%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
中国語精選
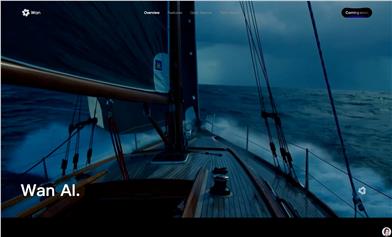
Wan
Wanはアリババの通義实验室が開発した、強力な動画生成能力を備えた高度なビジュアル生成モデルです。テキスト、画像、その他の制御信号に基づいて動画を生成できます。Wan 2.1シリーズモデルは完全オープンソース化されています。主な特長として、複雑な動作の生成能力の高さ(幅広い身体動作、複雑な回転、動的なシーン遷移、滑らかなカメラワークを含むリアルな動画の生成)、正確な物理シミュレーション(現実世界の物理法則に沿った動画の生成)、映画のような質感(豊富なテクスチャと多様なスタイリッシュな効果)、制御可能な編集機能(画像や動画を参考に正確な編集が可能)が挙げられます。このモデルのオープンソース化は、動画生成分野に新たな可能性をもたらし、利用障壁を下げ、関連技術の発展を促進します。
映像制作
58.0K

Videojam
VideoJAMは、外観とモーションの統合表現を用いることで、動画生成モデルのモーションの一貫性と視覚品質を向上させる革新的な動画生成フレームワークです。本技術は、内側誘導機構(Inner-Guidance)を導入し、モデル自身によって予測されたモーション信号で動画生成を動的に誘導することで、複雑なモーションタイプの生成において優れた性能を発揮します。VideoJAMの主な利点は、高品質な視覚効果を維持しながら、動画生成の一貫性を大幅に向上させることができる点です。更に、トレーニングデータやモデルアーキテクチャの大規模な変更なしに、あらゆる動画生成モデルに適用可能です。本技術は、特にモーションの一貫性が高いことが求められる場面において、動画生成分野で重要な応用可能性を秘めています。
映像制作
62.7K
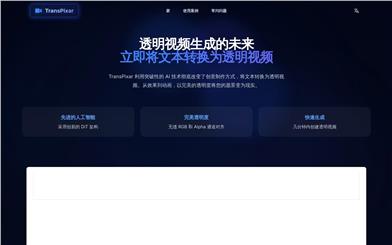
Transpixar.pro
TransPixarは、高度な人工知能技術に基づいた透明ビデオ生成ツールです。革新的なDiTアーキテクチャを採用し、テキストの説明を高速で高品質な透明ビデオに変換し、RGBとアルファチャンネルの完璧なアライメントを実現します。この技術はクリエイティブ制作分野において重要な意味を持ち、制作効率の大幅な向上とコスト削減に貢献し、VFX、アニメーション制作などに全く新しいソリューションをもたらします。現在、この製品は主にクリエイティブのプロフェッショナルを対象としており、効率的でプロフェッショナルな透明ビデオ生成サービスを提供しています。具体的な価格は明示されていませんが、そのポジショニングから有料であると考えられます。
映像制作
45.8K
Transpixar
TransPixarは、透明度チャンネルを含むRGBA動画を生成できる高度なテキスト動画生成モデルです。拡散トランスフォーマー(DiT)アーキテクチャとLoRAベースのファインチューニング手法を組み合わせることで、RGBとアルファチャンネルの高い整合性を実現しています。TransPixarは、視覚効果(VFX)やインタラクティブコンテンツ制作において重要な役割を果たし、エンターテインメント、広告、教育など様々な業界に多様なコンテンツ生成ソリューションを提供します。主な利点としては、効率的なモデル拡張性、強力な生成能力、限られたトレーニングデータに対する最適化処理能力が挙げられます。
映像制作
50.0K
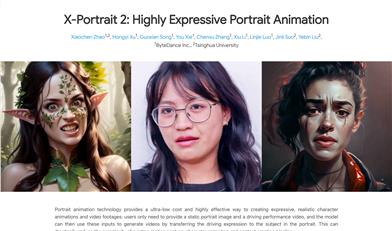
X Portrait 2
バイトダンスインテリジェントクリエイションチームが開発した最新のシングルイメージビデオ駆動技術、X-Portrait 2。X-Portrait 2は、ユーザーが提供した静止画の肖像と駆動パフォーマンスビデオから、高度な表現力とリアルさを備えたキャラクターアニメーションとビデオクリップを生成する肖像アニメーション技術です。この技術は、既存のモーションキャプチャ、キャラクターアニメーション、コンテンツ制作プロセスの複雑さを大幅に軽減します。X-Portrait 2は、最先端の表情エンコーダーモデルを構築し、入力された微細な表情を暗黙的にエンコードし、大規模データセットでトレーニングされています。その後、このエンコーダーと強力な生成拡散モデルを組み合わせることで、滑らかで表現力豊かなビデオを生成します。X-Portrait 2は、唇をすぼめる、舌を出す、頬を膨らませる、眉をひそめるなど、難しい表情を含む微妙で微細な表情を伝え、生成されたビデオで高忠実度の感情表現を実現します。
