%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
中国語精選

Chatimg
ChatIMGは、ChatGPT 4oテクノロジーを利用したAI画像生成プラットフォームで、写真やアイデアを宮崎駿風の芸術作品に変換することに特化しています。高度な拡散モデルを採用し、超高解像度画像生成に対応しており、プロの芸術創作に最適です。個人およびビジネスニーズを満たす高品質なビジュアルコンテンツを誰もが作成できるようにすることを目指しており、柔軟な価格設定戦略により、様々なユーザーに対応しています。
チャットボット
40.0K
高品質新製品
Cogview4
CogView4は、清華大学が開発した高度なテキストツーイメージ生成モデルであり、拡散モデル技術に基づいて、テキストの説明から高品質な画像を生成できます。中国語と英語の入力をサポートし、高解像度の画像を生成できます。CogView4の主な利点は、強力な多言語サポートと高品質な画像生成能力であり、高効率な画像生成を必要とするユーザーに適しています。このモデルはECCV 2024で発表され、重要な研究および応用価値を有しています。
画像生成
44.4K
Flashvideo
FlashVideoは、効率的で高解像度の動画生成に特化した深層学習モデルです。段階的な生成戦略により、まず低解像度の動画を生成し、その後、エンハンスメントモデルで高解像度へとアップスケールすることで、ディテールを維持しつつ計算コストを大幅に削減します。この技術は、特に高品質なビジュアルコンテンツが必要な場面において、動画生成分野で重要な意味を持ちます。FlashVideoは、コンテンツ制作、広告制作、動画編集など、様々な場面で使用できます。オープンソースであるため、研究者や開発者は柔軟にカスタマイズと拡張を行うことができます。
映像制作
51.6K
Prompt Depth Anything
Prompt Depth Anythingは、高解像度かつ高精度な距離測定深度推定を行う手法です。この手法は、プロンプト(指示)技術を用いて深度基礎モデルの潜在能力を引き出し、iPhone LiDARをプロンプトとして利用することで、最大4K解像度の高精度距離測定深度を生成します。さらに、拡張可能なデータパイプラインを導入してトレーニングを行い、より詳細なScanNet++データセットの深度アノテーションを公開しました。この技術の主な利点には、高解像度、高精度の深度推定、そして3D再構成や汎用ロボット把持などの下流アプリケーションへの利点があります。
3Dモデリング
47.2K
Sana 600M 512px
SanaはNVIDIAが開発したテキストツーイメージ生成フレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性と強力なテキストと画像の整合性により、ノートパソコンのGPUでも動作し、画像生成技術の大きな進歩を示しています。このモデルは線形拡散変換器をベースとし、事前学習済みのテキストエンコーダと空間圧縮潜在特徴エンコーダを使用して、テキストプロンプトに基づいて画像の生成と変更を行います。SanaのオープンソースコードはGitHubで公開されており、芸術創作、教育ツール、モデル研究など、幅広い研究と応用が期待されます。
画像生成
61.0K
Sana 600M 1024px
SanaはNVIDIAが開発したテキスト画像生成フレームワークであり、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性と強力なテキスト画像アライメント機能を備えており、ノートパソコンのGPUでも展開可能です。線形拡散変換器(text-to-image generative model)に基づくモデルで、1648Mパラメータを持ち、1024pxをベースとしたマルチスケールな高解像度画像生成に特化しています。主な利点としては、高解像度画像生成、高速な合成速度、そして強力なテキスト画像アライメント機能が挙げられます。Sanaモデルはオープンソースコードに基づいて開発されており、GitHubでソースコードを入手でき、CC BY-NC-SA 4.0 Licenseに従います。
画像生成
47.5K
Sana 1600M 1024px 多言語対応
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。このモデルは驚異的な速度で高解像度かつ高品質な画像を合成し、強力なテキストと画像の整合性を維持しながら、ノートパソコンのGPUにも展開可能です。Sanaモデルは線形拡散トランスフォーマーに基づいており、事前学習済みのテキストエンコーダーと空間圧縮された潜在特徴エンコーダーを使用し、絵文字、中国語、英語、およびそれらを組み合わせたプロンプトにも対応しています。
画像生成
45.3K
Sana 1600M 512px MultiLing
