%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Phantom
Phantom 是一种先进的视频生成技术,通过跨模态对齐实现主体一致性视频生成。它能够根据单张或多张参考图像生成生动的视频内容,同时严格保留主体的身份特征。该技术在内容创作、虚拟现实和广告等领域具有重要应用价值,能够为创作者提供高效且富有创意的视频生成解决方案。Phantom 的主要优点包括高度的主体一致性、丰富的视频细节以及强大的多模态交互能力。
视频生成
73.1K
Pippo
Pippo 是由 Meta Reality Labs 和多所高校合作开发的生成模型,能够从单张普通照片生成高分辨率的多人视角视频。该技术的核心优势在于无需额外输入(如参数化模型或相机参数),即可生成高质量的 1K 分辨率视频。它基于多视角扩散变换器架构,具有广泛的应用前景,如虚拟现实、影视制作等。Pippo 的代码已开源,但不包含预训练权重,用户需要自行训练模型。
视频生成
91.4K

Gamefactory
GameFactory 是一个创新的通用世界模型,专注于从少量的《我的世界》游戏视频数据中学习,并利用预训练视频扩散模型的先验知识来生成新的游戏内容。该技术的核心优势在于其开放领域的生成能力,能够根据用户输入的文本提示和操作指令生成多样化的游戏场景和互动体验。它不仅展示了强大的场景生成能力,还通过多阶段训练策略和可插拔的动作控制模块,实现了高质量的交互式视频生成。该技术在游戏开发、虚拟现实和创意内容生成等领域具有广阔的应用前景,目前尚未明确其价格和商业化定位。
游戏生成
54.6K

SCENIC Model
SCENIC是一个文本条件的场景交互模型,能够适应具有不同地形的复杂场景,并支持使用自然语言进行用户指定的语义控制。该模型通过用户指定的轨迹作为子目标和文本提示,来导航3D场景。SCENIC利用层次化推理场景的方法,结合运动与文本之间的帧对齐,实现不同运动风格之间的无缝过渡。该技术的重要性在于其能够生成符合真实物理规则和用户指令的角色导航动作,对于虚拟现实、增强现实以及游戏开发等领域具有重要意义。
游戏生成
48.9K
Genex
GenEx是一个AI模型,它能够从单张图片创建一个完全可探索的360°3D世界。用户可以互动地探索这个生成的世界。GenEx在想象空间中推进具身AI,并有潜力将这些能力扩展到现实世界的探索。
3D建模
72.6K
SOLAMI
SOLAMI是一个端到端的社交视觉-语言-动作(VLA)建模框架,用于与3D自主角色进行沉浸式交互。该框架通过综合三个主要方面构建3D自主角色:社交VLA架构、交互式多模态数据和沉浸式VR界面。SOLAMI的主要优点包括更精确和自然的字符响应(包括语音和动作),与用户期望一致,并且延迟更低。该技术的重要性在于它为3D自主角色提供了类似人类的社交智能,使其能够感知、理解和与人类进行交互,这是人工智能领域中的一个开放且基础的问题。
AI角色生成
49.7K
CAT4D
CAT4D是一个利用多视图视频扩散模型从单目视频中生成4D场景的技术。它能够将输入的单目视频转换成多视角视频,并重建动态的3D场景。这项技术的重要性在于它能够从单一视角的视频资料中提取并重建出三维空间和时间的完整信息,为虚拟现实、增强现实以及三维建模等领域提供了强大的技术支持。产品背景信息显示,CAT4D由Google DeepMind、Columbia University和UC San Diego的研究人员共同开发,是一个前沿的科研成果转化为实际应用的案例。
3D建模
58.5K
The Matrix
The Matrix是一个先锋项目,旨在通过AI技术打造一个全沉浸式、交互式的数字宇宙,模糊现实与幻觉之间的界限。该项目通过提供帧级精度的用户交互、AAA级视觉效果以及无限的生成能力,突破了现有视频模型的局限,为用户带来无尽的探索体验。The Matrix由阿里巴巴集团、香港大学、滑铁卢大学和Vector Institute共同研发,代表了世界模拟技术的新高度。
虚拟现实
55.2K