映像制作
71.2K

多照明合成による放射場再照明への拡散アプローチ
2D画像拡散モデルから抽出された事前知識を利用して、再照明可能な放射場を作成する手法です。単一照明条件下で取得された多視点データを、多照明効果を持つデータセットに変換し、3Dガウススプラインを用いて再照明可能な放射場を表します。この手法は正確な形状や表面法線に依存しないため、複雑な形状や反射BRDFを持つ複雑なシーンの処理に適しています。
AI画像生成
46.6K
高品質新製品
Morphic Studio
Morphic Studioは、革新的なストーリーテリングプラットフォームです。最先端技術を用いて、没入型でインタラクティブなストーリー体験を提供します。最新のインタラクション技術と視覚効果により、ユーザーはストーリーにより深く没頭し、その魅力を存分に味わうことができます。Morphicの主な利点としては、1. 没入型体験、2. 高いインタラクティブ性、3. 際立つ視覚効果、4. 操作と使用の容易さ、が挙げられます。製品背景情報では、Morphicは技術革新を通じてストーリーテリング方法の変革を推進し、現代の視聴者の高品質なコンテンツへのニーズに応えることを目指しています。
その他分類
49.1K
2D画像3D変換コンバーター
Stylar AIの2D画像3D変換コンバーターは、高度な画像間変換技術を用いて、平面的な2D画像を3D画像に変換する強力なツールです。高品質な画像変換と多彩なスタイルオプションを提供し、ユーザーの3D化ニーズを満たします。主な機能には、画像アップロード、3D効果の選択、3D作品ダウンロードなどがあります。3Dカートゥーン風効果、3Dアート作品風など、様々な3Dスタイルと、スケッチからの3Dデザイン変換機能も提供します。
AI画像生成
73.1K
Make Your Anchor
Make-Your-Anchorは、拡散モデルに基づく2Dバーチャルアバター生成フレームワークです。約1分の動画素材があれば、上半身と手の動きを正確に再現した、配信者風動画を自動生成できます。本システムは、構造ガイド付きの拡散モデルを用いて3Dメッシュの状態を人物の外見としてレンダリングします。二段階の学習戦略により、動きと特定の外見を効果的に結びつけます。任意の長さの時系列動画を生成するために、フレーム単位の拡散モデルの2D U-Netを3D形式に拡張し、シンプルかつ効果的なバッチオーバーラップ時系列ノイズ除去モジュールを提案することで、推論時の動画の長さに関する制限を突破しました。最後に、特定のアイデンティティに基づいた顔の強化モジュールを導入し、出力動画の顔領域の視覚品質を向上させています。実験により、本システムは視覚品質、時系列の一貫性、アイデンティティの忠実度において、既存技術を上回ることが示されました。
AI画像生成
119.2K
Animatable
Animatableは、動画を魅力的なアニメーションに変換できるAIアニメーションプラットフォームです。視聴者を魅了するアニメーションを作成できます。ユーザーは好みに合わせて様々なスタイルを選択し、自由に創造性を発揮できます。プラットフォームは高速で生成され、動画変換には1秒あたり7ポイント、プレビュー画像1枚あたり1ポイントを消費します。ベーシックプランとプロプランがあり、それぞれ月間1000ポイントと3000ポイントが提供され、商用利用が可能です。
映像編集
399.6K
Dopepics
dopepics.ioは、ありふれた写真を卓越したビジュアル体験に変換するAI製品です。どんな画像でもアップロードしていただければ、50種類もの改良版を、驚くべき8Kの高画質で提供します。画像に欠陥や不要なマーク、文字があっても問題ありません。さらに、必要に応じてより高解像度での処理も可能です。当社のAIを信頼して、ありふれた写真を特別な写真に変えましょう。
画像編集
50.0K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.7K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
39.2K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
39.5K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.4K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M