%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

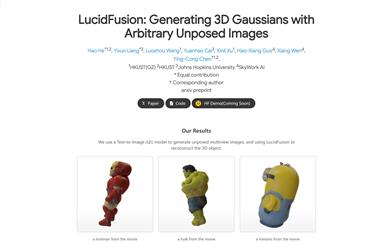
Lucidfusion
Overview :
LucidFusion is a flexible end-to-end feedforward framework designed for generating high-resolution 3D Gaussians from unposed, sparse, and any number of multi-view images. This technology uses Relative Coordinate Maps (RCM) to align geometric features between different views, providing a high degree of adaptability for 3D generation. LucidFusion integrates seamlessly with traditional single-image-to-3D processes, producing detailed 3D Gaussians at 512x512 resolution suitable for a wide range of applications.
Target Users :
The target audience includes 3D modelers, visual effects artists, game developers, and researchers. LucidFusion is particularly suited for professionals who need to quickly generate high-quality 3D models from multi-angle images due to its high flexibility and adaptability. Additionally, it serves as a powerful tool for researchers focusing on complex scene reconstruction and analysis.
Use Cases
Reconstructing the 3D model of Iron Man from multiple angles in a movie using LucidFusion.
3D reconstruction of the Hulk character extracted from a film, utilizing LucidFusion for post-production.
Creating a 3D model of a Russian nesting doll for a cultural exhibition using LucidFusion technology from images taken at different angles.
Features
? Aligns geometric features of different views using Relative Coordinate Maps (RCM) to improve accuracy and consistency in 3D reconstruction.
? An end-to-end feedforward framework that simplifies the process of converting multi-view images into 3D models.
? Supports any number and poses of multi-view images, enhancing the model's applicability and flexibility.
? Seamlessly integrates with single-image-to-3D workflows, improving efficiency and detail in 3D modeling.
? Generates high-resolution 3D Gaussians, reaching resolutions of 512x512 for high-quality 3D visual applications.
? Supports content creation across datasets, showcasing the model's strong adaptability and application potential.
How to Use
1. Prepare a set of unposed multi-view images.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Input these images into the LucidFusion framework.
3. Utilize the Stable Diffusion model within the framework to preprocess the images.
4. The model predicts the RCM representation of the input images.
5. Feed the final feature maps of the VAE into the decoder network to predict the Gaussian parameters.
6. Combine the RCM representation and predicted Gaussian parameters, then pass them to the Gaussian renderer to create new views for supervision.
7. Adjust parameters as needed to optimize the quality and detail of the 3D model.
8. Output the final 3D Gaussian model for further applications or analysis.


Featured AI Tools

Meshpad
MeshPad is an innovative generative design tool that focuses on creating and editing 3D mesh models from sketch input. It achieves complex mesh generation and editing through simple sketch operations, providing users with an intuitive and efficient 3D modeling experience. The tool is based on triangular sequence mesh representation and utilizes a large Transformer model to implement mesh addition and deletion operations. Simultaneously, a vertex alignment prediction strategy significantly reduces computational cost, making each edit take only a few seconds. MeshPad surpasses existing sketch-conditioned mesh generation methods in mesh quality and has received high user recognition in perceptual evaluation. It is primarily aimed at designers, artists, and users who need to quickly perform 3D modeling, helping them create artistic designs in a more intuitive way.
3D modeling
180.2K

Spatiallm
SpatialLM is a large language model designed for processing 3D point cloud data. It generates structured 3D scene understanding outputs, including semantic categories of building elements and objects. It can process point cloud data from various sources, including monocular video sequences, RGBD images, and LiDAR sensors, without requiring specialized equipment. SpatialLM has significant application value in autonomous navigation and complex 3D scene analysis tasks, significantly improving spatial reasoning capabilities.
3D modeling
152.1K