%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
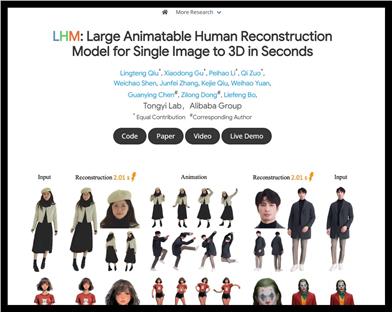
LHM
LHM(大規模アニメーション可能人間再構築モデル)は、マルチモーダル?トランスフォーマーアーキテクチャを利用して高精細な3Dアバターを再構築し、単一画像からアニメーション可能な3D人間像の生成をサポートします。本モデルは、衣服の形状とテクスチャを詳細に保持でき、特に顔の識別とディテールの復元において優れた性能を発揮し、3D再構築精度が高い要求されるアプリケーションシーンに適しています。
3Dモデリング
44.7K
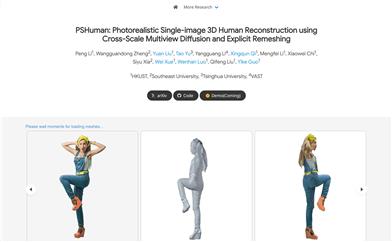
Pshuman
PSHumanは、多視点拡散モデルと明示的再構成技術を用いて、一枚の写真からリアルな3D人体モデルを再構築する革新的なフレームワークです。この技術は、複雑な自己遮蔽問題に対処し、生成された顔の詳細において幾何学的歪みを回避できる点が重要です。PSHumanは、クロススケール拡散モデルによってグローバルな全身形状とローカルな顔の特徴を統合的にモデル化することで、ディテールが豊富でアイデンティティの特徴を維持した新たな視点からの生成を実現します。さらに、SMPL-Xなどのパラメトリックモデルが提供するボディープライオリティによって、異なる人体姿勢でのクロスビューボディ形状の一貫性を強化しています。PSHumanの主な利点として、幾何学的ディテールの豊かさ、テクスチャの忠実度の高さ、および汎化能力の強さが挙げられます。
3Dモデル
70.1K
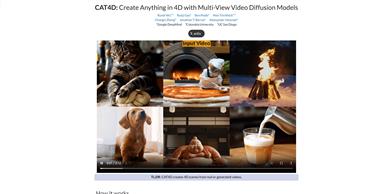
CAT4D
CAT4Dは、単眼ビデオから多視点ビデオ拡散モデルを用いて4Dシーンを生成する技術です。単眼ビデオを入力として、多視点ビデオに変換し、動的な3Dシーンを再構築します。この技術の重要性は、単一視点のビデオデータから三次元空間と時間の情報を完全に抽出し、再構築できる点にあります。仮想現実、拡張現実、3Dモデリングなどの分野に強力な技術サポートを提供します。製品背景情報によると、CAT4DはGoogle DeepMind、コロンビア大学、UCサンディエゴの研究者によって共同開発され、最先端の研究成果を実用化に移した事例です。
3Dモデリング
50.5K
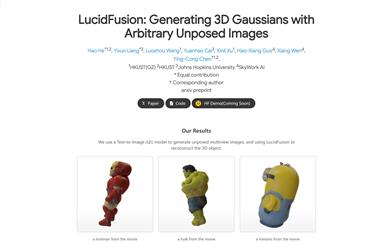
Lucidfusion
LucidFusionは、ポーズのない、疎で、任意の数の多視点画像から高解像度の3Dガウスを生成するための、柔軟なエンドツーエンドのフィードフォワードフレームワークです。この技術は、相対座標マップ(RCM)を利用して異なるビュー間の幾何学的特徴を整合させることで、3D生成において高い適応性を備えています。LucidFusionは、元の単一画像から3Dへのプロセスとシームレスに統合され、512x512解像度の詳細な3Dガウスを生成し、幅広い用途に適しています。
3Dモデリング
51.6K

Long LRM
Long-LRMは、一連の入力画像から大規模シーンを再構築するための3Dガウス再構築モデルです。このモデルは、960x540ピクセルの解像度を持つ32枚のソース画像を1.3秒で処理し、単一のA100 80G GPU上で動作します。最新のMamba2モジュールと従来のTransformerモジュールを組み合わせ、効率的なトークンマージとガウシアン刈り込みの手順により、品質を維持しながら効率性を向上させています。従来のフィードフォワードモデルと比較して、Long-LRMはシーンの一部ではなく、一度にシーン全体を再構築できます。DL3DV-140やTanks and Templesなどの大規模シーンデータセットでは、Long-LRMの性能は最適化ベースの方法と匹敵し、同時に効率性は2桁向上しています。
3Dモデリング
51.3K

