%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

P20V
P20Vは、数秒で画像や動画を変換できる無料のAIプラットフォームです。ログインが不要で、マーケティング、デザイン、建築、ファッション、ゲーム、電子商取引などを含む複数の業界で活用できます。ユーザーはプロ級のビジュアルコンテンツを作成し、クリエイティブなコミュニティとシェアできます。
AIデザインツール
38.1K
Bilive
biliveはbilibiliライブ録画用に設計されたツールで、自動セグメンテーション、弾幕レンダリング、字幕生成に対応しており、低スペックデバイスにも対応し、幅広いユーザー層に適しています。主な利点は、ライブコンテンツを効率的に処理し、複数の部屋の録画に対応し、高品質のコンテンツとサムネイルを生成することで、ユーザーが録画結果を迅速に共有できるようにすることです。個人や小規模チームに適しています。この製品はオープンソースで無料で使用でき、ユーザーに利便性を提供することに尽力しています。
["ビデオ ??????],["スイッチング カーパワー]
39.2K

Describe Anything
Describe Anythingモデル(DAM)は、画像または動画の特定の領域を処理し、詳細な記述を生成できます。主な利点は、単純なマーキング(点、枠、落書き、またはマスク)によって高品質の局所的な記述を生成できることであり、コンピュータビジョン分野における画像理解能力を大幅に向上させます。このモデルは、NVIDIAと複数の大学が共同で開発したもので、研究、開発、および実用アプリケーションに適しています。
家庭用品
38.4K
AI動画テキスト作成アシスタント
AI動画テキスト作成アシスタントは、動画や音声コンテンツを様々な形式の文書に変換し、ユーザーによる二次的な読書と考察を支援することを目的としたオープンソースツールです。この製品の主な利点は、完全にオープンソースであり、登録不要で、ユーザーはローカルで音声?動画ファイルを処理できるため、使用コストが低いことです。視覚的?聴覚的コンテンツをテキストに変換する必要がある学生、研究者、コンテンツクリエイターに最適です。
["レディースファッション],["メンズファッション]
38.1K
Visionagent
VisionAgentは、人工知能と大規模言語モデル(LLM)を活用してコードを生成し、ユーザーがビジョンタスクを迅速に解決できる強力なツールです。複雑なビジョンタスクを実行可能なコードに自動変換できるため、開発効率を大幅に向上させることができます。複数のLLMプロバイダーに対応しており、ユーザーはニーズに合わせて異なるモデルを選択できます。ビジョンアプリケーションを迅速に開発する必要がある開発者や企業に適しており、短時間で強力なビジョンソリューションを実現できます。VisionAgentは現在無料で提供されており、ユーザーに効率的で便利なビジョンタスク処理機能を提供することを目的としています。
コードアシスタント
53.3K
高品質新製品
ワンショットlora
ワンショットLoRAは、動画からLoRAモデルを迅速に学習することに特化したオンラインプラットフォームです。高度な機械学習技術を活用し、動画コンテンツを効率的にLoRAモデルに変換することで、ユーザーに迅速かつ容易なモデル生成サービスを提供します。この製品の主な利点は、操作がシンプルで、ログイン不要、さらにプライバシーが保護されている点です。ユーザーの個人データのアップロードは不要であり、いかなるユーザー情報も保存または収集しません。ユーザーデータのプライバシーと安全性を確保しています。この製品は、デザイナーや開発者など、LoRAモデルを迅速に生成する必要があるユーザーを主な対象としており、必要なモデルリソースを迅速に取得し、作業効率を向上させるお手伝いをします。
モデルトレーニングとデプロイ
57.4K
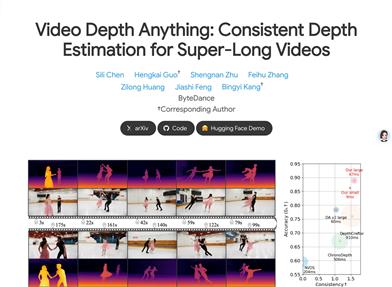
Video Depth Anything
Video Depth Anythingは、深層学習に基づく動画深度推定モデルであり、超長動画に対して高品質で時間的に一貫性のある深度推定を提供します。Depth Anything V2をベースに開発されており、強力な汎化能力と安定性を備えています。主な利点としては、任意の長さの動画への対応、時間的一貫性、そしてオープンワールド動画への優れた適応性などが挙げられます。本モデルは、バイトダンス(ByteDance)の研究チームによって開発され、時間的一貫性や複雑なシーンへの対応といった、長動画の深度推定における課題解決を目指しています。現在、コードとデモが公開されており、研究者や開発者が利用できます。
映像編集
46.9K
Zight
