%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Best 11 AI Video Generation Tools of 2025
Fresh Picks
Cogvideox
CogVideoX is an open-source video generation model that shares lineage with commercial models, enabling the generation of video content through textual descriptions. It represents the latest advancements in text-to-video generation technology, capable of producing high-quality videos applicable in various fields including entertainment, education, and commercial promotion.
AI Video Generation
75.3K
English Picks
Stable Video 4D
Stable Video 4D is the latest AI model launched by Stability AI, capable of transforming single object videos into multiple novel view videos from eight different angles. This technology represents a significant leap from image-based video generation to complete 3D dynamic video synthesis. It holds potential applications in game development, video editing, and virtual reality, and is continuously being optimized.
AI Video Generation
74.2K
Fresh Picks
Runwayml App
RunwayML is a leading next-generation creative suite that offers a rich set of tools enabling users to transform any idea into reality. With its unique text-to-video generation technology, users can create videos from text descriptions directly on their mobile devices. Key advantages include:
1. Text-to-Video Generation: Users can generate videos simply by inputting text descriptions.
2. Real-Time Updates: Regularly released new features and updates ensure users always have access to the latest AI video and image tools.
3. Seamless Asset Transfer: Users can effortlessly move assets between mobile devices and computers.
4. Multiple Subscription Options: Offering standard, professional, and plans that include 1000 video generations per month.
AI Video Generation
84.7K
Kling AI
Developed by Kuaishou Technology, Kling AI is a text-to-video generation model that can produce highly realistic videos based on text prompts. It boasts efficient video generation capabilities, generating up to 2 minutes of 30 frames-per-second video, along with advanced technologies like a 3D Spatiotemporal Joint Attention mechanism and physics-world simulation, giving it a significant competitive edge in the AI video generation field.
AI Video Generation
97.2K
Video Mamba Suite
The Video Mamba Suite is a new state-space model suite for video understanding designed to explore and assess the potential of Mamba in video modeling. It contains 14 models/modules, covering 12 video understanding tasks, demonstrating efficient performance and superiority in both video and video-language tasks.
AI Video Generation
67.3K

Minigpt4 Video
MiniGPT4-Video is a multimodal large model designed for video understanding. It can process temporal visual data and text data, generate captions and slogans, and is suitable for video question answering. Based on MiniGPT-v2, it incorporates the visual backbone EVA-CLIP and undergoes multi-stage training, including large-scale video-text pre-training and video question-answering fine-tuning. It achieves significant improvements on benchmarks such as MSVD, MSRVTT, TGIF, and TVQA. The pricing is currently unknown.
AI Video Generation
97.7K
Open Sora Plan
Open-Sora-Plan is an open-source project dedicated to replicating OpenAI's Sora (T2V model) and constructing knowledge about Video-VQVAE (VideoGPT) + DiT. Initiated by the Peking University-Tuizhan AIGC Joint Laboratory, the project currently has limited resources and seeks contributions from the open-source community. The project provides training code and welcomes Pull Requests.
AI Video Generation
437.7K

Trailblazer
TrailBlazer is a diffusion-based video generation model that enables customized video creation through trajectory control. Users can guide the subject in a video using simple bounding boxes without requiring additional model training or online optimization. TrailBlazer supports the editing of spatial and temporal attention maps, as well as controlling the trajectory and appearance of the subject through keyframe bounding boxes and prompts. This model is simple and efficient to operate, generating natural and smooth video effects. TrailBlazer is suitable for a variety of user scenarios, providing an unlimited creative experience for video generation.
AI Video Generation
83.4K

Flowvid
FlowVid is an optical flow guided video synthesis model. By utilizing the spatial and temporal information of optical flow, it achieves temporal consistency between video frames. It seamlessly integrates with existing image synthesis models to enable various modification operations, including stylization, object swapping, and local editing. FlowVid boasts fast generation speed; a 4-second, 30FPS, 512×512 resolution video can be generated in just 1.5 minutes, outperforming CoDeF (3.1x), Rerender (7.2x), and TokenFlow (10.5x) respectively. In user evaluations, FlowVid achieved a quality score of 45.7%, significantly surpassing CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
AI Video Generation
82.2K
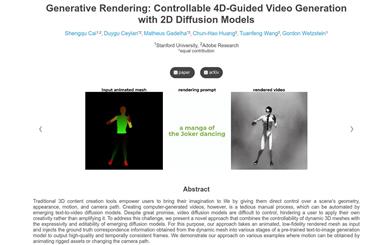
Generative Rendering: 2D Mesh
Traditional 3D content creation tools empower users with direct control over scene geometry, appearance, actions, and camera paths, transforming their imagination into reality. However, creating computer-generated videos remains a tedious manual process, which can be automated through emerging text-to-video diffusion models. Despite promising prospects, the lack of control in video diffusion models limits users' ability to apply their own creativity, rather than expanding it. To address this challenge, we propose a novel approach that combines the controllability of dynamic 3D meshes with the expressiveness and editability of emerging diffusion models. Our method takes animated low-fidelity rendering meshes as input and injectsground truth correspondences derived from the dynamic mesh into various stages of a pre-trained text-to-image generation model, resulting in high-quality, temporally consistent frames. We demonstrate our method on various examples, where actions are achieved through animating bound assets or altering camera paths.
AI Video Generation
57.1K
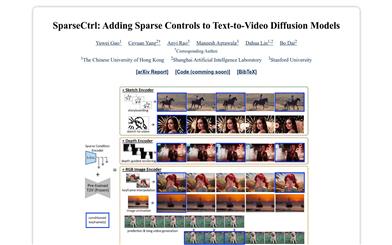
Sparsectrl
SparseCtrl is developed to enhance the controllability of text-to-video generation. It enables flexible structural control by combining sparse signals with only one or a few inputs. It includes an additional conditional encoder to process these sparse signals without affecting the pre-trained text-to-video model. This method is compatible with various formats, including sketches, depth, and RGB images, providing more practical control for video generation and pushing applications like storyboarding, depth rendering, keyframe animation, and interpolation. Extensive experiments demonstrate SparseCtrl's generalization ability on both original and personalized text-to-video generators.
AI Video Generation
81.7K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
45.5K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
49.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
45.8K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
48.9K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
48.0K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
46.4K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.8K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M