のポストプロダクション、広告制作など、動画の複雑な編集が必要なシーンに適しており、編集効率と品質を大幅に向上させることができます。
映像編集
43.9K
X Dyna
X-Dynaは、革新的なゼロショットの人物画像アニメーション生成技術です。駆動ビデオの表情や動作を一枚の人物画像に移転することで、リアルで表現力豊かな動画効果を生み出します。この技術は拡散モデルに基づいており、Dynamics-Adapterモジュールにより、参照外観コンテキストを拡散モデルの空間的注意機構に効果的に統合し、同時に運動モジュールが滑らかで複雑な動きのディテールを合成する能力を維持します。身体の姿勢制御だけでなく、ローカル制御モジュールによって顔の表情を人物のアイデンティティに依存せず捉え、正確な表情の伝達を実現します。X-Dynaは、多様な人物やシーンを含むビデオの混合データで学習されており、物理的な人体運動や自然なシーンのダイナミクスを学習し、高度にリアルで表現力豊かなアニメーションを生成します。
映像制作
46.1K
Meta Motivo
Meta MotivoはMeta FAIRが発表した、行動ベースモデルの先駆けです。新規の教師なし強化学習アルゴリズムによって事前学習されており、複雑な仮想ヒューマノイドエージェントを制御し、全身タスクを遂行するために用いられます。本モデルは、動作追跡、姿勢到達、報酬最適化など、テスト時にプロンプトを通じて未見のタスクを解決でき、追加の学習や微調整は不要です。この技術の重要性は、ゼロショット学習能力にあり、多様な複雑なタスクを処理しながら、行動の堅牢性を維持します。Meta Motivoの開発背景には、より複雑なタスクや様々なタイプのエージェントへの汎化能力の追求があり、オープンソースの事前学習済みモデルとトレーニングコードは、コミュニティによる行動ベースモデル研究の更なる発展を促します。
AIモデル
47.5K

拡散自己蒸留 (Diffusion Self Distillation)
Diffusion Self-Distillationは、拡散モデルに基づく自己蒸留技術であり、ゼロショットカスタム画像生成に使用されます。この技術により、アーティストやユーザーは、大量のペアデータなしで、事前学習済みのテキストから画像へのモデルを使用して独自のデータセットを生成し、テキストと画像の条件付き画像から画像へのタスクを実現するためにモデルを微調整できます。この手法は、同一性保持生成タスクにおいて、既存のゼロショット手法を凌駕し、テスト時の最適化を必要とせずに、インスタンスごとのチューニング技術に匹敵する性能を発揮します。
画像生成
66.0K
高品質新製品
Voicv
Voicvは最先端の音声クローン作成プラットフォームです。数分以内にあなたの声をデジタル資産に変換でき、多言語対応とゼロショット学習をサポートしています。高度なAI技術とユーザーフレンドリーな設計を組み合わせ、プロフェッショナルレベルの音声クローン作成機能を提供します。Voicvの主な利点には、ゼロショット音声クローン、多言語対応、リアルタイム処理、高精度、クロスプラットフォーム対応、エンタープライズレベルの準備などが含まれます。製品の背景情報では、Voicvがその技術を通じて、コンテンツクリエイター、声優などのユーザーが母国語を含む多言語でコンテンツを作成し、同時に個人ブランドと音声の特徴を維持することを支援することに取り組んでいることが示されています。
AI技術
112.1K
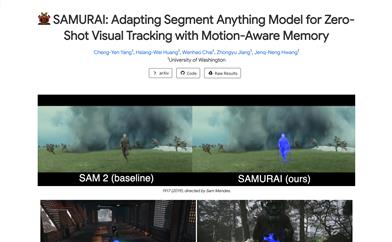
SAMURAI
SAMURAIは、Segment Anything Model 2 (SAM 2)をベースとしたビジュアルオブジェクトトラッキングモデルです。高速移動する物体や自己遮蔽する物体のビジュアルトラッキングタスクに特化して設計されています。時間的運動手がかりと運動知覚メモリ選択メカニズムを導入することで、物体の運動を効果的に予測し、マスク選択を最適化します。再トレーニングや微調整なしで、堅牢かつ正確なトラッキングを実現します。SAMURAIはリアルタイム環境で動作し、複数のベンチマークデータセットで強力なゼロショット性能を示しており、微調整なしで汎化できる能力を実証しています。評価において、SAMURAIは成功率と精度において既存のトラッカーと比較して大幅な向上を示しました。例えば、LaSOT-extではAUCが7.1%向上し、GOT-10kではAOが3.5%向上しました。さらに、LaSOTにおける教師あり学習手法と比較しても競争力を示しており、複雑なトラッキングシーンにおける堅牢性と動的環境における潜在的な実用性を強調しています。
ゼロショット学習
52.7K
Promptfix
PromptFixは、拡散モデルが人間の指示に従って様々な画像処理タスクを実行できるようにする包括的なフレームワークです。大規模な指示従順データセットを構築し、高周波数ガイド付きサンプリング手法を提案してノイズ除去プロセスを制御し、補助プロンプトアダプターを設計して視覚言語モデルを用いてテキストプロンプトを強化することで、モデルのタスク汎化能力を高めています。PromptFixは、様々な画像処理タスクにおいて従来の方法を上回る性能を示し、ブラインドリストアおよび合成タスクにおいて優れたゼロショット能力を発揮します。
画像編集
53.8K