Zight AIは、高度な自然言語処理技術を用いて、動画のタイトル、要約、字幕、多言語翻訳を迅速に生成する、動画コンテンツ処理に特化したインテリジェントツールです。主な利点は、自動化レベルが高く、ユーザーの時間と労力を大幅に節約できることに加え、動画コンテンツのアクセシビリティと使いやすさを向上させることです。Zight AIは、企業研修、顧客サービス、教育など、様々な場面で使用でき、インテリジェントな手段を通じて動画コンテンツの生産性を向上させることを目指しています。価格は従量制で、ユーザー1人あたり月額4ドルからご利用いただけます。動画コンテンツを効率的に処理する必要がある個人やチームに最適です。
映像編集
54.4K
Endlessai
EndlessAIはAI動画機能を中核としたプラットフォームであり、現在ステルスモードで運用されています。App Storeで提供されているLloydスマートフォンアプリを通じてデモ版を提供しており、ユーザーはAI動画技術の強力な機能を体験できます。その技術的背景は、動画処理とAIアプリケーションにおける専門性を強調しており、価格や具体的なターゲット層の情報は明示されていませんが、高度な動画処理とAI統合ソリューションを必要とするユーザー層を主なターゲットとしていると推測されます。
映像制作
47.2K
Comfyui HunyuanVideoWrapper
ComfyUI-HunyuanVideoWrapperは、HunyuanVideoをベースとした動画処理インターフェースです。主な機能は動画のエンコードとデコードです。高度な動画処理技術を活用することで、低いハードウェア要件で動画処理が可能になり、メモリ容量の少ないデバイスでも動画処理を実行できます。本製品は、特にリソースが制限された環境で動画処理を行うユーザーに最適であり、オープンソースで無料で利用できます。
映像編集
65.1K
AI FFmpeg
AI-FFmpegは、FFmpegの強力な機能を活用したオンライン動画処理ツールです。シンプルで使いやすいインターフェースを提供し、動画ファイルの処理を容易にします。動画のエンコード、圧縮、音声抽出、トリミング、回転、基本的なエフェクト調整など、様々な機能に対応しており、動画編集や処理における強力なツールです。無料で、使いやすく、機能も充実しているため、多くの動画愛好家やプロフェッショナルのニーズを満たします。
映像編集
52.7K
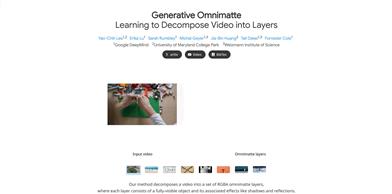
Generative Omnimatte
Generative Omnimatteは、動画を複数のRGBAレイヤーに分解する高度な動画処理技術です。各レイヤーには、可視オブジェクトとその効果(影や反射など)が含まれます。この技術は、動画編集や特殊効果制作において重要な役割を果たし、制作の柔軟性と効率性を向上させます。
映像編集
38.9K
Comfyui GIMM VFI
ComfyUI-GIMM-VFIは、GIMM-VFIアルゴリズムに基づいたフレーム補間ツールです。画像および動画処理において、高品質なフレーム補間を実現します。連続するフレーム間に新しいフレームを挿入することで、動画のフレームレートを向上させ、より滑らかな動きを実現します。ビデオゲーム、映画のポストプロダクション、高フレームレート動画が必要なその他の用途に特に有効です。Pythonで開発されており、CuPyライブラリに依存しており、高性能計算が必要なシーンに最適です。
動画編集
65.1K
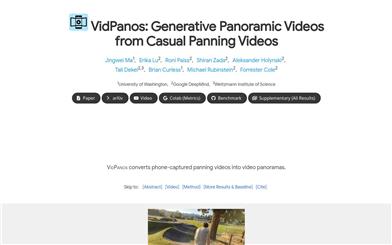
Vidpanos
VidPanosは、ユーザーが自由に撮影したパンニング動画をパノラマ動画に変換できる革新的な動画処理技術です。この技術は、空間時間外挿によって、元の動画と同じ長さのパノラマ動画を生成します。VidPanosは、生成動画モデルを利用することで、移動物体がある場合に静止画のパノラマでは捉えられない動的なシーンを解決します。人、車両、流水、静止背景など、様々な野外シーンに対応し、高い実用性と革新性を示します。
映像編集
51.1K
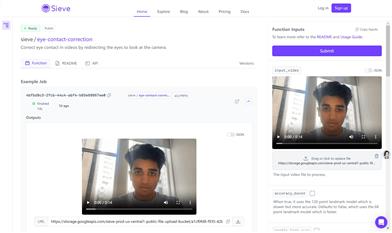
Sieve 視線修正
Sieve 視線修正APIは、開発者向けに設計された、高速で高品質な動画視線修正APIです。本技術は視線を再定向することで、人物がカメラを直接見ていなくても、カメラと視線が合っているように見せる効果を実現します。様々なカスタマイズオプションで視線再定向を微調整でき、元のまばたきや頭の動きは維持され、ランダムな「視線を外す」機能により、視線が不自然になるのを防ぎます。さらに、デバッグや分析を容易にするための分割画面表示と視覚化オプションも提供しています。本APIは、動画制作者、オンライン教育プロバイダー、動画コミュニケーションの質を高めたいユーザーを主な対象としています。価格は、動画1分あたり0.10ドルです。
AI動画編集
82.8K

