%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
BEN2
BEN2(Background Erase Network)は、Confidence Guided Matting(CGM)プロセスを採用した革新的な画像セグメンテーションモデルです。モデルの確信度が低いピクセルを専門に処理する細分化ネットワークにより、より正確な切り抜きを実現します。BEN2は、髪の毛の切り抜き、4K画像処理、オブジェクトセグメンテーション、エッジの細分化において優れた性能を発揮します。基本モデルはオープンソースであり、ユーザーはAPIまたはWebデモを通じて完全なモデルを無料で試用できます。このモデルのトレーニングデータには、DIS5kデータセットと22Kの独自のセグメンテーションデータセットが含まれており、多様な画像処理ニーズに対応できます。
画像編集
51.6K
Wepoints
WePOINTSは、微信AIチームが開発した、様々なモダリティに対応する一連の多様なモダリティモデルです。様々なモダリティを統合する統一フレームワークを構築することを目指しています。これらのモデルは、最新の多様なモダリティモデルの進歩と技術を活用し、コンテンツの理解と生成のシームレスな統合を促進します。WePOINTSプロジェクトは、モデルだけでなく、事前学習済みデータセット、評価ツール、使用方法のチュートリアルも提供しており、多様なモダリティ人工知能分野における重要な貢献です。
AIモデル
45.5K
RMBG 2.0
RMBG-2.0は、BRIA AIが開発した背景除去モデルであり、画像の前景と背景を効果的に分離することを目的としています。汎用ストック画像、eコマース、ゲーム、広告コンテンツを含む厳選されたデータセットでトレーニングされており、ビジネスユースケースに適しており、大規模な企業コンテンツ制作を推進できます。その精度、効率性、多機能性は、主要なオープンソースモデルと比較しても遜色ありません。RMBG-2.0は、非商業目的で使用するためのソースコードとして利用可能なモデルです。
背景除去
66.8K
海外精選
Birefnet
BiRefNetは、高精度な画像セグメンテーションに特化したモデルです。双方向参照技術を用いて、高解像度の2値画像セグメンテーションを実現します。本技術は、教育、医療、地理情報など様々な分野で幅広く活用されており、特に医学画像処理や自動運転車など、精密な画像分割による更なる分析が必要な場面で有効です。
画像編集
57.7K
Comfyui Segment Anything 2
ComfyUI-segment-anything-2は、segment-anything-2モデルに基づいた画像セグメンテーションライブラリです。ComfyUIノードを通じて、ユーザーは簡単に画像セグメンテーションを実行できます。現在開発段階ですが、主要機能は利用可能です。モデルの自動ダウンロードとComfyUIへの統合により、ユーザーフレンドリーな画像セグメンテーションソリューションを提供します。
AI画像編集
61.0K
高品質新製品
AIスマート画像セグメンテーション
AIスマート画像セグメンテーションは、Figmaベースのプラグインです。最先端のSegment Anythingモデル(SAM)と??Transformers.js技術を用いて、デザイナーやアーティストにインタラクティブで正確な画像分割ツールを提供します。クリック操作で画像からのオブジェクトや領域の抽出プロセスを簡素化し、デザイン効率を大幅に向上させ、創造性を解き放ちます。このプラグインは無料でオープンソースであり、ユーザーによるカスタマイズと開発への貢献が可能です。
画像編集
60.2K
RMBG V1.4
RMBG-1.4は、BRIA AIが開発したPytorchベースの画像背景除去モデルです。専門的なデータセットを用いてトレーニングされており、前景と背景を効率的かつ正確に分割できます。その精度、効率性、汎用性は、現在、主要なオープンソースモデルに匹敵するレベルに達しており、企業における大規模コンテンツ制作のビジネスユースケースにも適しています。合法的にライセンスされたトレーニングデータセットを使用し、モデルのバイアスを効果的に軽減することで、コンテンツの安全性にも特に配慮しています。