TANGO Model
TANGO是一个基于层次化音频-运动嵌入和扩散插值的共语手势视频重现技术。它利用先进的人工智能算法,将语音信号转换成相应的手势动作,实现视频中人物手势的自然重现。这项技术在视频制作、虚拟现实、增强现实等领域具有广泛的应用前景,能够提升视频内容的互动性和真实感。TANGO由东京大学和CyberAgent AI Lab联合开发,代表了当前人工智能在手势识别和动作生成领域的前沿水平。
AI视频生成
78.1K
Meta Quest 3S
Meta Quest 3S是一款混合现实头戴设备,提供沉浸式游戏体验、健身和娱乐功能,支持Facebook、Instagram和WhatsApp等应用且支持“Hey Meta”唤醒词来调用 Meta AI。它具有高分辨率显示、轻巧设计、创新的控制器设计和增强的触觉反馈。Meta Quest 3S旨在为用户带来前所未有的虚拟体验,同时保持舒适的佩戴体验和高性能的图形处理能力。
AI虚拟现实
49.7K
GVHMR
GVHMR是一种创新的人体运动恢复技术,它通过重力视角坐标系统来解决从单目视频中恢复世界定位的人体运动的问题。该技术能够减少学习图像-姿态映射的歧义,并且避免了自回归方法中连续图像的累积误差。GVHMR在野外基准测试中表现出色,不仅在准确性和速度上超越了现有的最先进技术,而且其训练过程和模型权重对公众开放,具有很高的科研和实用价值。
AI模型
71.2K
国外精选
World Labs
World Labs 是一家专注于空间智能的公司,致力于构建大型世界模型(Large World Models),以感知、生成和与3D世界进行互动。公司由AI领域的知名科学家、教授、学者和行业领导者共同创立,包括斯坦福大学的Fei-Fei Li教授、密歇根大学的Justin Johnson教授等。他们通过创新的技术和方法,如神经辐射场(NeRF)技术,推动了3D场景重建和新视角合成的发展。World Labs 得到了包括Marc Benioff、Jim Breyer等知名投资者的支持,其技术在AI领域具有重要的应用价值和商业潜力。
3D建模
83.1K

Omnire
OmniRe 是一种用于高效重建高保真动态城市场景的全面方法,它通过设备日志来实现。该技术通过构建基于高斯表示的动态神经场景图,以及构建多个局部规范空间来模拟包括车辆、行人和骑行者在内的各种动态行为者,从而实现了对场景中不同对象的全面重建。OmniRe 允许我们全面重建场景中存在的不同对象,并随后实现所有参与者实时参与的重建场景的模拟。在 Waymo 数据集上的广泛评估表明,OmniRe 在定量和定性方面都大幅超越了先前的最先进方法。
AI图像生成
56.3K
Avp Teleoperate
这是一个开源项目,用于实现人形机器人Unitree H1_2的遥控操作。它利用了Apple Vision Pro技术,允许用户通过虚拟现实环境来控制机器人。该项目在Ubuntu 20.04和Ubuntu 22.04上进行了测试,并且提供了详细的安装和配置指南。该技术的主要优点包括能够提供沉浸式的遥控体验,并且支持在模拟环境中进行测试,为机器人遥控领域提供了新的解决方案。
AI Agents
56.9K

Controlmm
ControlMM是一个全身运动生成框架,具有即插即用的多模态控制功能,能够在文本到运动(Text-to-Motion)、语音到手势(Speech-to-Gesture)和音乐到舞蹈(Music-to-Dance)等多个领域中生成稳健的运动。该模型在可控性、序列性和运动合理性方面具有明显优势,为人工智能领域提供了一种新的运动生成解决方案。
AI模型
78.7K