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。Sanaは、高速で高解像度かつ高品質の画像合成が可能であり、強力なテキストと画像の整合性も備えています。ノートパソコンのGPUでも動作します。このモデルは線形拡散変換器をベースとし、固定された事前学習済みテキストエンコーダと空間圧縮潜在特徴エンコーダを使用しており、英語、中国語、絵文字を組み合わせたプロンプトにも対応しています。Sanaの主な利点としては、高い効率性、高解像度画像生成能力、そして多言語対応が挙げられます。
画像生成
44.4K
Sana 1600M 1024px
SanaはNVIDIAが開発したテキストツーイメージ生成フレームワークであり、最大4096×4096ピクセルの高解像度で、テキストと画像の一貫性が高い画像を高速に生成できます。ノートパソコンのGPUでも展開可能です。Sanaモデルは線形拡散トランスフォーマーに基づいており、事前学習済みのテキストエンコーダーと空間圧縮された潜在特徴エンコーダーを使用しています。この技術の重要性は、高品質な画像を迅速に生成できる点にあり、芸術創作、デザイン、その他の創造的な分野に革命的な影響を与えます。SanaモデルはCC BY-NC-SA 4.0ライセンスに従い、ソースコードはGitHubで公開されています。
画像生成
47.2K
Sana 1600M 512px
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性、強力なテキストと画像の整合性、そしてノートパソコンのGPUでも動作するという特徴があります。線形拡散変換器をベースとし、事前学習済みのテキストエンコーダと空間圧縮された潜在的特徴エンコーダを使用しており、テキストから画像を生成する技術の最新進歩を代表しています。主な利点として、高解像度画像生成、高速合成、ノートパソコンのGPUでの展開可能性、そしてオープンソースコードが挙げられ、研究と実用アプリケーションの両方で大きな価値を持っています。
画像生成
46.4K
躍問ビデオ
躍問ビデオは、ひらめきとビデオ制作を統合したプラットフォームです。豊富なビジュアルとクリエイティブなコンテンツを提供することで、ユーザーの創造性を刺激し、独自のビデオ制作を支援します。本プラットフォームは、独特な美学と効率的なビデオ生成技術を主な強みとしており、特に中国風をテーマにした作品に秀でています。躍問ビデオは、階躍星辰社によって開発されました。同社はマルチモーダル技術において業界をリードしており、テキストからビデオへの生成技術を提供しています。製品は中高端市場をターゲットとしており、高品質なビデオ生成と最適化サービスでユーザーを魅了しています。
動画制作
171.4K
Sana 1.6B
Sana-1.6Bは、線形拡散変換器技術に基づく、高効率で高解像度の画像合成モデルです。NVIDIA研究所によって開発され、DC-AE技術を用いており、32倍の潜在空間を持ち、複数GPU上で動作し、強力な画像生成能力を提供します。Sana-1.6Bは、その効率的な画像合成能力と高品質な出力結果で知られており、画像合成分野における重要な技術です。
画像生成
45.5K

Sana
Sanaは、最大4096×4096ピクセルの高解像度画像を効率的に生成できるテキストツーイメージフレームワークです。高速で高解像度?高品質の画像合成を実現し、強力なテキストと画像の整合性を維持しつつ、ノートパソコンのGPUでも展開可能です。Sanaの中核設計には、深層圧縮自己符号化器、線形拡散変換器(DiT)、デコーダーのみの小型言語モデル(テキストエンコーダーとして)、そして効率的な学習とサンプリング戦略が含まれています。Sana-0.6Bは、最新の巨大拡散モデルと比較して、モデルサイズは20分の1、スループットは100倍以上高速です。さらに、Sana-0.6Bは16GBのノートパソコンGPUで展開可能で、1024×1024ピクセルの画像を1秒未満で生成できます。Sanaは、低コストのコンテンツ制作を可能にします。
画像生成
50.5K
Image Maker AI
Image Maker AIは、人工知能ベースの画像生成プラットフォームです。最先端のトランスフォーマーモデルとBlackForestLabsによる最新のAI研究を活用し、ハイエンドのプロフェッショナルプロジェクトから迅速な個人利用まで、幅広いニーズに対応します。12億パラメーターとFLUX.1 [Pro]、[Dev]、[Schnell]を含む複数のモデルバリエーションを備え、プロンプトへの忠実度、ディテール、出力の多様性を最適化しています。Image Maker AIでは、テキストプロンプトを入力し、スタイルを選択することで、AIが高解像度でディテールが豊富でリアルな画像を生成します。個人プロジェクトからプロフェッショナルな用途まで、幅広い用途に適しています。Fluxで生成されたすべての画像はロイヤリティフリーであり、個人または商業目的で利用でき、著作権に関する心配はありません。
