%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Generative Rendering: 2D Mesh
Overview :
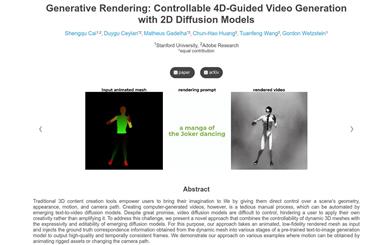
Traditional 3D content creation tools empower users with direct control over scene geometry, appearance, actions, and camera paths, transforming their imagination into reality. However, creating computer-generated videos remains a tedious manual process, which can be automated through emerging text-to-video diffusion models. Despite promising prospects, the lack of control in video diffusion models limits users' ability to apply their own creativity, rather than expanding it. To address this challenge, we propose a novel approach that combines the controllability of dynamic 3D meshes with the expressiveness and editability of emerging diffusion models. Our method takes animated low-fidelity rendering meshes as input and injectsground truth correspondences derived from the dynamic mesh into various stages of a pre-trained text-to-image generation model, resulting in high-quality, temporally consistent frames. We demonstrate our method on various examples, where actions are achieved through animating bound assets or altering camera paths.
Target Users :
Suitable for scenarios requiring controlled video generation, such as animation production and special effects production.
Use Cases
Animation Production: Utilize the generative rendering model to create realistic animation scenes
Special Effects Production: Generate special effects video clips using this model
Post-Production for Film and Television: Apply the model to post-production special effects in movies or television programs
Features
Accepts UV and depth maps from animated 3D scenes as input
Utilizes depth-conditional ControlNet to generate corresponding frames while maintaining consistency through UV correspondences
Initializes noise in the UV space for each object and renders it into each image
For each diffusion step, expands attention is used to extract pre-processed and post-processed attention features for a set of key frames
Projects the post-processed attention features to the UV space and unifies them
Finally, generates all frames by combining the output of the expanded attention with the weighted combination of the key frames' pre-processed features and post-processed features combined with the key frames' UV


Featured AI Tools
Open Sora Plan
Open-Sora-Plan is an open-source project dedicated to replicating OpenAI's Sora (T2V model) and constructing knowledge about Video-VQVAE (VideoGPT) + DiT. Initiated by the Peking University-Tuizhan AIGC Joint Laboratory, the project currently has limited resources and seeks contributions from the open-source community. The project provides training code and welcomes Pull Requests.
AI Video Generation
437.7K

Minigpt4 Video
MiniGPT4-Video is a multimodal large model designed for video understanding. It can process temporal visual data and text data, generate captions and slogans, and is suitable for video question answering. Based on MiniGPT-v2, it incorporates the visual backbone EVA-CLIP and undergoes multi-stage training, including large-scale video-text pre-training and video question-answering fine-tuning. It achieves significant improvements on benchmarks such as MSVD, MSRVTT, TGIF, and TVQA. The pricing is currently unknown.
AI Video Generation
97.7K