Flex3d
Flex3Dは、一枚の写真またはテキストプロンプトから高品質な3Dアセットを生成する2段階のプロセスです。この技術は3D再構築分野における最新の進歩を代表しており、3Dコンテンツ生成の効率と品質を大幅に向上させることができます。Flex3Dの開発はMetaの支援を受けており、チームメンバーは3D再構築とコンピュータビジョンの分野で豊富な経験を持っています。
AI 3Dツール
59.3K
Viewcrafter
ViewCrafterは、ビデオ拡散モデルの生成能力と、点ベース表現による粗い3D手がかりを利用して、単一または疎な画像から汎用シーンの高精細な新視点合成を行う革新的な手法です。本手法は、反復的なビュー合成戦略とカメラ軌跡計画アルゴリズムによって、3D手がかりと新視点のカバー範囲を段階的に拡大し、新視点生成範囲の拡大を実現します。ViewCrafterは、3D-GS表現の最適化による没入型体験とリアルタイムレンダリング、シーンレベルのテキストから3Dへの生成によるより想像力豊かなコンテンツ制作など、様々な用途を促進します。
AI画像生成
56.3K

Omnire
OmniReは、デバイスログを用いて高保真な動的都市景観を効率的に再構築するための包括的な手法です。ガウス表現に基づく動的神経シーングラフの構築と、車両、歩行者、自転車乗りなどの様々な動的行動者をシミュレートするための複数の局所正規空間の構築により、シーン内の様々なオブジェクトを包括的に再構築します。OmniReは、シーンに存在する様々なオブジェクトを包括的に再構築し、その後、全ての参加者のリアルタイム参加による再構築シーンのシミュレーションを可能にします。Waymoデータセット上での広範な評価により、OmniReは定量的にも定性的にも、従来最先端の手法を大幅に凌駕することが示されました。
AI画像生成
49.1K
高品質新製品
Genwarp
GenWarpは、単一の画像から新しい視点の画像を生成するためのモデルです。これは、意味を維持する生成的な変形フレームワークを通じて、テキストから画像への生成モデルがどこを変形し、どこで生成するかを学習できるようにします。本モデルは、既存手法の限界を解決するために、クロスビューアテンションとセルフアテンションを強化し、条件付き生成モデルをソースビュー画像に適用し、幾何学的変形信号を取り入れることで、様々なシナリオにおける性能を向上させています。
AI画像生成
62.1K
Viewdiff
ViewDiffは、事前学習済みのテキスト画像変換モデルを事前知識として利用し、現実世界のデータから多視点整合性の高い画像を生成する手法です。U-Netネットワークに3Dボリュメトリックレンダリングとクロスフレームアテンション層を追加することで、単一のノイズ除去プロセスで3D整合性の高い画像生成を実現します。既存手法と比較して、ViewDiffはより優れた視覚的品質と3D整合性を備えた結果を提供します。
AI画像生成
83.4K

GRM
GRMは大規模な再構築モデルであり、疎なビュー画像から0.1秒で3Dアセットを復元し、8秒以内で生成できます。これは、Transformerベースのフィードフォワードモデルであり、多様なビュー情報を効率的に融合し、入力ピクセルを高精度に位置合わせされたガウス分布に変換します。これらのガウス分布は、シーンを表す密集した3Dガウス分布集合に逆投影できます。当社のTransformerアーキテクチャと3Dガウス分布の使用方法は、拡張性が高く効率的な再構築フレームワークを可能にします。数多くの実験結果から、当社の方法は再構築の品質と効率において他の代替案を上回ることが示されています。また、既存の多視点拡散モデルと組み合わせることで、テキストから3D、画像から3Dなどの生成タスクにおけるGRMの可能性も示しています。
AI画像生成
58.2K
Triposr
TripoSRは、Stability AIとTripo AIが共同開発した3Dオブジェクト再構築モデルです。一枚の画像から1秒未満で高品質な3Dモデルを生成できます。低推論予算で動作し、GPUは不要なため、幅広いユーザーやアプリケーションシナリオに適しています。モデルの重みとソースコードはMITライセンスで公開されており、商用利用、個人利用、研究利用が可能です。
AIモデル
417.9K

