%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Janus Pro 1B
Janus-Pro-1Bは、多様なモダリティの理解と生成に特化した革新的な多様なモダリティモデルです。視覚エンコーディングパスを分離することで、従来の方法が理解と生成タスクにおいて抱えていた矛盾を解消し、同時に単一の統一されたTransformerアーキテクチャを維持しています。この設計により、モデルの柔軟性が向上するだけでなく、多様なモダリティタスクにおいて優れた性能を発揮し、特定タスクのモデルを上回る結果も得られています。DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-baseを基盤とし、視覚エンコーダーとしてSigLIP-Lを採用、384x384の画像入力をサポートし、専用のイメージ生成トクナイザを使用しています。オープンソースであり柔軟性が高いため、次世代の多様なモダリティモデルの有力候補となっています。
AIモデル
70.7K
人類最後の試験 (Humanity's Last Exam)
人類最後の試験 (Humanity's Last Exam) は、世界中の専門家による協働で開発された多様なモダリティを含むベンチマークテストであり、大規模言語モデルの学術分野におけるパフォーマンスを測定することを目的としています。50カ国以上500以上の機関から約1000名の専門家が貢献した3000問以上の問題を含み、100以上の学問分野を網羅しています。本テストは、モデルの限界に挑戦することで人工知能技術の発展を促進することを目的とした、最終的なクローズド型の学術ベンチマークとなることを目指しています。主な利点はその難易度が高く、複雑な学術問題に対するモデルのパフォーマンスを効果的に評価できる点です。
AIモデル
52.4K
Internvl2 5 26B MPO
InternVL2_5-26B-MPOは、多様なモダリティに対応する大規模言語モデル(MLLM)です。InternVL2.5をベースに、混合選好最適化(Mixed Preference Optimization, MPO)を用いてモデル性能をさらに向上させています。画像やテキストを含む多様なモダリティのデータを処理でき、画像キャプション生成、ビジュアルクエスチョン?アンサーリングなど幅広い用途に適用可能です。画像の内容と密接に関連したテキストの理解と生成が可能である点が重要であり、多様なモダリティに対応する人工知能の境界を押し広げています。製品の背景情報には、多様なモダリティに対応するタスクにおける卓越した性能と、OpenCompass Leaderboardにおける評価結果が含まれます。本モデルは、研究者や開発者が多様なモダリティに対応する人工知能の可能性を探求し、実現するための強力なツールを提供します。
AIモデル
47.7K
Internvl2 5 8B MPO AWQ
InternVL2_5-8B-MPO-AWQは、OpenGVLabが開発した多様なモダリティに対応する大規模言語モデルです。InternVL2.5シリーズをベースに、混合選好最適化(Mixed Preference Optimization, MPO)技術を採用しています。このモデルは、視覚と言語の理解と生成において卓越した性能を示し、特に多様なモダリティを扱うタスクで優れた成果を上げています。視覚部分はInternViT、言語部分はInternLMまたはQwenを組み合わせ、ランダムに初期化されたMLPプロジェクターを用いた増分プリトレーニングにより、画像とテキストの深い理解と相互作用を実現しています。本技術の重要性は、単一画像、複数画像、動画データを含む様々なデータタイプを処理できる点にあり、多様なモダリティに対応する人工知能分野に新たなソリューションを提供します。
AIモデル
45.5K
Internvl2 5 4B MPO AWQ
InternVL2_5-4B-MPO-AWQは、画像とテキストの相互作用タスクにおけるモデルのパフォーマンス向上に焦点を当てた、多様なモダリティを持つ大規模言語モデル(MLLM)です。InternVL2.5シリーズをベースとし、混合嗜好最適化(MPO)によって性能がさらに向上しています。単一画像や複数画像、動画データなど、多様な入力に対応可能であり、画像とテキストの相互理解が必要な複雑なタスクに適しています。InternVL2_5-4B-MPO-AWQはその優れた多様なモダリティ能力により、画像とテキストからテキストを生成するタスクに強力なソリューションを提供します。
AIモデル
48.0K
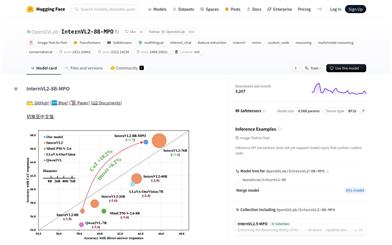
Internvl2 8B MPO
InternVL2-8B-MPOは、混合選好最適化(MPO)プロセスを導入することで、多様なモダリティ推論能力を強化した多様なモダリティ大規模言語モデル(MLLM)です。自動化された選好データ構築パイプラインを設計し、大規模な多様なモダリティ推論選好データセットであるMMPRを構築しました。InternVL2-8Bを初期化モデルとし、MMPRデータセットを用いてファインチューニングすることで、より強力な多様なモダリティ推論能力と、より少ない幻覚現象を実現しています。MathVistaにおいて67.0%の精度を達成し、InternVL2-8Bを8.7ポイント上回り、10倍規模のInternVL2-76Bに匹敵する性能を示しています。
