%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Easy Voice Toolkit
Overview :
Easy Voice Toolkit is an AI voice toolkit based on open-source voice projects, providing various automated audio tools including speech model training. The toolkit seamlessly integrates to create a complete workflow, allowing users to selectively use these tools or utilize them in sequence to gradually convert raw audio files into ideal speech models.
Target Users :
The target audience includes developers and researchers who require voice processing, speech recognition, transcription, and voice model training. This toolkit is ideal for users needing speech technology solutions that can be operated in a local environment, as it offers a locally-deployed solution.
Use Cases
Developers use Easy Voice Toolkit to train custom models for speech recognition applications.
Researchers utilize this toolkit for speech transcription to analyze meeting recordings.
Educational institutions employ the toolkit to create speech datasets for teaching materials.
Features
Audio Processing: Offers preprocessing capabilities for audio files.
Speech Recognition: Converts speech into text.
Speech Transcription: Transcribes recorded speech into text.
Dataset Creation: Supports SRT format conversion and WAV file splitting.
Model Training: Facilitates training of customized speech models.
Voice Conversion: Enables conversion between different voices.
How to Use
Download and install Python 3.8 or higher.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
Clone the Easy Voice Toolkit repository to your local machine using git.
Install PyTorch and other dependencies based on project requirements.
Install any additional GUI dependencies required for the project.
Run the Run.py file to activate the GUI interface.
Use the GUI to select the desired functionalities for operation.

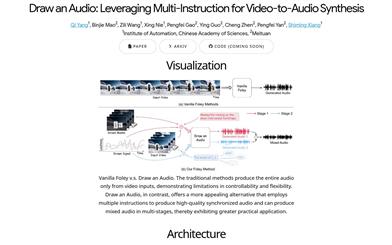




Featured AI Tools

Chattts
ChatTTS is an open-source text-to-speech (TTS) model that allows users to convert text into speech. This model is primarily aimed at academic research and educational purposes and is not suitable for commercial or legal applications. It utilizes deep learning techniques to generate natural and fluent speech output, making it suitable for individuals involved in speech synthesis research and development.
AI speech synthesis
1.4M
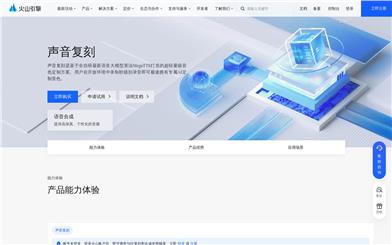
Voice Replica
Voice Replica is a high-efficiency, lightweight audio customization solution. Users can quickly obtain an exclusive AI-customized voice by recording a few seconds of audio in an open environment. Core product advantages include ultra-low cost, ultra-fast replication, high fidelity, and technological leadership. Applicable scenarios include video dubbing, voice assistants, in-car assistants, online education, and audiobooks.
AI speech synthesis
280.7K