動画背景除去
Video Background Removalは、innova-aiが提供するHugging Face Spaceで、動画背景除去技術に特化したツールです。深層学習モデルを用いて、動画の前景と背景を自動的に識別?分離し、ワンクリックで背景を除去します。動画制作、オンライン教育、遠隔会議など幅広い分野で活用されており、特に動画の背景を抜き出したり変更したりする必要がある場合に非常に便利です。本技術はオープンソースコミュニティHugging FaceのSpacesプラットフォーム上で開発されており、オープンソースかつ共有という理念を受け継いでいます。現在、無料トライアルを提供しており、詳細な料金については別途お問い合わせください。
AI動画編集
135.5K
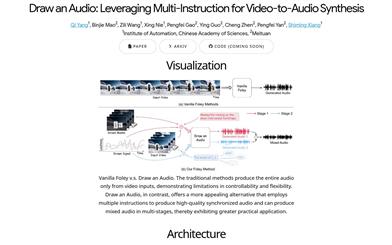
Draw An Audio
Draw an Audioは、複数命令制御によって動画の内容に基づいて高品質な同期音声を作成できる革新的な動画音声合成技術です。この技術は、音声生成の制御性と柔軟性を向上させるだけでなく、複数段階での混合音声生成も可能にし、幅広い実用的な可能性を秘めています。
AI音声編集
49.7K
Youdub Webui
YouDub-webuiは、GradioをベースとしたWebインタフェースのツールで、YouTubeなどのプラットフォームにある高品質動画の翻訳と中国語吹き替えを容易に行うことができます。AI技術、具体的には音声認識、大規模言語モデルによる翻訳、AI音声クローン技術を組み合わせることで、原動画と遜色のない中国語吹き替えを提供し、中国語圏のユーザーに優れた視聴体験を提供します。
AIビデオ翻訳
61.8K
Comfyui CogVideoXWrapper
ComfyUI-CogVideoXWrapperは、Pythonベースの動画処理モデルです。T5モデルを用いて動画コンテンツの生成と変換を行い、画像から動画への変換ワークフローをサポートしています。実験段階ではありますが、興味深い効果を示しています。主に動画コンテンツの作成や編集を行うプロフェッショナルユーザー、特に動画生成や変換に特殊なニーズを持つユーザーを対象としています。
AI動画生成
62.4K
Minicpm V 2.6
MiniCPM-V 2.6は、8億パラメーターを持つ多モーダル大規模言語モデルです。単一画像理解、複数画像理解、動画理解など、複数の分野で優れた性能を発揮します。OpenCompassを始めとする複数の一般的なベンチマークテストにおいて平均65.2点の高得点を達成し、広く使用されている商用モデルを上回っています。強力なOCR機能も備え、多言語に対応し、iPadなどの端末デバイス上でのリアルタイム動画理解も実現できる高い効率性を誇ります。
AIモデル
52.4K
Llava NeXT
LLaVA-NeXTは大規模マルチモーダルモデルであり、統一されたインターリーブデータフォーマットを通じて、多画像、動画、3D、単一画像データの処理を行います。異なるビジュアルデータモダリティにおける協調学習能力を実証しています。多画像ベンチマークテストにおいて最先端の結果を達成しており、様々なシナリオにおいて適切なデータの組み合わせにより、既存の単一タスクのパフォーマンス向上または維持を実現しています。
AIモデル
70.7K
Jockey
Jockeyは、Twelve Labs APIとLangGraphを基盤とした対話型の動画エージェントです。大規模言語モデル(LLM)の機能とTwelve LabsのAPIを組み合わせ、LangGraphを用いてタスクを割り当てることで、複雑な動画ワークフローの負荷を適切な基盤モデルに分散します。LLMは、実行手順の論理的な計画とユーザーとのインタラクションに使用され、動画関連のタスクは、動画基盤モデル(VFM)をサポートするTwelve Labs APIに渡され、字幕などの中間表現を必要とせずに、ネイティブに動画を処理します。
AI動画編集
50.0K

