%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
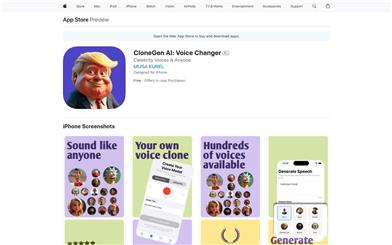
Clonegen
CloneGen是一款利用先进的人工智能技术实现声音克隆和文字转语音的应用。通过创新的声音合成技术,用户可以轻松制作个性化的声音内容,探索声音艺术的乐趣。
语音克隆
70.7K

Easevoice Trainer
EaseVoice Trainer 是一个后端项目,旨在简化和增强语音合成与转换训练过程。该项目基于 GPT-SoVITS 进行改进,注重用户体验和系统的可维护性。其设计理念不同于原始项目,旨在提供更模块化和定制化的解决方案,适用于从小规模实验到大规模生产的多种场景。该工具可以帮助开发者和研究人员更高效地进行语音合成和转换的研究与开发。
开发与工具
97.2K

Megatts 3
MegaTTS 3 是由字节跳动开发的一款基于 PyTorch 的高效语音合成模型,具有超高质量的语音克隆能力。其轻量级架构只包含 0.45B 参数,支持中英文及代码切换,能够根据输入文本生成自然流畅的语音,广泛应用于学术研究和技术开发。
语音克隆
116.7K
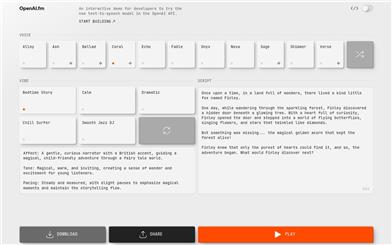
Openai.fm
OpenAI.fm 是一个互动演示平台,允许开发者体验 OpenAI API 中的最新文本转语音模型gpt-4o-transcribe, gpt-4o-mini-transcribe and gpt-4o-mini-tts。该技术能够生成自然流畅的语音,使得文本内容生动而易于理解。它适用于各种应用场景,尤其是在语音助手和内容创作方面,能够帮助开发者更好地与用户沟通,提升用户体验。该产品定位于高效的语音合成,适合希望整合语音功能的开发者。
API服务
163.4K

Orpheus TTS
Orpheus TTS 是一个基于 Llama-3b 模型的开源文本转语音系统,旨在提供更加自然的人类语音合成。它具备较强的语音克隆能力和情感表达能力,适合各种实时应用场景。该产品是免费的,旨在为开发者和研究者提供便捷的语音合成工具。
文本转声音
133.0K
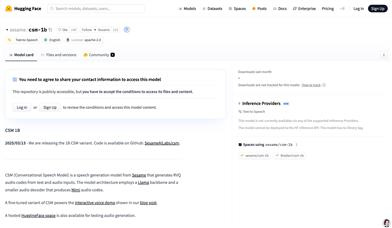
CSM 1B
CSM 1B 是一个基于 Llama 架构的语音生成模型,能够从文本和音频输入中生成 RVQ 音频代码。该模型主要应用于语音合成领域,具有高质量的语音生成能力。其优势在于能够处理多说话人的对话场景,并通过上下文信息生成自然流畅的语音。该模型开源,旨在为研究和教育目的提供支持,但明确禁止用于冒充、欺诈或非法活动。
语音生成
100.5K
优质新品
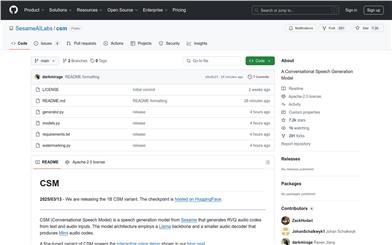
Sesame CSM
CSM 是一个由 Sesame 开发的对话式语音生成模型,它能够根据文本和音频输入生成高质量的语音。该模型基于 Llama 架构,并使用 Mimi 音频编码器。它主要用于语音合成和交互式语音应用,例如语音助手和教育工具。CSM 的主要优点是能够生成自然流畅的语音,并且可以通过上下文信息优化语音输出。该模型目前是开源的,适用于研究和教育目的。
语音合成
82.0K
Sesame AI
Sesame AI 代表了下一代语音合成技术,通过结合先进的人工智能技术和自然语言处理,能够生成极其逼真的语音,具备真实的情感表达和自然的对话流程。该平台在生成类似人类的语音模式方面表现出色,同时能够保持一致的性格特征,非常适合内容创作者、开发者和企业,用于为其应用程序增添自然语音功能。目前尚不清楚其具体价格和市场定位,但其强大的功能和广泛的应用场景使其在市场上具有较高的竞争力。
语音克隆
92.7K

