%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Text-to-Video
Viddo
Viddo AI is an AI-powered video generator that converts text or images into stunning videos. It features multiple functions including text-to-video, image-to-video, and more, making it a must-have tool for endless creativity.
Text-to-Video
38.1K
Vexub
Vexub is a tool that uses artificial intelligence technology to quickly generate high-quality videos. It helps users convert text and audio materials into beautiful video works, improving video production efficiency. It is suitable for individual creators and business users. Vexub aims to provide simple and easy-to-use video creation tools, making creation easier and more efficient. The pricing includes Basic Edition, Professional Edition, and Enterprise Edition to flexibly meet different user needs.
Artificial Intelligence
38.6K

Pixverse MCP
PixVerse-MCP is a tool that allows users to access PixVerse's latest video generation models through applications that support the Model Context Protocol (MCP). This product offers features such as text-to-video generation and is suitable for creators and developers to generate high-quality videos anywhere. The PixVerse platform requires API credits, which users need to purchase themselves.
Video Production
40.3K
Fresh Picks

Vidu Q1
Vidu Q1, launched by Shengshu Technology, is a domestically produced video generation large language model designed for video creators. It supports high-definition 1080p video generation and features cinematic camera movements and start/end frame functionality. This product ranked first in the VBench-1.0 and VBench-2.0 evaluations, offering exceptional value for money at only one-tenth the price of competitors. It is suitable for film, advertising, animation, and other fields, significantly reducing production costs and improving creative efficiency.
Video Production
38.6K
Wan 2.1 AI
Wan 2.1 AI is an open-source large-scale video generation AI model developed by Alibaba. It supports text-to-video (T2V) and image-to-video (I2V) generation, capable of transforming simple input into high-quality video content. This model is significant in the field of video generation, greatly simplifying the video creation process, lowering the creation threshold, improving creation efficiency, and providing users with a wide variety of video creation possibilities. Its main advantages include high-quality video generation effects, smooth presentation of complex actions, realistic physical simulation, and rich artistic styles. Currently, this product is fully open-source, and users can use its basic functions for free. It is highly practical for individuals and businesses that have video creation needs but lack professional skills or equipment.
Video Production
68.4K
Wan2gp
Wan2GP is an improved version based on Wan2.1, aiming to provide an efficient and low-memory video generation solution for low-configuration GPU users. The model, through optimized memory management and accelerated algorithms, enables ordinary users to quickly generate high-quality video content on consumer-grade GPUs. It supports multiple tasks, including text-to-video, image-to-video, and video editing, and features a powerful video VAE architecture capable of efficiently handling 1080P videos. The emergence of Wan2GP lowers the barrier to entry for video generation technology, allowing more users to easily learn and apply it to real-world scenarios.
Video Production
74.2K
Wan2.1 T2V 14B
Wan2.1-T2V-14B is an advanced text-to-video generation model based on a diffusion transformer architecture, incorporating innovative spatiotemporal variational autoencoders (VAEs) and large-scale data training. It generates high-quality video content at various resolutions, supports both Chinese and English text input, and surpasses existing open-source and commercial models in performance and efficiency. This model is suitable for scenarios requiring efficient video generation, such as content creation, advertising production, and video editing. Currently, this model is freely available on the Hugging Face platform to promote the development and application of video generation technology.
Video Production
146.6K
Flashvideo
FlashVideo is a deep learning model focused on efficient, high-resolution video generation. Its staged generation strategy first creates a low-resolution video, which is then enhanced to high resolution using an upscaling model. This approach significantly reduces computational costs while maintaining detail. This technology holds significant promise for video generation, especially in scenarios requiring high-quality visual content. FlashVideo is suitable for a variety of applications, including content creation, advertising production, and video editing. Its open-source nature allows researchers and developers to customize and extend its functionality.
