首頁
AI產品庫
模型廣場
MCP服務庫
AI資訊
TW
首頁
全部分類
圖片編輯
Picture To Text
Picture To Text
圖片編輯
文本轉聲音
#圖片轉文字
#文字識別
#OCR
#免費
#在線工具
普通產品
商用
簡介 :
Picture to Text是一款在線圖片文字識別工具,能夠批量提取和複製圖片中的文字內容。它免費轉換照片為可編輯的文字。
需求人群 :
1. 將辦公文檔數字化 2. 圖片中的文字轉為可編輯文本 3. 提高法律工作效率 4. 節省時間和精力
總訪問量:
201.2K
佔比最多地區:
CN(22.76%)
本站瀏覽量 : 99.6K
打開站點
產品介紹
網站流量
同類開源產品
替代品
產品特色
將圖片轉換為可編輯的文字
支持多種圖片格式
支持多種語言識別
支持批量處理
流量來源
直接訪問
25.29%
外鏈引薦
65.12%
郵件
0.10%
自然搜索
6.48%
社交媒體
2.42%
展示廣告
0.54%
最新流量情況
月訪問量
198.09k
平均訪問時長
23.12
每次訪問頁數
2.13
跳出率
48.20%
總流量趨勢圖
地理流量分佈情況
月訪問量
198.09k
China
22.76%
United States
4.64%
Philippines
4.29%
United Kingdom
3.98%
India
3.22%
地理流量分佈全球圖
同類開源產品
國外精選
Step1x Edit
Step1X-Edit 是一種實用的通用圖像編輯框架,利用 MLLMs 的圖像理解能力解析編輯指令,生成編輯令牌,並通過 DiT 網絡解碼為圖像。其重要性在於能夠有效滿足真實用戶的編輯需求,提升了圖像編輯的便捷性和靈活性。
圖片編輯
國外精選
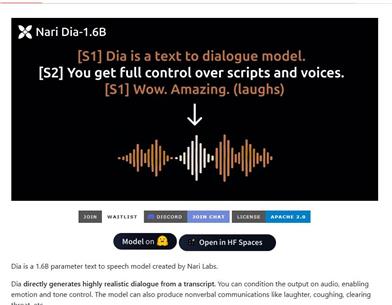
Dia AI
Dia 是一個由 Nari Labs 開發的文本到語音(TTS)模型,具有 1.6 億參數,能夠直接從文本生成高度逼真的對話。該模型支持情感和語調控制,並能夠生成非言語交流,如笑聲和咳嗽。它的預訓練模型權重託管在 Hugging Face 上,適用於英語生成。此產品對於研究和教育用途至關重要,能夠推動對話生成技術的發展。
文本轉聲音
Orpheus TTS
Orpheus TTS 是一個基於 Llama-3b 模型的開源文本轉語音系統,旨在提供更加自然的人類語音合成。它具備較強的語音克隆能力和情感表達能力,適合各種即時應用場景。該產品是免費的,旨在為開發者和研究者提供便捷的語音合成工具。
文本轉聲音
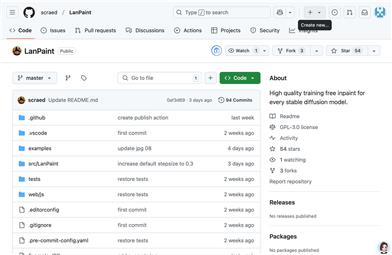
Lanpaint
LanPaint 是一款針對穩定擴散模型的圖像修復插件,通過多輪迭代推理,無需額外訓練即可實現高質量的圖像修復。該技術的重要性在於它為用戶提供了一種無需複雜訓練即可獲得精準修復結果的解決方案,大大降低了使用門檻。LanPaint 適用於任何穩定擴散模型,包括用戶自定義的模型,具有廣泛的適用性和靈活性。它主要面向需要高質量圖像修復的創作者和開發者,尤其是那些希望在不進行額外訓練的情況下快速獲得修復結果的用戶。
圖片編輯
Spark TTS
Spark-TTS 是一種基於大語言模型的高效文本到語音合成模型,具有單流解耦語音令牌的特性。它利用大語言模型的強大能力,直接從代碼預測的音頻進行重建,省略了額外的聲學特徵生成模型,從而提高了效率並降低了複雜性。該模型支持零樣本文本到語音合成,能夠跨語言和代碼切換場景,非常適合需要高自然度和準確性的語音合成應用。它還支持虛擬語音創建,用戶可以通過調整參數(如性別、音高和語速)來生成不同的語音。該模型的背景是為了解決傳統語音合成系統中效率低下和複雜性高的問題,旨在為研究和生產提供高效、靈活且強大的解決方案。目前,該模型主要面向學術研究和合法應用,如個性化語音合成、輔助技術和語言研究等。
文本轉聲音
Llasa
Llasa是一個基於Llama框架的文本到語音(TTS)基礎模型,專為大規模語音合成任務設計。該模型利用16萬小時的標記化語音數據進行訓練,具備高效的語言生成能力和多語言支持。其主要優點包括強大的語音合成能力、低推理成本和靈活的框架兼容性。該模型適用於教育、娛樂和商業場景,能夠為用戶提供高質量的語音合成解決方案。目前該模型在Hugging Face上免費提供,旨在推動語音合成技術的發展和應用。
文本轉聲音
Indextts
IndexTTS 是一種基於 GPT 風格的文本到語音(TTS)模型,主要基於 XTTS 和 Tortoise 進行開發。它能夠通過拼音糾正漢字發音,並通過標點符號控制停頓。該系統在中文場景中引入了字符-拼音混合建模方法,顯著提高了訓練穩定性、音色相似性和音質。此外,它還集成了 BigVGAN2 來優化音頻質量。該模型在數萬小時的數據上進行訓練,性能超越了當前流行的 TTS 系統,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 適用於需要高質量語音合成的場景,如語音助手、有聲讀物等,其開源性質也使其適合學術研究和商業應用。