AIモデル
45.5K

モーション言語
スタンフォード大学研究チームが開発した、3D人体動作における言語と非言語を統合する多様なモダリティを扱う言語モデルフレームワークです。テキスト、音声、動作を含む多様なモダリティデータを理解?生成し、自然なコミュニケーションが可能なバーチャルキャラクターの作成に不可欠です。ゲーム、映画、仮想現実などの分野で幅広く活用できます。柔軟性の高さ、少ないトレーニングデータで済むこと、編集可能なジェスチャー生成や動作からの感情予測といった新たなタスクを可能にする点が主な利点です。
AI画像生成
46.6K
Wepoints
WePOINTSは、微信AIチームが開発した、様々なモダリティに対応する一連の多様なモダリティモデルです。様々なモダリティを統合する統一フレームワークを構築することを目指しています。これらのモデルは、最新の多様なモダリティモデルの進歩と技術を活用し、コンテンツの理解と生成のシームレスな統合を促進します。WePOINTSプロジェクトは、モデルだけでなく、事前学習済みデータセット、評価ツール、使用方法のチュートリアルも提供しており、多様なモダリティ人工知能分野における重要な貢献です。
AIモデル
45.5K
Janus 1.3B
Janusは、視覚エンコーディングを分離することで、多様なモダリティの理解と生成を統合した革新的な自己回帰フレームワークです。この分離により、視覚エンコーダーの理解と生成における役割の競合が緩和され、フレームワークの柔軟性が向上します。Janusは従来の統合モデルを凌駕し、特定タスクのモデルと同等以上の性能を達成します。その簡潔さ、高い柔軟性、有効性から、次世代の統合型多様なモダリティモデルの有力候補と言えます。
AIモデル
49.4K
海外精選

Molmo
Molmoは、オープンソースで最先端の多様なモダリティに対応するAIモデル群です。知覚対象への学習を通じて、物理世界および仮想世界との豊かなインタラクションを実現し、次世代アプリケーションにアクションとインタラクションの能力を提供します。Molmoは、知覚対象への学習を通じて、物理世界および仮想世界との豊かなインタラクションを実現し、次世代アプリケーションにアクションとインタラクションの能力を提供します。
AIモデル
58.8K
高品質新製品
Pixtral 12B
Pixtral 12Bは、Mistral AIチームが開発した多様なモダリティに対応するAIモデルです。自然画像と文書を理解し、優れた多様なモダリティのタスク処理能力を備えています。同時に、テキストのベンチマークテストでも最先端の性能を維持しています。様々な画像サイズとアスペクト比に対応し、長いコンテキストウィンドウ内で任意の数の画像を処理できます。Mistral Nemo 12Bのアップグレード版であり、多様なモダリティの推論用に設計されており、重要なテキスト処理能力を犠牲にすることはありません。
AIモデル
45.5K
Llava OneVision
LLaVA-OneVisionは、バイトダンス社と複数の大学との共同開発による大規模多様なモダリティモデル(LMMs)です。単一画像、複数画像、動画の各シーンにおいて、オープンな大規模多様なモダリティモデルのパフォーマンス限界を押し広げています。本モデルは、異なるモダリティ/シーン間での強力な転移学習を可能にする設計となっており、特に動画理解やシーン横断能力において新たな総合的な能力を示しています。これは、画像から動画へのタスク変換によって実証されています。
AIモデル
71.8K
UNIMO G
UNIMO-Gは、複雑に交錯するテキストと視覚情報の入力を処理するための、シンプルで多様なモダリティに対応した条件付き拡散フレームワークです。2つの主要な構成要素から成り立っています。一つは、多様なモダリティの情報を統合する多様なモダリティ対応大規模言語モデル(MLLM)、もう一つは、エンコードされた多様なモダリティの入力に基づいて画像を生成する条件付きノイズ除去拡散ネットワークです。効率的なフレームワーク構築のため、2段階のトレーニング戦略を採用しています。まず、大規模なテキスト?画像ペアデータで事前学習を行い、条件付き画像生成能力を開発します。次に、多様なモダリティの情報を統合したプロンプトによるファインチューニングを行い、統一的な画像生成能力を実現しています。多様なモダリティのプロンプト構築には、言語接地と画像セグメンテーションを含む、綿密に設計されたデータ処理プロセスを採用しています。UNIMO-Gは、テキストから画像への生成やゼロショットテーマ主導合成において優れた性能を示し、複数の画像エンティティを含む複雑な多様なモダリティのプロンプトから高忠実度の画像を生成する点で非常に有効です。
AI画像生成
112.6K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.5K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M