Video Production
54.4K
STAR
STAR is an innovative video super-resolution technology that addresses the issue of over-smoothing found in traditional GAN methods by combining text-to-video diffusion models with video super-resolution. This technology not only recovers video details but also maintains temporal and spatial consistency, making it suitable for various real-world video scenarios. STAR was jointly developed by Nanjing University and ByteDance, boasting high academic value and application prospects.
Video Production
59.3K
Videovaeplus
This is a video variational autoencoder (VAE) designed to reduce video redundancy and facilitate efficient video generation. The model extends image VAE to 3D VAE, discovering that this results in motion blur and detail distortion, prompting the introduction of time-aware spatial compression for better encoding and decoding of spatial information. Additionally, the model incorporates a lightweight motion compression model for further temporal compression. By utilizing inherent textual information from text-to-video datasets and incorporating text guidance into the model, it significantly enhances reconstruction quality, particularly in detail retention and temporal stability. The model also improves its versatility through joint training on images and videos, enhancing both reconstruction quality and capabilities for auto-encoding images and videos. Extensive evaluations indicate that this approach outperforms recent strong baselines.
Video Production
45.3K
English Picks
Pollo AI
Pollo AI is an innovative AI video generator that allows users to effortlessly create stunning videos. Users can quickly generate videos with specific styles and content by using simple text prompts or static images. Pollo AI stands out due to its user-friendly interface, a wide range of customization options, and high-quality output, making it a preferred choice for both beginners and experienced creators. It supports not only text-to-video generation but also creates videos based on image content and user needs, featuring various templates including an AI-powered hugging video generator that easily produces heartwarming hug videos. With its rapid video generation capabilities, high-quality output, and ease of use without technical video editing skills, Pollo AI offers users limitless creative possibilities.
Video Production
123.6K

Consisid
ConsisID is a frequency decomposition-based identity-preserving text-to-video generation model that generates high-fidelity videos consistent with the input textual descriptions using identity control signals in the frequency domain. This model does not require tedious fine-tuning for different cases and is capable of maintaining consistency in character identity within the generated videos. The introduction of ConsisID advances video generation technology, particularly in terms of streamlined processes and frequency-aware identity preservation control schemes.
Video Production
55.5K
Allegro TI2V
Allegro-TI2V is a text-to-image-to-video generation model that creates video content based on user-provided prompts and images. The model is recognized for its open-source nature, diverse content creation capabilities, high-quality outputs, compact efficient model parameters, and support for various precision and GPU memory optimizations. It represents cutting-edge advancements in AI technology for video generation, holding significant technical value and commercial application potential. The Allegro-TI2V model is available on the Hugging Face platform under the Apache 2.0 open-source license, allowing users to download and use it for free.
Video Production
65.4K
Viral Video
Viral Video is an online platform that uses artificial intelligence technology to help users quickly create viral videos. It simplifies the video production process through features like text-to-video conversion, text-to-speech conversion, AI video editing, and AI scene generation, reducing costs and enhancing the attractiveness and dissemination potential of videos. The platform is particularly suitable for content creators, marketers, and social media operators, helping them produce high-quality video content faster and at a lower cost to gain more attention and engagement on social media.
Video Production
64.6K
English Picks
Mochi 1
Mochi 1 is an open-source video generation model introduced by Genmo as a research preview version, aiming to address fundamental issues in the current AI video landscape. The model is renowned for its unparalleled motion quality, exceptional prompt-following capabilities, and its ability to bridge the uncanny valley, generating coherent and fluid human actions and expressions. Mochi 1 was developed in response to the growing demand for high-quality video content, particularly in the gaming, film, and entertainment industries. A free trial is currently available, though detailed pricing information is not provided on the page.
Video Production
63.8K
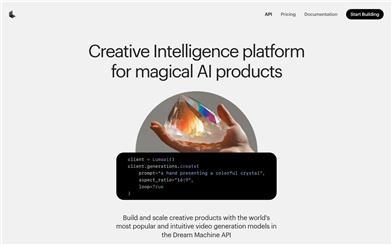
Dream Machine API
Dream Machine API is a creative intelligence platform that offers a range of advanced video generation models. With intuitive APIs and open-source SDKs, users can build and expand creative AI products. The platform features capabilities such as text-to-video, image-to-video, keyframe control, expansion, looping, and camera control, designed to help users collaborate with creative intelligence to create better content. The launch of Dream Machine API aims to enrich visual exploration and creativity, allowing more ideas to be tested, better narratives to be constructed, and enabling diverse stories to be told by those who previously found it difficult.