MOTIA
MOTIAは、テスト時適応に基づく拡散手法です。ソース動画の内在的なコンテンツと動きパターンを利用して、動画の外部拡張描画を効率的に行います。この手法は、内在適応と外部レンダリングの2つの主要な段階から構成され、動画の外部拡張描画の品質と柔軟性の向上を目指しています。
AI動画編集
117.0K
Goenhance AI
GoEnhance AIは、人工知能を用いた画像および動画拡張ツールです。動画から動画への変換、画像の鮮明化、超解像度スケーリングなどの機能を提供します。最先端の深層学習アルゴリズムを採用し、画像を究極のディテールと高解像度で拡張?アップサンプリングします。シンプルで使いやすく、強力な機能を備えているため、クリエイター、デザイナーなど、創造性を発揮したいユーザーにとって最適なツールです。
AI画像増強
585.9K

Magictool:aiライティング、youtubeツール、chatgptなど
MagicTool: AIは、AIライティング、YouTubeツール、ChatGPTなど20種類の機能を備えたAIツール集です。コンテンツクリエイター、研究者、学生、専門家など、生産性の向上を図りたいユーザーのために設計されています。無料トライアルと有料プランを提供しています。
AIツール
54.6K
Motionshop
Motionshopは、AIを活用したキャラクターアニメーションを作成できるウェブサイトです。アップロードした動画から人物を自動検出し、3Dのカートゥーンキャラクターモデルに置き換えることで、面白いAI動画を生成します。シンプルで使いやすいインターフェースと強力なAIアルゴリズムにより、ユーザーは簡単に自身の動画コンテンツを生動感あふれるアニメーション作品に変換できます。
AI動画編集
5.9M

Morphcut
本製品は、特に会話動画におけるジャンプカットを滑らかにする革新的なフレームワークを提供します。DensePoseキーポイントと顔面ランドマークを駆使した中間表現を用いて、他のソースフレームの情報を取り込みます。モーションを実現するため、カット周辺の端フレーム間でキーポイントとランドマークを補間します。その後、画像変換ネットワークを用いて、キーポイントとソースフレームからピクセルを合成します。キーポイントに誤りがある可能性があるため、各キーポイントに最適なソースを選択するためのクロスモーダルアテンション機構を提案しています。この中間表現を活用することで、強力な動画補間ベンチマークよりも優れた結果を得ることができます。私たちは、言い淀みやポーズ、さらにはランダムなカットなど、会話動画における様々なジャンプカットで本手法を実証しました。実験の結果、会話者の頭部の回転や激しい動きといった困難な状況下でも、シームレスな遷移を実現できることが示されました。
AI動画編集
180.0K
Uniref++
UniRefは、画像および動画の参照オブジェクト分割のための統一モデルです。セマンティック参照画像分割(RIS)、少サンプル分割(FSS)、セマンティック参照動画オブジェクト分割(RVOS)、動画オブジェクト分割(VOS)など、複数のタスクに対応しています。UniRefの中核となるのはUniFusionモジュールで、様々な参照情報を基盤ネットワークに効率的に注入します。UniRefはSAMなどの基盤モデルのプラグインコンポーネントとして使用できます。UniRefは、複数のベンチマークデータセットで訓練されたモデルを提供しており、コードもオープンソースとして公開しています。
AI画像生成
51.3K
中国語精選
Winkstudio
WinkStudioは、プロフェッショナルな動画美化ツールです。プロフェッショナルな動画人物画像の修正体験を提供します。WindowsとmacOSに対応し、画質修復、AIアニメ化、動画消去ペン、透かし消去、AI調色、スマートなキーイング、ノイズ除去などの機能を備えています。ユーザーは動画美容プランをカスタマイズし、人物画像を一括処理できます。また、画質修復とインテリジェントな消去機能も提供しており、商業撮影などのシーンに適しています。
映像編集
62.1K

10の累乗の生成能力
Generative Powers of Tenは、テキストから画像へのモデルを用いてマルチスケールで一貫性のあるコンテンツを生成する方法です。森の広角風景から木の枝の昆虫のクローズアップまで、シーンの極端な意味的なズームを実現できます。この表現方法により、連続的にズームする動画のレンダリングや、シーンの様々なスケールをインタラクティブに探索することが可能になります。これは、異なるスケール間の一貫性を維持しつつ、個々のサンプリングプロセスの完全性を維持する、統合されたマルチスケール拡散サンプリング手法によって実現しています。生成される各スケールは異なるテキストプロンプトによって制御されるため、従来の超解像度手法(全く異なるスケールで新しいコンテキスト構造を作成することが難しい場合があります)よりも、より深いレベルのズームを実現できます。我々は、画像の超解像度と外部描画による代替技術と比較して、この手法が、一貫性のあるマルチスケールコンテンツの生成において最も効果的であることを示しました。
AI画像生成
52.2K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.4K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.8K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.7K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.7K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M