画像生成
48.0K
Cogvideox1.5 5B SAT
CogVideoX1.5-5B-SATは、清華大学知識工程とデータマイニングチームが開発したオープンソースの動画生成モデルであり、CogVideoXモデルのアップグレード版です。このモデルは10秒間の動画生成に対応し、より高解像度の動画生成も可能です。Transformer、VAE、Text Encoderなどのモジュールを含んでおり、テキストの説明に基づいて動画コンテンツを生成できます。CogVideoX1.5-5B-SATモデルは、その強力な動画生成能力と高解像度サポートにより、特に教育、エンターテインメント、ビジネス分野において幅広い用途を持つ、動画コンテンツ制作者のための強力なツールとなります。
映像制作
66.8K
FLUX 1.1 Pro Ultra
FLUX 1.1 [pro]は、最大4MPの高解像度画像生成をサポートするモデルです。サンプル1枚あたりの生成時間はわずか10秒です。FLUX 1.1 [pro] – ultraモードでは、速度を犠牲にすることなく、標準解像度の4倍の解像度で画像を生成できます。ベンチマークテストでは、同等の高解像度モデルと比較して2.5倍以上の生成速度を実現しています。さらに、FLUX 1.1 [pro] – rawモードは、写実性を追求するクリエイターのために、より自然で合成感が少ない画像生成効果を提供し、人物の多様性と自然写真の写実性を大幅に向上させます。価格は画像1枚あたり0.06ドルと競争力があります。
画像生成
86.7K
Mochi 1 AI
Mochi 1は、Genmoが開発した最先端のオープンソースAI動画ジェネレーターです。クリエイターは、テキストや画像のプロンプトを使用して、高品質でリアルな動画を生成できます。Mochi 1は、優れたプロンプトへの追従性と滑らかな動きで、AI動画生成を誰もが簡単に利用できるようにします。業界の他のモデルと競合することを目指し、クリエイターにより多くの制御と優れた視覚的な成果を提供します。
映像制作
55.5K
IC Light V2
IC-Light V2は、FluxベースのIC-Lightモデルシリーズです。16ch VAEとネイティブ高解像度技術を採用しており、前世代モデルと比較して、細部保持とスタイリッシュな画像処理において大幅な性能向上を実現しています。画像の細部を維持しながらスタイリッシュな処理が必要なアプリケーションに最適です。現在、非商業利用目的で公開されており、個人ユーザーと研究者を主な対象としています。
画像生成
59.1K

Hallo2
Hallo2は、潜在拡散生成モデルに基づく人物画像アニメーション技術です。音声駆動により、高解像度で長時間のビデオを生成します。複数の設計改良を取り入れることで、Halloの機能を拡張し、長時間のビデオ生成、4K解像度のビデオ生成、テキストプロンプトによる表情制御の強化などを実現しました。Hallo2の主な利点としては、高解像度出力、長時間における安定性、テキストプロンプトによる制御性の向上といった点が挙げられ、多様で豊かな肖像アニメーションコンテンツの生成において顕著な優位性を持ちます。
AI画像生成
64.6K

Meissonic
Meissonicは、非自己回帰型のマスク画像モデリングを用いたテキスト?ツー?イメージ合成モデルであり、高解像度の画像生成が可能です。コンシューマ向けGPUでも動作するように設計されており、既存のハードウェアリソースを活用して、高品質な画像生成体験を効率的に提供します。Meissonicに関する背景情報としては、arXivへの論文掲載、Hugging Faceでのモデルとコードの公開があります。
AI画像生成
44.7K
高品質新製品
Photo4you
photo4youは、人工知能技術に基づいたオンライン証明写真作成サイトです。ソフトウェアのダウンロードやインストールは不要で、簡単に証明写真を作成できます。パスポート、ビザ、運転免許証など、様々な標準サイズに対応しており、AIによるスマートな背景除去機能で、写真の背景を自動的に削除し、クリアでプロフェッショナルな仕上がりを実現します。作成した証明写真はすぐにダウンロードでき、時間と手間を節約できます。photo4youは高解像度出力に対応しており、印刷やデジタル提出に最適です。
AI画像編集
50.5K
Cogview3
CogView3は、カスケード拡散に基づくテキストから画像生成システムであり、リレー拡散フレームワークを使用しています。このシステムは、高解像度画像生成プロセスを複数の段階に分割し、リレー超解像度プロセスを通じて、低解像度生成結果にガウスノイズを追加することで、これらのノイズを含む画像からの拡散プロセスを開始します。CogView3は、より高速な生成速度とより高い画像品質を備え、SDXLを上回る画像生成能力を有しています。
AI画像生成
63.2K
Follow Your Canvas