AI video generation
58.8K
Chinese Picks
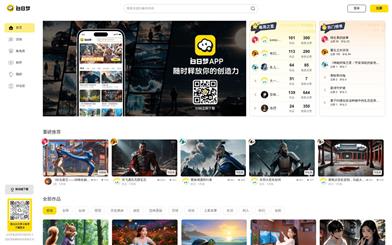
Dreamcloud
DreamCloud AI is an innovative Text-to-Video AIGC creation platform that leverages artificial intelligence technology to enable users to effortlessly generate high-quality video content. The platform offers functionalities like text-to-video, dynamic visuals generation, and AI character generation, while ensuring consistency between characters and scenes, greatly enhancing the diversity and professionalism of video creation.
Video Production
116.2K
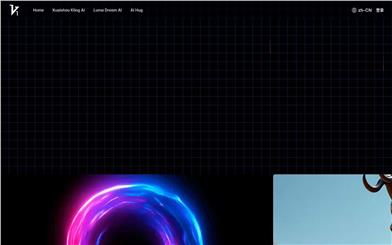
Vidful.ai
Vidful.ai is an AI-powered online video generator that utilizes advanced algorithms to quickly convert text and images into high-quality video content. The product integrates technologies from Kuaishou's Kling AI and Luma AI Dream Machine, offering realistic motion effects and cinematic-level video quality, simplifying the video production process so users can create professional videos without specialized editing skills. Vidful.ai is available for free online, catering to users across various fields including marketing, education, social media creation, and e-commerce.
Video Production
152.4K
Cogvideo
CogVideo is a text-to-video generation model developed by a team at Tsinghua University, which leverages deep learning technology to convert text descriptions into video content. This technology holds extensive prospects for applications in video content creation, education, entertainment, and more. With large-scale pre-training, the CogVideo model can generate videos that align with the text description, providing a novel automated approach to video production.
AI video generation
64.6K
Cogvideox 5B
CogVideoX is an open-source video generation model developed by a team from Tsinghua University. It supports generating videos from text descriptions and offers various models, including entry-level options and larger models, to meet different quality and cost requirements. The model supports multiple precisions, including FP16 and BF16, and it is recommended to use the same precision as during model training for inference. The CogVideoX-5B model is particularly suited for scenarios requiring the generation of high-quality video content, such as filmmaking, game development, and advertising creativity.
AI video generation
71.5K
Dream Machine AI.online
Dream Machine AI is an AI platform that leverages cutting-edge technology to convert text and images into high-quality videos. Powered by Luma AI, it utilizes advanced transformation models to quickly generate physically accurate and coherent video content with complex spatiotemporal motion. Key advantages include high generation speed, realistic and coherent motion, strong character consistency, and natural camera movement. The product is positioned to provide a fast and efficient video generation solution for video creators and content producers.
Video Production
86.7K
Fresh Picks
Cogvideox
CogVideoX is an open-source video generation model that shares lineage with commercial models, enabling the generation of video content through textual descriptions. It represents the latest advancements in text-to-video generation technology, capable of producing high-quality videos applicable in various fields including entertainment, education, and commercial promotion.
AI Video Generation
75.3K
Asyncdiff
AsyncDiff is a method for accelerating diffusion models through asynchronous denoising parallelization. It divides the noise prediction model into multiple components and distributes them across different devices, enabling parallel processing. This approach significantly reduces inference latency while having a minimal impact on generation quality. AsyncDiff supports a variety of diffusion models, including Stable Diffusion 2.1, Stable Diffusion 1.5, Stable Diffusion x4 Upscaler, Stable Diffusion XL 1.0, ControlNet, Stable Video Diffusion, and AnimateDiff.