文本轉聲音
Zonos
Zonos 是一個先進的文本到語音模型,支持多種語言,能夠根據文本提示和說話者嵌入或音頻前綴生成自然語音。它還支持語音克隆,只需幾秒鐘的參考音頻即可準確複製說話者的聲音。該模型具有高質量的語音輸出(44kHz),並允許對語速、音調變化、音頻質量和情緒(如快樂、恐懼、悲傷和憤怒)進行精細控制。Zonos 提供了 Python 和 Gradio 接口,方便用戶快速上手,並支持通過 Docker 部署。該模型在 RTX 4090 上的即時因子約為 2 倍,適合需要高質量語音合成的應用場景。
文本轉聲音
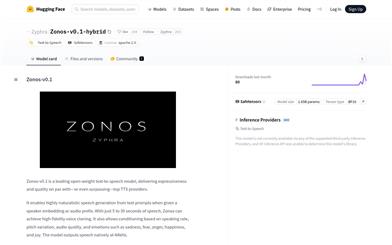
Zonos V0.1 Hybrid
Zonos-v0.1-hybrid 是由 Zyphra 開發的一款開源文本轉語音模型,它能夠根據文本提示生成高度自然的語音。該模型經過大量英語語音數據訓練,採用 eSpeak 進行文本歸一化和音素化,再通過變換器或混合骨幹網絡預測 DAC 令牌。它支持多種語言,包括英語、日語、中文、法語和德語,並且可以對生成語音的語速、音調、音頻質量和情緒等進行精細控制。此外,它還具備零樣本語音克隆功能,僅需 5 到 30 秒的語音樣本即可實現高保真語音克隆。該模型在 RTX 4090 上的即時因子約為 2 倍,運行速度較快。它還配備了易於使用的 gradio 界面,並且可以通過 Docker 文件簡單安裝和部署。目前,該模型在 Hugging Face 上提供,用戶可以免費使用,但需要自行部署。
文本轉聲音
替代品
Pixfy AI
Pixfy AI 是一款革命性的 AI 圖像編輯器,採用對話式編輯方式,讓照片編輯變得簡單易用。其主要優點在於高質量、專業結果,適用於電子商務、社交媒體和個人使用。Pixfy AI 定位於提供簡單而強大的照片編輯工具。
圖片編輯
Voispark
VoiSpark是一個AI語音生成平臺,能生成逼真的文本轉語音,克隆聲音,併為視頻、播客等定製獨特AI聲音。該平臺具有100%免費試用。
文本轉聲音
AI Face Swap
AI人臉交換利用先進的人工智能技術進行人臉交換,快速、準確、安全。突破數字創意的邊界,提升圖片的質量。
圖片編輯
Picit AI
Picit AI 是一款強大的在線 AI 圖片編輯器,提供多種功能,包括圖像生成、背景移除和圖像增強。該產品致力於幫助用戶輕鬆創建和編輯高質量圖像,適合各類創作者和設計師使用。Picit AI 提供免費服務,使每個人都能享受先進的圖像處理技術。
圖片編輯
Imggood
ImgGood 是一款免費的在線照片編輯工具,利用先進的 AI 技術幫助用戶快速、高效地編輯照片。它提供背景移除、圖像增強、對象移除等多種功能,旨在使照片編輯變得簡單而高效。此產品無需下載,適合任何希望提升照片質量的用戶,使用過程簡便,且完全免費。
圖片編輯
Unwatermark AI
Unwatermark AI是一款先進的基於AI技術的去水印工具,可快速去除圖像和視頻中的水印。其主要優點包括自動檢測和定位水印、高質量保證、快速速度、支持多終端使用等。產品定位於提供免費的去水印服務。
圖片編輯
P20V
P20V是一個免費的AI平臺,可以在幾秒鐘內轉換圖像和視頻,無需登錄。適用於營銷、設計、建築、時尚、遊戲、電子商務等多個行業。用戶可以創建專業級視覺內容並與創意社區分享。
圖片編輯
Faceage AI
FaceAge AI是一款基於人工智能的面部年齡檢測工具,通過上傳照片,快速準確地分析面部各個部位的年齡信息。其主要優點在於提供私密、快速、準確的年齡分析結果,可幫助用戶更好地瞭解自己的面部特徵。
圖片編輯
Portal By 20Vision
Portal by 20Vision是一個免費AI平臺,可在幾秒鐘內轉換圖像和視頻,無需註冊。適用於營銷、設計、建築、時尚、遊戲、電子商務等領域。主要優點包括快速轉換、社區分享和適用於多個行業。
圖片編輯
精選AI產品推薦
優質新品
Fish Audio文本轉語音
文本轉語音技術是一種將文本信息轉換為語音的技術,廣泛應用於輔助閱讀、語音助手、有聲讀物製作等領域。它通過模擬人類語音,提高了信息獲取的便捷性,尤其對視力障礙者或在無法使用眼睛閱讀的情況下非常有幫助。
文本轉聲音
10.1M
國外精選
Pic Copilot
Pic Copilot是一個利用圖像生成模型為電商提供的AI驅動圖片優化工具。它能夠通過對大量圖片點擊量數據的訓練,有效提高圖片的點擊轉化率,從而優化電商的營銷效果。其關鍵優勢是提高圖片的點擊轉化率,從而提升電商營銷效果。它是阿里巴巴團隊訓練的數據結果,能夠顯著優化圖片的點擊轉化表現。
圖片編輯
5.4M
智啟未來,您的人工智能解決方案智庫
English
简体中文
繁體中文
にほんご
© 2025
AIbase
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)