Follow-Your-Canvasは、拡散モデルに基づいた動画拡張技術です。高解像度の動画コンテンツを生成できます。分散処理と空間ウィンドウの統合により、GPUメモリ制限の問題を解決しつつ、動画の空間的および時間的一貫性を維持します。大規模な動画拡張において優れた性能を発揮し、512 x 512から1152 x 2048など、動画解像度を大幅に向上させながら、高品質で視覚的に魅力的な結果を生成します。
AI動画生成
47.7K
海外精選
画像品質向上ツール
画像品質向上ツールは、人工知能を搭載したウェブサイトで、オンライン画像の高画質化サービスを提供しています。本ツールでは、画像を最大10倍に拡大し、12Kの高解像度を実現しながら、鮮明度を大幅に向上させることができます。大型プリント、デザインプロジェクト、ソーシャルメディアへの投稿など、高画質の画像が必要なユーザーにとって最適なツールです。
画像編集
63.8K
高品質新製品
FIFO Diffusion
FIFO-Diffusionは、テキスト条件付き動画生成のための、事前学習済み拡散モデルに基づく新規な推論技術です。訓練なしで無限長の動画を生成でき、対角ノイズ除去を繰り返し実行することで、キュー内の一連の連続フレームの徐々に増加するノイズレベルを処理します。この方法は、完全にノイズ除去されたフレームを先頭から取り出し、同時に新しいランダムノイズフレームを末尾に追加します。さらに、潜在分割を導入して訓練推論のギャップを減らし、先読みノイズ除去によって前方参照の利点を活用します。
AI動画生成
114.5K
Ttplanet SDXL ControlNet Tile Realistic
これはSDXLベースのControlNet Tileモデルで、Hugging Face Diffusersのトレーニングセットを使用して訓練されました。Stable Diffusion SDXL ControlNetに対応しています。元々は、私自身のリアルなモデルのトレーニングのために、究極のアップスケーリングプロセスで画像の詳細を向上させるために作成されました。適切なワークフローを使用することで、高詳細で高解像度の画像修復に良好な結果を提供します。ほとんどのオープンソースにSDXL Tileモデルがないため、このモデルを共有することにしました。このモデルは、高解像度修復、スタイル転送、画像修復などの機能をサポートし、高品質の画像処理体験を提供します。
AI画像生成
102.1K
背景画像
Backgroundは、AIによって生成された背景画像を提供するプラットフォームです。ユーザーは、6Kの高解像度で提供される、驚くほど美しいAI生成の背景画像を閲覧してダウンロードできます。各背景画像にはMidjourneyのプロンプトが付属しており、ユーザーは画像の生成プロセスを理解することができます。Backgroundは、金属調、ネオンカラー、抽象的な光と影など、多様なスタイルを網羅した、様々な背景画像コレクションを提供しています。ユーザーは自身のデザインプロジェクトやニーズに合わせて最適な背景画像を選択できます。プラットフォームは定期的に背景画像を更新し、無料のプレゼントも提供しています。価格情報については、公式ウェブサイトをご覧ください。
画像生成
61.5K
グリフォン
グリフォンは、1Kを超える高解像度で、関心領域内のあらゆる情報を記述できる、初のローカリゼーション機能を備えたLVLMです。最新バージョンでは、視覚言語コアファレンスに対応しています。画像または説明を入力できます。グリフォンは、REC、物体検出、物体計数、視覚/フレーズ特定、REGにおいて優れた性能を発揮します。価格:無料トライアル。
AI画像検出識別
48.0K

PIXART Σ
PIXART-Σは、4K解像度の画像を直接生成する拡散トランスフォーマーモデルです。前身であるPixArt-αと比較して、より高い画像忠実度とテキストプロンプトとの優れた整合性を提供します。PIXART-Σの重要な特徴には、効率的なトレーニングプロセスが含まれます。これは、より高品質なデータを使用することで、「弱い」ベースラインモデルから「より強力な」モデルへと進化させる「弱から強へのトレーニング」と呼ばれるプロセスです。PIXART-Σの改良には、より高品質なトレーニングデータの使用と効率的なトークン圧縮が含まれます。
AI画像生成
481.3K
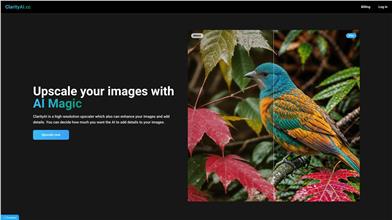
Clarityai
ClarityAI.ccは、最新のAI技術を採用した高解像度画像拡大?高画質化ツールです。画像のディテールを強化し、超高解像度を実現します。風景、人物写真、イラスト、アニメ、インテリアデザインなど、様々なシーンで活用できます。無料オプションも提供しています。
画像強化
85.0K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
37.8K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M