%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Dualgs
Overview :
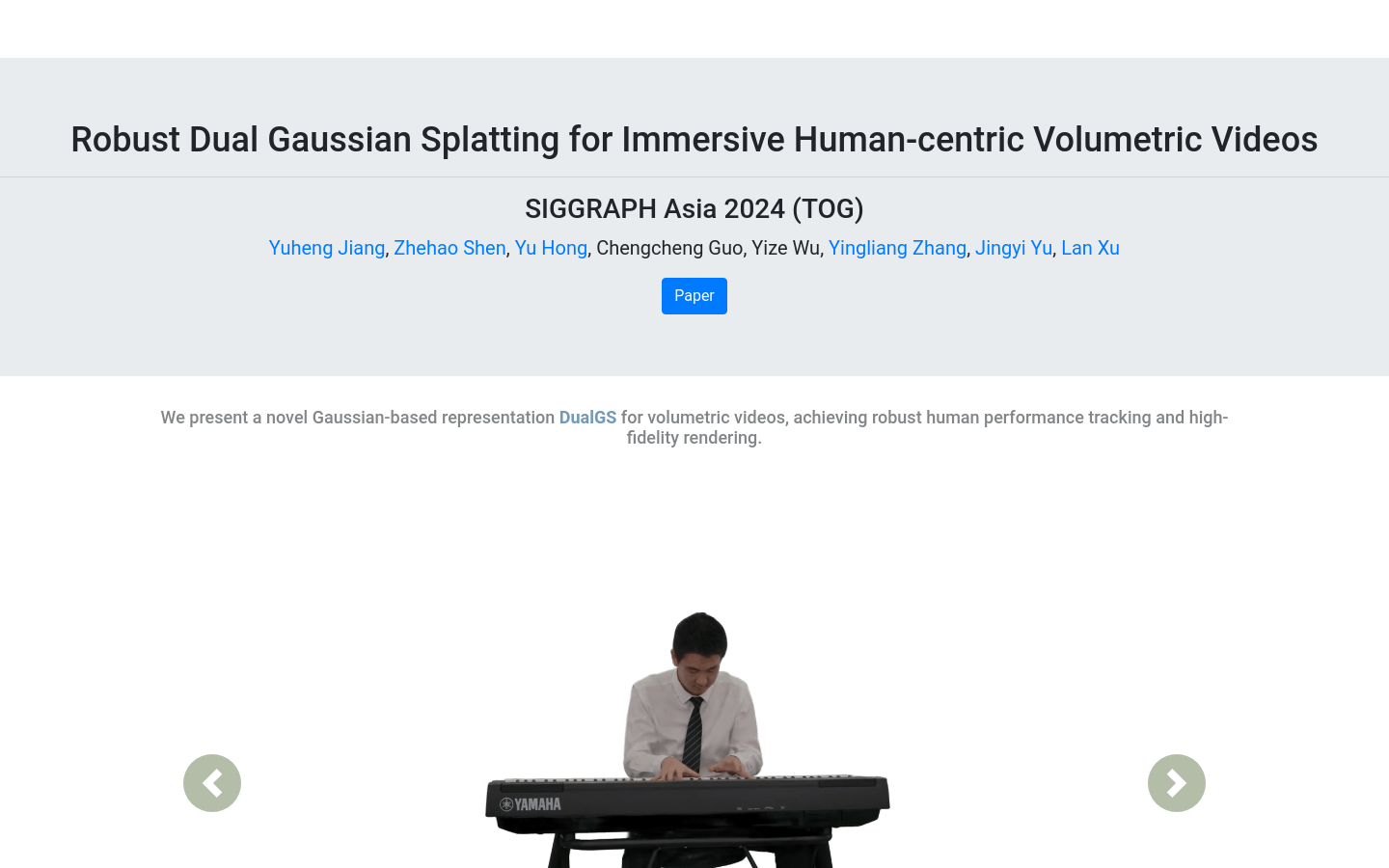
Robust Dual Gaussian Splatting (DualGS) is a novel Gaussian-based volumetric video representation method that captures complex human performances by optimizing joint and skin gaussians, enabling robust tracking and high-fidelity rendering. This technology, showcased at SIGGRAPH Asia 2024, supports real-time rendering on low-end mobile devices and VR headsets, providing a user-friendly and interactive experience. DualGS employs a mixed compression strategy to achieve up to 120 times compression, resulting in more efficient storage and transmission of volumetric video.
Target Users :
The target audience includes 3D graphic designers, VR/AR developers, and video producers who require a volumetric video representation technology capable of delivering immersive experiences and supporting real-time rendering. The DualGS technology, known for its high compression ratio and real-time rendering capability, is particularly suitable for scenarios that demand high-quality visual effects on resource-constrained devices.
Use Cases
Real-time rendering of concert performers in VR headsets
Showcasing high-fidelity sports motion capture videos on mobile devices
Providing realistic human motion previews for special effects in film production
Features
Enables real-time rendering on low-end mobile devices and VR headsets
Utilizes dual Gaussian representation to capture complex human performances
Achieves up to 120 times compression through a mixed compression strategy
Optimizes joint and skin gaussians for robust tracking
Employs a coarse-to-fine strategy for overall motion prediction and fine-grained optimization
Supports multi-view inputs to capture challenging human performances
How to Use
Visit the official DualGS website for more information
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
Download and install the necessary software or plugins to support DualGS technology
Import or create volumetric video content and render it using DualGS technology
Adjust rendering settings to accommodate different devices and performance requirements
Utilize DualGS's compression features to optimize the storage and transmission of video content
Experience immersive volumetric video content on VR headsets or mobile devices















Featured AI Tools

Sora
AI video generation
17.0M

Animate Anyone
Animate Anyone aims to generate character videos from static images driven by signals. Leveraging the power of diffusion models, we propose a novel framework tailored for character animation. To maintain consistency of complex appearance features present in the reference image, we design ReferenceNet to merge detailed features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guidance module to direct character movements and adopt an effective temporal modeling approach to ensure smooth cross-frame transitions between video frames. By extending the training data, our method can animate any character, achieving superior results in character animation compared to other image-to-video approaches. Moreover, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
AI video generation
11.4M