Spark TTS
Spark-TTS 是一种基于大语言模型的高效文本到语音合成模型,具有单流解耦语音令牌的特性。它利用大语言模型的强大能力,直接从代码预测的音频进行重建,省略了额外的声学特征生成模型,从而提高了效率并降低了复杂性。该模型支持零样本文本到语音合成,能够跨语言和代码切换场景,非常适合需要高自然度和准确性的语音合成应用。它还支持虚拟语音创建,用户可以通过调整参数(如性别、音高和语速)来生成不同的语音。该模型的背景是为了解决传统语音合成系统中效率低下和复杂性高的问题,旨在为研究和生产提供高效、灵活且强大的解决方案。目前,该模型主要面向学术研究和合法应用,如个性化语音合成、辅助技术和语言研究等。
文本转声音
143.5K

Llasa
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音合成能力、低推理成本和灵活的框架兼容性。该模型适用于教育、娱乐和商业场景,能够为用户提供高质量的语音合成解决方案。目前该模型在Hugging Face上免费提供,旨在推动语音合成技术的发展和应用。
文本转声音
89.1K
国外精选
Octave TTS
Octave TTS 是由 Hume AI 开发的下一代语音合成模型,它不仅能够将文本转换为语音,还能理解文本的语义和情感,从而生成富有表现力的语音输出。该技术的核心优势在于其对语言的深度理解能力,使其能够根据上下文生成自然、生动的语音,适用于多种应用场景,如有声读物、虚拟助手和情感化语音交互等。Octave TTS 的出现标志着语音合成技术从简单的文本朗读向更具表现力和交互性的方向发展,为用户提供更加个性化和情感化的语音体验。目前,该产品主要面向开发者和创作者,通过 API 和平台提供服务,未来有望扩展到更多语言和应用场景。
文本转声音
82.0K