ROCKET 1
ROCKET-1は、オープンワールド環境における具象化された意思決定のために設計された視覚言語モデル(VLMs)です。このモデルは、視覚的?時間的コンテキストプロンプトプロトコルを通じて、VLMsとポリシーモデル間の通信を繋ぎ、過去と現在の観測からのオブジェクト分割を利用してポリシーと環境のインタラクションを導きます。ROCKET-1はこの方法により、VLMsの視覚言語推論能力を解き放ち、特に空間理解において、複雑な創造的なタスクを解決することを可能にします。Minecraftにおける実験では、この手法によりエージェントが以前は不可能だったタスクを達成できることが示され、具象化された意思決定における視覚的?時間的コンテキストプロンプトの有効性を強調しています。
モデルトレーニングとデプロイメント
48.0K

Maskgct
MaskGCTは、明示的なアライメント情報や音素レベルの継続時間予測を必要としない革新的なゼロショットテキスト音声変換(TTS)モデルです。自己回帰型と非自己回帰型のシステムにおける問題点を解決し、2段階モデルを採用しています。第1段階では、テキスト予測を使用して音声自己教師あり学習(SSL)モデルから抽出した意味的トークンを使用し、第2段階では、これらの意味的トークンに基づいて音響トークンを予測します。MaskGCTはマスクと予測の学習パラダイムに従い、トレーニング中に、与えられた条件とプロンプトに基づいてマスクされた意味的または音響トークンを予測する学習を行います。推論時には、指定された長さのトークンを並列に生成します。実験により、MaskGCTは、品質、類似性、および理解可能性の点で、最先端のゼロショットTTSシステムを上回ることが示されています。
テキスト音声変換
60.4K
プロンプトエンジニアリング
プロンプトエンジニアリングは人工知能分野の最先端技術であり、AI技術とのインタラクションの仕方を根本的に変革しています。このオープンソースプロジェクトは、初心者から経験豊富な実践者まで、プロンプトエンジニアリング技術の学習、構築、共有のためのプラットフォームを提供することを目指しています。基礎から高度な内容まで幅広い例を含み、プロンプトエンジニアリング分野における学習、実験、イノベーションを促進します。さらに、コミュニティメンバーによる革新的な技術の共有を奨励し、プロンプトエンジニアリング技術の発展を共同で推進します。
学習教育
49.1K
高品質新製品

Whisper Large V3 Turbo
Whisper large-v3-turboは、OpenAIが開発した高度な自動音声認識(ASR)および音声翻訳モデルです。500万時間以上のラベル付け済みデータでトレーニングされており、ゼロショット設定で多くのデータセットやドメインに汎化できます。このモデルはWhisper large-v3を微調整したバージョンで、速度向上のためデコード層が32から4に削減されていますが、わずかに品質が低下する可能性があります。
AI音声認識
90.5K
Omni Zero Couples
Omni-Zero-Couplesは、Diffusersパイプラインを用いたゼロショットスタイル化カップル肖像画生成モデルです。深層学習技術を活用し、事前に定義されたスタイルサンプルを必要とせずに、特定の芸術スタイルを持つカップル肖像画を生成します。この技術は、芸術創作、パーソナライズされたギフト制作、デジタルエンターテインメント分野で幅広い応用が期待できます。
AI画像生成
56.0K
高品質新製品
Seed Music
Seed-Musicは、表現力豊かな多言語ボーカル音楽の生成を統一的なフレームワークでサポートする音楽生成システムです。音符レベルでの精密な調整が可能で、ユーザー自身の音声を取り込んで音楽制作に活用することもできます。高度な言語モデルと拡散モデルを採用することで、多様な創作ツールをミュージシャンに提供し、様々な音楽制作ニーズに対応します。
音楽制作
92.7K