AI画像編集
327.6K

Emerdiff
EmerDiffは、拡散モデルから抽出されたセマンティック知識を利用して、追加の訓練なしで、きめ細かいセグメンテーションマップを生成することを目的とした最新の拡散モデルです。Stable Diffusion(SD)から抽出されたセマンティック知識を利用することで、低次元特徴マップからの画素レベルのセマンティック関係の直接抽出という課題を克服し、これらの関係を利用して画像解像度のセグメンテーションマップを構築します。広範な実験により、生成されたセグメンテーションマップは鮮明で、画像の詳細な部分を捉えていることが検証されており、拡散モデルには高精度な画素レベルのセマンティック知識が存在することを示しています。
AI画像生成
45.8K

Actanywhere
ActAnywhereは、前景の主体動作や外観と一致するビデオ背景を自動生成するモデルです。このタスクは、前景の主体動作や外観と一致するだけでなく、アーティストの意図にも沿った背景を合成することを含みます。ActAnywhereは大規模ビデオ拡散モデルを活用し、このタスク向けに特化して開発されました。ActAnywhereは、前景の主体セグメンテーションのシーケンスを入力として、必要なシーンを記述する画像を条件として、条件フレームと整合性のある連続ビデオを生成し、現実的な前景と背景の相互作用を実現します。このモデルは大規模な人とコンピューターのインタラクションビデオデータセットでトレーニングされています。多くの評価により、このモデルは基準モデルよりも明らかに優れた性能を示し、人間以外の主体を含む様々な分布サンプルに対して汎化できることが示されています。
AI動画生成
165.6K
Sam.cpp
Samは、C++からゼロから実装された画像セグメンテーションモデルです。追加のコードや注釈なしで、画像のピクセルレベルのセグメンテーションとオブジェクト境界の特定が可能です。MetaのSegment Anything Modelをベースとし、Transformerアーキテクチャを用いてエンドツーエンドの画像セグメンテーション予測を行います。シンプルで使いやすいC++インターフェースを提供し、コマンドラインとグラフィカルインターフェースの両方の使用方法をサポートしています。SamはCPU上で効率的に動作し、モデルサイズが小さく、良好なセグメンテーション精度を確保しています。GPUを使用できない組み込み環境での画像セグメンテーションモデルの展開と使用に最適です。
AI画像分割
70.7K
海外精選
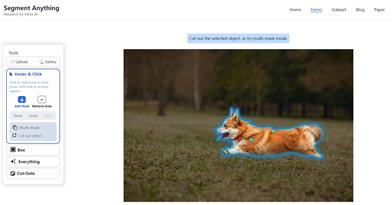
Segment Anything
SAMは、プロンプト可能なセグメンテーションシステムです。追加のトレーニングなしで、未知のオブジェクトや画像にもゼロショット汎化が可能です。様々な入力プロンプトを用いて、幅広いセグメンテーションタスクを、追加のトレーニングなしで実行できます。そのプロンプト可能な設計により、他のシステムとの柔軟な統合が可能です。1100万枚の画像と10億個のセグメンテーションマスクでトレーニングされており、効率的なモジュール設計により、数ミリ秒で推論を実行できます。Segment Anything Model (SAM)は、テキスト指示などによって画像セグメンテーションを実現するモデルであり、あらゆるものが認識され、ワンクリックで切り抜きが可能です。画像をアップロードしてオブジェクトをクリックするだけで認識できます。
画像編集
217.8K
Skyglass
Skyglassは、AIを活用した画像処理ツールです。画像認識、画像強調、画像セグメンテーションなどの機能を提供し、ユーザーの画像最適化と処理を迅速化し、作業効率を向上させます。柔軟な価格設定で、個人ユーザーと企業ユーザーの両方に対応しており、効率的で使いやすい画像処理ソリューションを提供することを目指しています。
画像編集
50.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.5K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M