Visfusion
VisFusionは、ビデオデータを用いてオンラインで3Dシーンを再構築する技術です。ビデオからリアルタイムで3次元環境を抽出?再構築できます。コンピュータビジョンと深層学習を組み合わせることで、正確な3Dモデル作成のための強力なツールを提供します。
AI 3Dツール
67.1K
PRISMA
PRISMAは、あらゆる画像または動画から多様な推論を実行できるコンピューテーショナルフォトグラフィパイプラインです。プリズムを通して光線が異なる波長に分散されるように、このパイプラインは画像を拡張し、3D再構築やリアルタイムの後処理操作に使用できるデータに変換します。単眼深度推定(MiDAS v3.1、ZoeDepth、Marigold、PatchFusion)、光流(RAFT)、セグメンテーションマスク(mmdet)、カメラ姿勢推定(colmap)など、様々なアルゴリズムとオープンソースの事前学習済みモデルを統合しています。結果は入力ファイルと同じ名前のフォルダに保存され、各バンドは.pngまたは.mp4ファイルとして個別に保存されます。動画の場合、最終段階で疎な再構築を試み、NeRF(例:NVidiaのInstant-ngp)やガウス拡散モデルの学習に使用できます。推論された深度情報は、LYGIAのヒートマップGLSL/HLSLサンプラーでリアルタイムに復号化できるヒートマップとしてデフォルトで出力され、光流はHUE(角度)と彩度でエンコードされ、LYGIAの光流GLSL/HLSLサンプラーでリアルタイムに復号化できます。
AI画像生成
58.0K
SIFU
SIFUは、側視画像を用いて高品質な3D衣服仮想人物モデルを再構築する手法です。その核心的な革新点は、側視画像に基づいた新しい陰関数アプローチを提案することであり、これにより特徴抽出の強化と幾何精度の向上を実現します。さらに、SIFUは3D整合性の高いテクスチャ最適化プロセスを導入し、テクスチャ品質の大幅な向上を図り、テキストから画像への拡散モデルを用いたテクスチャ編集を可能にしています。SIFUは複雑なポーズやゆったりとした衣服の処理に優れており、実用的ソリューションとして理想的です。
AI画像生成
67.9K
Human101
Human101は、単一視点から人体を高速に再構築するフレームワークです。100秒以内に3Dガウスモデルの学習を完了し、フレーム毎の高ス属性を事前に保存することなく、1024解像度の画像を60FPS以上でレンダリングできます。Human101のパイプラインは以下の通りです。まず、単一視点のビデオから2D人体姿勢を抽出します。次に、姿勢駆動型の3Dシミュレータを用いて、対応する3D骨格アニメーションを生成します。最後に、このアニメーションに基づいて時間的に関連付けられた3Dガウスモデルを構築し、リアルタイムレンダリングを行います。
AI画像生成
107.9K

Gaussian SLAM
Gaussian SLAMは、RGBDデータストリームからレンダリング可能な3Dシーンを再構築できます。これは、写真レベルのリアルさで現実世界のシーンを再構築できる最初のニューラルRGBD SLAM手法です。3Dガウスをシーン表現の基本単位として利用することで、従来手法の限界を克服しました。従来の3Dガウスは単眼設定では使いにくいことが分かりました。正確な幾何学的情報を符号化できず、単眼順序付けによる教師あり学習による最適化も困難です。幾何学的情報を符号化するように従来の3Dガウスを拡張し、それを成長させ最適化する新しいシーン表現手法を設計することで、速度や効率性を犠牲にすることなく、現実世界のデータセットを再構築?レンダリングできるSLAMシステムを提案しました。Gaussian SLAMは、現実世界のシーンを写真レベルのリアルさで再構築?レンダリングできます。一般的な合成データセットと現実世界のデータセットで手法を評価し、最先端の他のSLAM手法と比較しました。最後に、得られた最終的な3Dシーン表現は、効率的なガウシアン?スプラッシュ?レンダリングによりリアルタイムレンダリングが可能であることを示しました。
3Dモデリング
47.7K
Nvas3d
NVAS3dは、複数の未知の音源を含むシーン内の任意の位置の音を推定するためのプロジェクトです。複数のマイクによる録音とシーンの3Dジオメトリおよび材質情報を利用することで、新視点音響合成を実現しています。
AI音声増強器
51.3K

NVIDIA Neuralangelo
Neuralangeloは、NVIDIA Researchが開発した、ニューラルネットワークを用いた3D再構築AIモデルです。2Dビデオクリップから詳細な3D構造を生成し、リアルな仮想建築物や彫刻などのオブジェクトを作成できます。屋根瓦、ガラス窓、滑らかな大理石など、複雑な素材のテクスチャを正確に抽出します。クリエイティブプロフェッショナルは、これらの3Dオブジェクトをデザインアプリケーションにインポートしてさらに編集し、アート、ビデオゲーム開発、ロボティクス、産業用デジタルツインなどの分野で活用できます。Neuralangeloの3D再構築能力は、クリエイターがデジタル世界で現実世界を再現する上で大きな助けとなります。最終的には、開発者が詳細なオブジェクト(小さな彫刻から巨大な建物まで)を仮想環境にインポートし、ビデオゲームや産業用デジタルツインなどのアプリケーションで利用できるようになります。
AI 3Dツール
66.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.1K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.0K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M