Holodreamer
HoloDreamer是一个文本驱动的3D场景生成框架,能够生成沉浸式且视角一致的全封闭3D场景。它由两个基本模块组成:风格化等矩形全景生成和增强两阶段全景重建。该框架首先生成高清晰度的全景图作为完整3D场景的整体初始化,然后利用3D高斯散射(3D-GS)技术快速重建3D场景,从而实现视角一致和完全封闭的3D场景生成。HoloDreamer的主要优点包括高视觉一致性、和谐性以及重建质量和渲染的鲁棒性。
AI图像生成
86.1K
国外精选
Aiuni
Aiuni是一个提供3D虚拟世界体验的平台,用户可以在这里创建和探索个性化的3D模型,享受沉浸式的宇宙探索之旅。Aiuni以其创新的3D技术、丰富的互动性和高度的个性化定制,为用户提供了一个全新的虚拟体验空间。
3D建模
496.0K
优质新品
Egogaussian
EgoGaussian是一项先进的3D场景重建与动态物体追踪技术,它能够仅通过RGB第一人称视角输入,同时重建3D场景并动态追踪物体的运动。这项技术利用高斯散射的独特离散特性,从背景中分割出动态交互,并通过片段级别的在线学习流程,利用人类活动的动态特性,以时间顺序重建场景的演变并追踪刚体物体的运动。EgoGaussian在野外视频的挑战中超越了先前的NeRF和动态高斯方法,并且在重建模型的质量上也表现出色。
AI 3D工具
51.3K
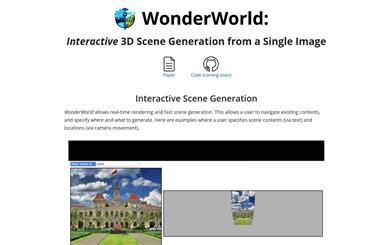
Wonderworld
WonderWorld是一个创新的3D场景扩展框架,允许用户基于单张输入图片和用户指定的文本探索和塑造虚拟环境。它通过快速高斯体素和引导扩散的深度估计方法,显著减少了计算时间,生成几何一致的扩展,使3D场景的生成时间少于10秒,支持实时用户交互和探索。这为虚拟现实、游戏和创意设计等领域提供了快速生成和导航沉浸式虚拟世界的可能性。
AI图像生成
64.3K