AI image generation
51.9K
Kling AI
Developed by Kuaishou Technology, Kling AI is a text-to-video generation model that can produce highly realistic videos based on text prompts. It boasts efficient video generation capabilities, generating up to 2 minutes of 30 frames-per-second video, along with advanced technologies like a 3D Spatiotemporal Joint Attention mechanism and physics-world simulation, giving it a significant competitive edge in the AI video generation field.
AI Video Generation
96.3K
Sharegpt4video
The ShareGPT4Video series aims to promote video understanding in large video-language models (LVLMs) and video generation in text-to-video models (T2VMs) through dense and precise captions. The series includes:
1) ShareGPT4Video, a dense video caption dataset of 40K GPT4V annotations, developed through carefully designed data filtering and annotation strategies.
2) ShareCaptioner-Video, an efficient and powerful video captioning model for any video, trained on its 4.8M high-quality aesthetic video dataset.
3) ShareGPT4Video-8B, a simple yet excellent LVLM that achieved top performance on three advanced video benchmark tests.
AI video generation
73.4K
Fresh Picks
Videotetris
VideoTetris is a novel framework that achieves text-to-video generation, particularly suitable for handling complex video generation scenarios involving multiple objects or dynamically changing object quantities. The framework utilizes spatiotemporal combination diffusion technology to precisely follow complex textual semantics and achieves this by operating on and combining the spatial and temporal attention maps of denoising networks. Furthermore, it introduces a novel reference frame attention mechanism to enhance the consistency of autoregressive video generation. VideoTetris has achieved impressive qualitative and quantitative results in combined text-to-video generation.
AI video generation
83.6K
Fresh Picks
Motionclone
MotionClone is a training-free framework that allows for motion cloning from reference videos to control text-to-video generation. It utilizes a temporal attention mechanism to represent the motion in a reference video during video inversion and introduces a主 temporal attention guidance to alleviate the influence of noise or very subtle motions in the attention weights. Additionally, to assist the generation model in synthesizing reasonable spatial relationships and enhancing its prompt-following ability, a position-aware semantic guidance mechanism is proposed, leveraging the foreground rough locations from the reference video and original classifier-free guidance features.
AI video generation
69.3K
Follow Your Pose
Follow-Your-Pose is a text-to-video generation model that utilizes pose information and text descriptions to generate editable and controllable pose-based character videos. This technology holds significant application value in the field of digital character creation, addressing the limitations of a lack of comprehensive datasets and video generation prior models. Through a two-stage training scheme, combined with a pre-trained text-to-image model, it has achieved pose-controlled video generation.
AI video generation
101.3K
Open Sora Plan V1.1.0
Open-Sora-Plan is a text-to-video generation model developed by the Peking University Tuple Team. It was first released in April 2024 with its v1.0.0 version, gaining widespread recognition in the text-to-video generation field due to its simple and efficient design and significant performance. The v1.1.0 version has made significant improvements to video generation quality and duration, including optimized compression of visual representations, higher generation quality, and extended video generation capabilities. The model employs an optimized CausalVideoVAE architecture, which offers greater performance and higher inference efficiency. Additionally, it maintains the minimalist design and data efficiency of v1.0.0, and performs similarly to the Sora base model, indicating a consistent evolution pattern with the expansion principles demonstrated by Sora.
AI video generation
127.5K
Lumina T2X
Lumina-T2X is an advanced text-to-any-modal generation framework that can convert text descriptions into vivid images, dynamic videos, detailed multi-view 3D images, and synthetic speech. The framework employs a stream-based large diffusion transformer (Flag-DiT) architecture, supports models up to 700 million parameters, and can extend sequence lengths to 128,000 tokens. Lumina-T2X integrates image, video, 3D object multi-view, and audio spectrum into a unified spatiotemporal latent token space, enabling the generation of outputs of any resolution, aspect ratio, and duration.
AI image generation
61.3K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.5K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.3K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M