%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Real-time Rendering
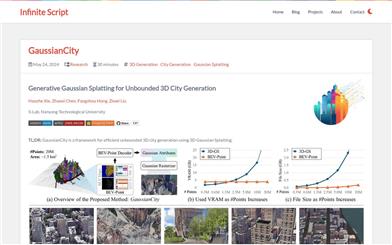
Gaussiancity
GaussianCity is a framework focused on efficiently generating boundless 3D cities, based on 3D Gaussian rendering technology. This technology, through compact 3D scene representation and a spatially aware Gaussian attribute decoder, solves the memory and computational bottlenecks encountered by traditional methods when generating large-scale city scenes. Its main advantage is the ability to quickly generate large-scale 3D cities in a single forward pass, significantly outperforming existing technologies. This product was developed by the S-Lab team at Nanyang Technological University, with the related paper published in CVPR 2025. The code and models have been open-sourced and are suitable for researchers and developers who need to efficiently generate 3D city environments.
3D Modeling
45.5K
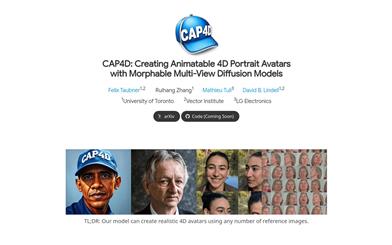
CAP4D
CAP4D is a technology that creates 4D human avatars using Morphable Multi-View Diffusion Models. It can generate images from an arbitrary number of reference images, producing different perspectives and expressions, and adapt them into a 4D avatar that can be controlled with a 3DMM and rendered in real-time. The main advantages of this technology include highly realistic image generation, adaptability across multiple viewpoints, and real-time rendering capabilities. CAP4D is based on the latest advancements in deep learning and image generation, particularly in diffusion models and 3D facial modeling. With its high-quality image generation and real-time rendering capabilities, CAP4D holds broad application prospects in entertainment, game development, and virtual reality. Currently, the technology provides the code for free, but specific commercial applications may require further licensing and pricing agreements.
Digital Person
68.7K

Long Volumetric Video
Long Volumetric Video is a novel technology for reconstructing long voxel videos from multi-view RGB footage. This technique effectively models long voxel videos using a new 4D representation method called Temporal Gaussian Hierarchy, addressing the issues of high memory consumption and slow rendering speeds associated with traditional dynamic view synthesis methods when processing long videos. Key advantages of this technology include low training costs, fast rendering speeds, and minimal storage requirements, making it the first technology capable of efficiently processing minute-scale voxel video data while maintaining high-quality rendering.
Video Production
46.9K
LTXV
LTXV is a real-time AI video generation open-source model launched by Lightricks, representing the latest advancement in video generation technology. LTXV offers scalable long video production capabilities, optimizing GPU and TPU systems to significantly reduce video generation times while maintaining high visual quality. Its unique frame-to-frame learning technology ensures coherence between frames, eliminating flickering and inconsistencies within scenes. This innovation marks a major leap forward for the video production industry, as it not only improves efficiency but also enhances the quality of video content.
Video Generation
130.8K