Indextts
IndexTTS 是一种基于 GPT 风格的文本到语音(TTS)模型,主要基于 XTTS 和 Tortoise 进行开发。它能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在中文场景中引入了字符-拼音混合建模方法,显著提高了训练稳定性、音色相似性和音质。此外,它还集成了 BigVGAN2 来优化音频质量。该模型在数万小时的数据上进行训练,性能超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 适用于需要高质量语音合成的场景,如语音助手、有声读物等,其开源性质也使其适合学术研究和商业应用。
文本转声音
114.3K
中文精选
星声AI
星声AI是一款专注于生成AI播客的工具。它利用先进的LLM模型(如kimi)和TTS模型(如Minimax Speech-01-Turbo),能够将文本内容快速转化为生动的播客。该技术的主要优点在于高效的内容生成能力,能够帮助创作者快速制作播客,节省时间和精力。星声AI适合内容创作者、播客爱好者以及需要快速生成音频内容的用户。其定位是为用户提供便捷的播客生成解决方案,目前暂无明确价格信息。
音频生成
109.0K
Zonos V0.1 Hybrid
Zonos-v0.1-hybrid 是由 Zyphra 开发的一款开源文本转语音模型,它能够根据文本提示生成高度自然的语音。该模型经过大量英语语音数据训练,采用 eSpeak 进行文本归一化和音素化,再通过变换器或混合骨干网络预测 DAC 令牌。它支持多种语言,包括英语、日语、中文、法语和德语,并且可以对生成语音的语速、音调、音频质量和情绪等进行精细控制。此外,它还具备零样本语音克隆功能,仅需 5 到 30 秒的语音样本即可实现高保真语音克隆。该模型在 RTX 4090 上的实时因子约为 2 倍,运行速度较快。它还配备了易于使用的 gradio 界面,并且可以通过 Docker 文件简单安装和部署。目前,该模型在 Hugging Face 上提供,用户可以免费使用,但需要自行部署。
文本转声音
73.4K
Llasa Training
LLaSA_training 是一个基于 LLaMA 的语音合成训练项目,旨在通过优化训练时间和推理时间的计算资源,提升语音合成模型的效率和性能。该项目利用开源数据集和内部数据集进行训练,支持多种配置和训练方式,具有较高的灵活性和可扩展性。其主要优点包括高效的数据处理能力、强大的语音合成效果以及对多种语言的支持。该项目适用于需要高性能语音合成解决方案的研究人员和开发者,可用于开发智能语音助手、语音播报系统等应用场景。
模型训练与部署
58.0K
Llasa 1B
Llasa-1B 是一个由香港科技大学音频实验室开发的文本转语音模型。它基于 LLaMA 架构,通过结合 XCodec2 代码本中的语音标记,能够将文本转换为自然流畅的语音。该模型在 25 万小时的中英文语音数据上进行了训练,支持从纯文本生成语音,也可以利用给定的语音提示进行合成。其主要优点是能够生成高质量的多语言语音,适用于多种语音合成场景,如有声读物、语音助手等。该模型采用 CC BY-NC-ND 4.0 许可证,禁止商业用途。
文本转声音
76.7K
Llasa 3B
Llasa-3B 是一个强大的文本到语音(TTS)模型,基于 LLaMA 架构开发,专注于中英文语音合成。该模型通过结合 XCodec2 的语音编码技术,能够将文本高效地转换为自然流畅的语音。其主要优点包括高质量的语音输出、支持多语言合成以及灵活的语音提示功能。该模型适用于需要语音合成的多种场景,如有声读物制作、语音助手开发等。其开源性质也使得开发者可以自由探索和扩展其功能。
文本转声音
112.9K
AI ContentCraft
AI ContentCraft 是一个强大的内容创作平台,旨在帮助创作者快速生成故事、播客脚本和多媒体内容。它通过集成文本生成、语音合成和图像生成技术,为创作者提供一站式的解决方案。该工具支持中英文内容转换,适合需要高效创作的用户。其技术栈包括 DeepSeek AI、Kokoro TTS 和 Replicate API,确保高质量的内容生成。产品目前开源免费,适合个人和团队使用。
写作助手
90.5K
Hailuo AI Audio
Hailuo AI Audio利用先进的语音合成技术,将文本转换为自然流畅的语音。其主要优点是能够生成高质量、富有表现力的语音,适用于多种场景,如有声读物制作、语音播报等。该产品定位为专业级音频合成工具,目前提供限时免费体验,旨在为用户提供高效、便捷的语音生成解决方案。
文本转声音
77.8K
Kokoro Onnx
kokoro-onnx是一个基于Kokoro模型和ONNX运行时的文本到语音(TTS)项目。它支持英语,并计划支持法语、日语、韩语和中文。该模型在macOS M1上具有接近实时的快速性能,并提供多种声音选择,包括耳语。模型轻量级,约为300MB(量化后约为80MB)。该项目在GitHub上开源,采用MIT许可证,方便开发者集成和使用。
文本转声音
77.6K
Audiblez
Audiblez是一个利用Kokoro高质量语音合成技术,将普通电子书(.epub格式)转换为.m4b格式有声书的工具。它支持多种语言和声音,用户可以通过简单的命令行操作完成转换,极大地丰富了电子书的阅读体验,尤其适合在开车、运动等不方便阅读的场景下使用。该工具由Claudio Santini在2025年开发,遵循MIT许可证免费开源。
文本转声音
88.6K
Kokoro 82M
Kokoro-82M是一个由hexgrad创建并托管在Hugging Face上的文本到语音(TTS)模型。它具有8200万参数,使用Apache 2.0许可证开源。该模型在2024年12月25日发布了v0.19版本,并提供了10种独特的语音包。Kokoro-82M在TTS Spaces Arena中排名第一,显示出其在参数规模和数据使用上的高效性。它支持美国英语和英国英语,可用于生成高质量的语音输出。
文本转声音
120.9K
Synthesys
Synthesys是一个AI内容生成平台,提供AI视频、AI语音和AI图像生成服务。它通过使用先进的人工智能技术,帮助用户以更低的成本和更简单的操作生成专业级别的内容。Synthesys的产品背景基于当前市场对于高质量、低成本内容生成的需求,其主要优点包括支持多种语言的超真实语音合成、无需专业设备即可生成高清视频、以及用户友好的界面设计。平台的定价策略包括免费试用和不同级别的付费服务,定位于满足不同规模企业的内容生成需求。
视频生成
75.1K
Voxdazz
Voxdazz是一个利用人工智能技术模仿名人声音的在线平台。用户可以选择名人的声音模板,输入想要说的话,Voxdazz将生成相应的视频。这项技术基于复杂的算法,能够模拟自然的语调、节奏和强调,非常接近人类的语音。它不仅适用于娱乐和幽默视频的制作,还可以用于分享模仿名人的搞笑内容。Voxdazz以其高质量的语音生成和用户友好的操作界面,为用户提供了一个全新的娱乐和创意表达方式。
语音克隆
80.9K
国外精选
Elevenlabs Flash
Flash是ElevenLabs最新推出的文本转语音(Text-to-Speech, TTS)模型,它以75毫秒加上应用和网络延迟的速度生成语音,是低延迟、会话型语音代理的首选模型。Flash v2仅支持英语,而Flash v2.5支持32种语言,每两个字符消耗1个信用点。Flash在盲测中持续超越了同类超低延迟模型,是速度最快且具有质量保证的模型。
文本转声音
66.8K
国外精选
Gemini 2.0 Flash Experimental
Gemini 2.0 Flash Experimental是Google DeepMind开发的最新AI模型,旨在提供低延迟和增强性能的智能代理体验。该模型支持原生工具使用,并首次能够原生创建图像和生成语音,代表了AI技术在理解和生成多媒体内容方面的重要进步。Gemini Flash模型家族以其高效的处理能力和广泛的应用场景,成为推动AI领域发展的关键技术之一。
AI模型
78.4K