Unique3d
Unique3D是由清华大学团队开发的一项技术,能够从单张图片中生成高保真度的纹理3D网格模型。这项技术在图像处理和3D建模领域具有重要意义,它使得用户能够快速将2D图像转化为3D模型,为游戏开发、动画制作、虚拟现实等领域提供了强大的技术支持。
AI 3D工具
132.8K
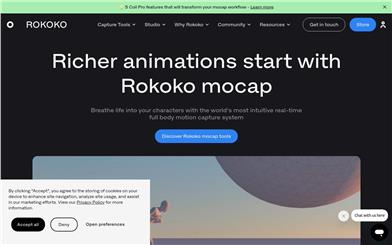
Rokoko
Rokoko是一款基于传感器的动作捕捉系统,为3D数字创作者提供高质量的身体、手指和面部动画解决方案。它具有直观易用的界面和负担得起的价格,可帮助用户轻松实现逼真的角色动画。
AI设计工具
78.9K
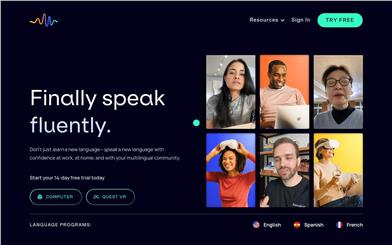
Immerse
Immerse是一款由专家设计的虚拟现实语言沉浸式学习平台,通过提供语言课程和AI辅助练习,帮助成年人流利地学习新语言。它的主要优点包括:通过虚拟现实技术提供身临其境的语言学习体验;结合AI技术提供个性化的语言练习;专业教师指导和实时反馈等。Immerse的定位是帮助成年人实现流利地说新语言的目标。
学习教育
63.2K
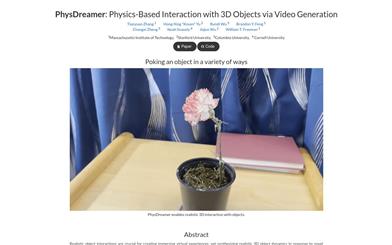
Physdreamer
PhysDreamer是一个基于物理的方法,它通过利用视频生成模型学习到的对象动力学先验,为静态3D对象赋予交互式动力学。这种方法允许在缺乏真实物体物理属性数据的情况下,模拟出对新颖交互(如外力或代理操作)的真实反应。PhysDreamer通过用户研究评估合成交互的真实性,推动了更吸引人和真实的虚拟体验的发展。
AI 3D工具
101.6K
Lixel CyberColor
Lixel CyberColor(LCC),由XGRIDS公司研发的先进技术产品,为3D场景的创建带来革命性变化。LCC能自动生成电影级效果的无限大3D场景,使用Multi-SLAM和高斯溅射技术。其核心优势在于精确捕捉并复现真实细节,为虚拟现实、游戏开发、电影制作等领域带来真实性体验。
XGRIDS作为一套集成软硬件解决方案,展现出在微米到千米级别的高精度3D重建和智能空间计算方面的强大能力。采用Multi-SLAM算法和优化的3DGS技术,自动创建超逼真大型3D模型,沉浸式体验。优化算法实现逼真渲染效果,通过数据压缩技术将模型大小减小90%,LiDAR集成技术实现厘米级模型精度,提供AI驱动的动态物体去除算法。推出LCC插件和SDK,在Unity、UE、Web、移动平台使用,为3D内容提供强大支持。
AI设计工具
79.8K
Champ
Champ 是一种用于生成 3D 物体形状的生成模型,它结合了隐函数和卷积神经网络,以生成高质量、多样化和逼真的 3D 形状。它可以生成各种类别的形状,包括动物、车辆和家具。
AI图像生成
83.9K
VIGGLE
VIGGLE是一款基于JST-1视频-3D基础模型的可控视频生成工具。它可以让任何角色按照您的要求移动。JST-1是第一个具有实际物理理解能力的视频-3D基础模型。VIGGLE的优势在于其强大的视频生成和控制能力,可以根据用户需求生成各种动作和情节的视频。它定位于视频创作者、动画师和内容创作者等专业人群,帮助他们更高效地制作视频内容。目前VIGGLE处于测试阶段,未来可能会推出付费订阅版本。
视频生成
2.4M
Captury
Captury提供先进的无标记运动捕捉解决方案,可精准可靠地跟踪多个演员同时进行的全身动作、手指移动和面部表情。我们的解决方案旨在提高运动捕捉的效率,同时降低所涉及的时间和成本。Captury可应用于3D游戏开发、虚拟效果/电影/广告领域、虚拟现实、实时虚拟/基于位置的娱乐、游戏内玩家跟踪以及生命科学等领域。主要产品包括实时处理CapturyLive、CapturyInGame、CapturyFace,以及后期处理CapturyStudio和CapturyDome等。
AI设计工具
53.3K
Depthify.ai
Depthify.ai是一个工具,可以将RGB图像转换为与Apple Vision Pro和Meta Quest兼容的各种空间格式。通过转换RGB图像为空间照片,可以为各种计算机视觉和3D建模应用提供支持。它可以生成深度图、立体图像和HEIC文件,可在Apple Vision Pro上使用。
图片编辑
113.4K
Wooorld
Wooorld是一个虚拟现实探索和社交平台。用户可以在虚拟世界中与朋友们一起游览地球上的数百个城市、地标和自然景观。Wooorld提供了极其真实和细致的3D地图,用户只需要用双手抓取地图就可以平移和缩放。用户还可以进行语音交流、使用面部和身体动态捕捉的3D头像,玩游戏和使用创意工具进行协作。这是一个独特的社交体验。
游戏生成
58.5K

Ultravatar
UltrAvatar是一款逼真可动的3D头像生成模型,旨在缩小虚拟与现实世界体验之间的差距。它采用Score Distillation Sampling (SDS) loss和可微分渲染器以及文本条件来引导扩散模型生成3D头像。与现有作品相比,UltrAvatar通过增强几何保真度和优越的物理渲染纹理质量,提出了一种新颖的3D头像生成方法。它通过扩散色彩提取模型和真实性引导纹理扩散模型,去除不需要的光照效果,呈现真实的扩散颜色,使生成的头像能够在各种光照条件下呈现。我们在实验证明了该方法的有效性和鲁棒性,在实验中大幅优于现有最先进的方法。
AI头像生成
83.1K
- 1
- 2
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.7K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.3K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M