Uravatar
URAvatar is a novel avatar generation technology that enables the creation of realistic, re-lightable head avatars through smartphone scans under unknown lighting conditions. Unlike traditional methods that estimate reflectance parameters through inverse rendering, URAvatar directly simulates learned radiative transfer, effectively integrating global illumination into real-time rendering. This technology is significant as it can reconstruct head models that appear realistic in multiple environments from a single environmental smartphone scan, enabling real-time driving and re-lighting.
Image Generation
44.2K
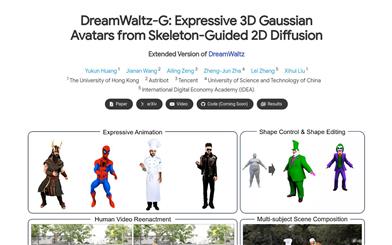
Dreamwaltz G
DreamWaltz-G is an innovative framework designed for generating 3D avatars and expressive full-body animations driven by text. Its core components include skeletal-guided score distillation and blended 3D Gaussian avatar representation. By integrating skeletal control of 3D human templates into a 2D diffusion model, it enhances the consistency of viewpoints and human poses, yielding high-quality avatars while addressing issues such as multiple faces, extra limbs, and blurriness. Moreover, the blended 3D Gaussian avatar representation, which combines neural implicit fields with parameterized 3D meshes, facilitates real-time rendering, stable SDS optimization, and expressive animations. DreamWaltz-G excels in generating and animating 3D avatars, surpassing existing methods in both visual quality and animation expressiveness. This framework also supports various applications, including human video reenactment and multi-subject scene compositions.
AI image generation
49.4K
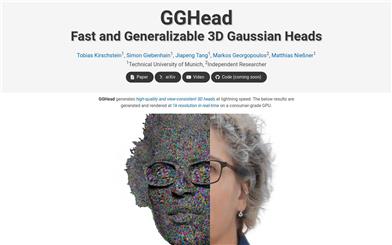
Gghead
GGHead is a 3D Generative Adversarial Network (GAN) based on 3D Gaussian scattering representation, designed to learn 3D head priors from a collection of 2D images. This technology simplifies the prediction process by leveraging the regularity of the UV space of template head meshes to predict a set of 3D Gaussian attributes. Key advantages of GGHead include high efficiency, high-resolution generation, full 3D consistency, and real-time rendering capabilities. It enhances the geometric fidelity of generated 3D heads through a novel total variation loss, ensuring that neighboring rendered pixels originate from close Gaussian points in UV space.
AI image generation
56.3K

Shusheng: Skyline LandMark
Shusheng: Skyline LandMark is a real-world 3D model based on NeRF technology, achieving 4K HD training over an extensive area of 100 square kilometers, with capabilities for real-time rendering and free editing. This technology represents a new pinnacle in city-scale 3D modeling and rendering, boasting high efficiency for training and rendering, making it a robust tool for urban planning, architectural design, and virtual reality.
3D Modeling
54.4K

Xhand
XHand is a model developed by Zhejiang University for real-time generation of high-detail expressive hand avatars. It creates these avatars using multi-view videos and leverages MANO pose parameters to generate high-detail meshes and renderings, achieving real-time rendering in various poses. XHand offers significant advantages in image realism and rendering quality, particularly in augmented reality and gaming fields, producing lifelike hand images instantaneously.
AI Head Image Generation
54.6K
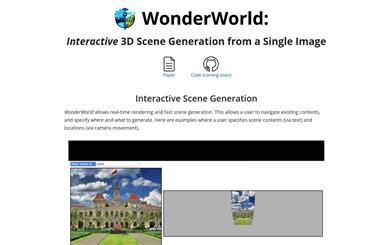
Wonderworld
WonderWorld is an innovative 3D scene expansion framework that allows users to explore and shape virtual environments based on a single input image and user-specified text. Through fast Gaussian voxel and guided diffusion depth estimation methods, it significantly reduces computing time and generates geometry-consistent expansions, resulting in 3D scene generation times of less than 10 seconds. It supports real-time user interaction and exploration. This opens up possibilities for rapidly generating and navigating immersive virtual worlds in fields like virtual reality, gaming, and creative design.
AI image generation
60.2K
Fresh Picks