Cosyvoice 2
CosyVoice 2是由阿里巴巴集团的SpeechLab@Tongyi团队开发的语音合成模型,它基于监督离散语音标记,并结合了两种流行的生成模型:语言模型(LMs)和流匹配,实现了高自然度、内容一致性和说话人相似性的语音合成。该模型在多模态大型语言模型(LLMs)中具有重要的应用,特别是在交互体验中,响应延迟和实时因素对语音合成至关重要。CosyVoice 2通过有限标量量化提高语音标记的码本利用率,简化了文本到语音的语言模型架构,并设计了块感知的因果流匹配模型以适应不同的合成场景。它在大规模多语言数据集上训练,实现了与人类相当的合成质量,并具有极低的响应延迟和实时性。
语音克隆
89.4K
Cosyvoice语音生成大模型2.0 0.5B
CosyVoice语音生成大模型2.0-0.5B是一个高性能的语音合成模型,支持零样本、跨语言的语音合成,能够根据文本内容直接生成相应的语音输出。该模型由通义实验室提供,具有强大的语音合成能力和广泛的应用场景,包括但不限于智能助手、有声读物、虚拟主播等。模型的重要性在于其能够提供自然、流畅的语音输出,极大地丰富了人机交互的体验。
文本转声音
110.7K
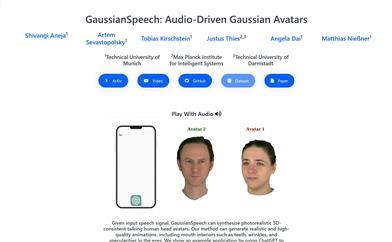
Gaussianspeech
GaussianSpeech是一种新颖的方法,它能够从语音信号中合成高保真度的动画序列,创建逼真、个性化的3D人头化身。该技术通过结合语音信号与3D高斯绘制技术,捕捉人类头部表情和细节动作,包括皮肤皱褶和更细微的面部运动。GaussianSpeech的主要优点包括实时渲染速度、自然的视觉动态效果,以及能够呈现多样化的面部表情和风格。该技术背后是大规模多视角音频-视觉序列数据集的创建,以及音频条件变换模型的开发,这些模型能够直接从音频输入中提取唇部和表情特征。
视频生成
50.0K
Outetts 0.2 500M
OuteTTS-0.2-500M是基于Qwen-2.5-0.5B构建的文本到语音合成模型,它在更大的数据集上进行了训练,实现了在准确性、自然度、词汇量、声音克隆能力以及多语言支持方面的显著提升。该模型特别感谢Hugging Face提供的GPU资助,支持了模型的训练。
语音合成
114.5K
- 1
- 2
- 3
- 4
- 5
- 6
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.1K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M