Seed Vc
seed-vcはSEED-TTSアーキテクチャに基づく音声変換モデルであり、特定の人物の音声サンプルがなくても音声変換を行うことができる零サンプル音声変換を実現します。この技術は、オーディオ品質と音色の類似性において優れた性能を示し、高い研究価値と応用価値を有しています。
AI音声合成
78.9K
高品質新製品
Mimicbrush
MimicBrushは、革新的な画像編集モデルです。ユーザーは、ソース画像内の編集領域を指定し、野外参考画像を提供することで、ゼロショット画像編集を実現できます。このモデルは、両者間の意味的対応関係を自動的に捉え、編集を一度で完了します。MimicBrushは拡散事前学習に基づいて開発され、自己教師あり学習によって異なる画像間の意味関係を捉えます。実験により、様々なテストケースにおいてその有効性と優位性が証明されています。
AI画像編集
472.2K

Slicedit
Sliceditは、テキストから画像への拡散モデルと時空間スライシングを組み合わせることで、ビデオ編集における時間的一貫性を高めるゼロショットビデオ編集技術です。この技術は、元のビデオの構造と動きを保持しながら、目標となるテキストの説明に合致した編集を可能にします。広範な実験により、Sliceditが現実世界のビデオ編集において顕著な利点を持つことが実証されました。
AI動画編集
55.5K

Naturalspeech 3
NaturalSpeech 3は、音声の様々な属性(内容、韻律、音色、音響的詳細など)を分解し、それぞれを個別に生成することで、音声合成の品質、類似性、韻律を向上させることを目指しています。このシステムは、分解ベクトル量子化(FVQ)を用いて音声波形を解きほぐすニューラルコーデックと、対応するプロンプトに基づいて各部分空間の属性を生成する分解型拡散モデルを設計しています。
AI音声合成
130.5K

Openvoice
OpenVoiceは、参照音声の音色を正確にクローンし、様々な言語やアクセントの音声を生成できるオープンソースの音声クローン技術です。感情やアクセントなどの音声スタイルを柔軟に制御できるほか、リズム、休止、イントネーションなども調整可能です。ゼロショットクロスリンガル音声クローンを実現しており、生成音声と参照音声の言語が訓練データに含まれていなくても音声生成が可能です。
AI音声克隆
2.4M
Cola
Colaは、言語モデル(LM)を使用して2つ以上の視覚言語モデル(VLM)の出力を統合する手法です。このモデル統合手法は、Cola(COordinative LAnguage model for visual reasoning)と呼ばれています。Colaは、LMファインチューニング(Cola-FTと呼ばれます)を行うと最適な効果を発揮します。また、ゼロショットまたは少ショットコンテキスト学習(Cola-Zeroと呼ばれます)においても有効です。性能向上に加え、ColaはVLMのエラーに対してもよりロバストです。Colaは、InstructBLIPなどの大規模マルチモーダルモデルを含む様々なVLMと、VQA v2、OK-VQA、A-OKVQA、e-SNLI-VE、VSR、CLEVR、GQAの7つのデータセットに適用可能であり、常に性能向上を示すことを実証しました。
AI画像検出識別
55.5K

Directaiによるコンピュータビジョン
DirectAIは、大規模言語モデルとゼロショット学習に基づいたプラットフォームです。お客様のご要望に合わせて、トレーニングデータなしで、すぐに使用できるモデルを構築できます。数秒でモデルをデプロイおよび反復処理でき、トレーニングデータの準備、データのラベル付け、モデルのトレーニングと微調整にかかる時間と費用を削減できます。ニューヨーク市に本社を置くDirectAIは、ベンチャーキャピタルの支援を受けており、現実世界におけるAIの使用方法に革新をもたらしています。
モデルトレーニングとデプロイ
45.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
40.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
39.7K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.4K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.9K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
39.7K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.6K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M