E3gen
E3Gen is a novel digital avatar generation method that can generate high-fidelity avatars in real time. It features detailed clothing wrinkles and supports comprehensive control over multiple perspectives and full-body poses, as well as attribute transfer and local editing. By encoding 3D Gaussian into a structured 2D UV space, E3Gen addresses the incompatibility issue between 3D Gaussian and current generation processes and explores the expressive animation of 3D Gaussian in training involving multiple subjects.
AI head image generation
56.6K
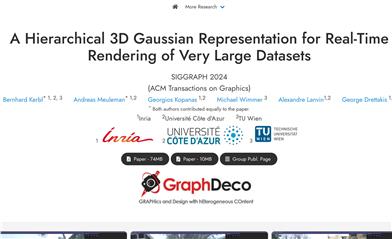
A Hierarchical 3D Gaussian Representation For Real Time Rendering Of Very Large Datasets
This research proposes a novel hierarchical 3D Gaussian representation method for real-time rendering of very large datasets. By utilizing 3D Gaussian splatting technology, it offers excellent visual quality, rapid training, and real-time rendering capabilities. Through a hierarchical structure and effective Level-of-Detail (LOD) solutions, it can efficiently render distant content and achieve smooth transitions between levels. The technology adapts to available resources, trains large scenes using a divide-and-conquer approach, and integrates them into a hierarchical structure that can be further optimized to enhance the visual quality of Gaussian merging into intermediate nodes.
3D Modeling
69.8K
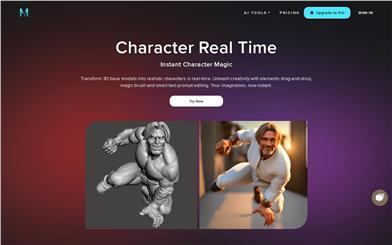
Museclip.ai
Museclip is a real-time character design platform based on 3D models, equipped with smart editing, magic pen, and text prompt features. It can transform 3D character base models into lifelike characters in seconds, significantly enhancing the efficiency of character design. Its key advantages include real-time rendering technology, fast customization, an intelligent and straightforward design process, and an expansive creative freedom for users.
AI design tools
73.1K

Gauhuman
GauHuman is a 3D human model based on Gaussian diffusion. It can complete training in a short time (1-2 minutes) and provide real-time rendering (up to 189 FPS). Compared with existing NeRF-based implicit representation modeling frameworks, which require hours of training and seconds to render each frame, GauHuman offers significant advantages in efficiency. GauHuman encodes Gaussian diffusion in the normal space and utilizes Linear Blend Skinning (LBS) to convert the 3D Gaussian from normal space to pose space. In this process, an effective pose and LBS refinement module is designed to learn the details of the 3D human body at a negligible computational cost. Furthermore, GauHuman achieves fast optimization through 3D human body prior initialization and pruning of 3D Gaussian, as well as split/clone operations guided by KL divergence, and a novel merging operation for further acceleration.
AI Model
131.4K

Bakedavatar
BakedAvatar is a novel representation for real-time neural avatar synthesis, deployable in a standard polygonal rasterization pipeline. The method extracts deformable multi-layer meshes from learned head iso-surfaces and computes appearance variations related to expression, pose, and viewpoint that can be baked into static textures, enabling real-time 4D avatar synthesis. We propose a three-stage neural avatar synthesis pipeline, including learning continuous deformation, manifold, and radiance fields, extracting layered meshes and textures, and refining texture details via differential rasterization. Experiments demonstrate that our representation achieves comparable results to other state-of-the-art methods while significantly reducing inference time. We further showcase diverse avatar synthesis results generated from single-eye video, including view synthesis, facial re-enactment, expression editing, and pose editing, all at interactive frame rates.
AI head portrait generation
70.1K
Deblurring 3D Gaussian Splatting
3Deblurring 3D Gaussian Splatting is a novel neural field deblurring framework based on a recently proposed rasterization method, incorporating 3D Gaussian and rasterization. Utilizing small multi-layer perceptrons (MLPs), this product can reconstruct detailed, clear images from blurry images simultaneously with real-time rendering. The product increases point cloud density during training by employing a K-Nearest Neighbors (KNN) algorithm to add extra points and applies loose pruning to 3D Gaussian based on relative depth, preserving more 3D Gaussian information. Multiple experiments have validated the effectiveness of this product in deblurring.
AI image enhancement
72.3K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.6K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.9K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
45.3K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
44.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.2K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M