%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
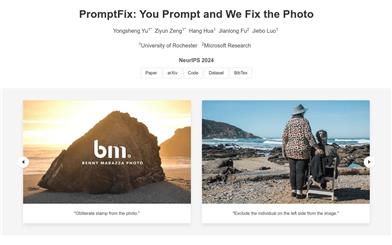
Promptfix
PromptFixは、拡散モデルが人間の指示に従って様々な画像処理タスクを実行できるようにする包括的なフレームワークです。大規模な指示従順データセットを構築し、高周波数ガイド付きサンプリング手法を提案してノイズ除去プロセスを制御し、補助プロンプトアダプターを設計して視覚言語モデルを用いてテキストプロンプトを強化することで、モデルのタスク汎化能力を高めています。PromptFixは、様々な画像処理タスクにおいて従来の方法を上回る性能を示し、ブラインドリストアおよび合成タスクにおいて優れたゼロショット能力を発揮します。
画像編集
52.2K
Mochi 1 AI
Mochi 1は、Genmoが開発した最先端のオープンソースAI動画ジェネレーターです。クリエイターは、テキストや画像のプロンプトを使用して、高品質でリアルな動画を生成できます。Mochi 1は、優れたプロンプトへの追従性と滑らかな動きで、AI動画生成を誰もが簡単に利用できるようにします。業界の他のモデルと競合することを目指し、クリエイターにより多くの制御と優れた視覚的な成果を提供します。
映像制作
55.5K

Hallo2
Hallo2は、潜在拡散生成モデルに基づく人物画像アニメーション技術です。音声駆動により、高解像度で長時間のビデオを生成します。複数の設計改良を取り入れることで、Halloの機能を拡張し、長時間のビデオ生成、4K解像度のビデオ生成、テキストプロンプトによる表情制御の強化などを実現しました。Hallo2の主な利点としては、高解像度出力、長時間における安定性、テキストプロンプトによる制御性の向上といった点が挙げられ、多様で豊かな肖像アニメーションコンテンツの生成において顕著な優位性を持ちます。
AI画像生成
64.9K
TIP Editor
TIP-Editorは、テキストと画像プロンプト、そして3Dバウンディングボックスを用いて、編集領域の外観と位置を正確に制御できる正確な3Dエディターです。既存のシーンと参照画像の表現をより適切に学習するために、段階的な2Dパーソナライゼーション戦略を採用し、ローカル編集によって正確な外観制御を実現します。TIPEditorは、背景を変えずに局所編集を行うために、明確で柔軟な3Dガウシアン?スプラッシュを3D表現として利用しています。多くの実験により、TIP-Editorはテキストと画像プロンプトに基づいて指定されたバウンディングボックス領域内で正確な編集を行い、編集品質とプロンプトとの整合性において、定性的にも定量的にもベースラインを上回ることが実証されています。
AI画像編集
58.0K

スコア蒸留サンプリング
スコア蒸留サンプリング(SDS)は、テキストプロンプトを用いた最適化問題を制御するために画像拡散モデルを利用する、最近広く普及している手法です。本論文ではSDS損失関数を詳細に分析し、その定式化における固有の問題点を特定し、驚くほど効果的な修正手法を提案しています。具体的には、損失を様々な要因に分解し、ノイズ勾配を生じる成分を分離しました。元の定式化では、ノイズを考慮するために高いテキストガイダンスを用いていましたが、これは望ましくない副作用を引き起こしていました。これに対し、我々は画像拡散モデルの時間ステップ依存的なノイズ除去不十分さを効果的に分離するために、浅層ネットワークを訓練してこれを模倣しました。最適化に基づく画像合成と編集、ゼロショット画像変換ネットワークの訓練、テキストから3Dへの合成など、複数の定性的および定量的実験を通じて、我々の新規な損失定式化の多様性と有効性を示しました。
AI画像生成
59.1K
Magicavatar
MagicAvatarは、テキスト、ビデオ、音声など様々な入力モードをモーション信号に変換することで、アバターの生成/アニメーションを行う多モーダルフレームワークです。シンプルなテキストプロンプトからアバターを作成したり、与えられたソースビデオに基づいて、指定された動きに従ったアバターを作成したりできます。さらに、特定のテーマのアバターをアニメーション化することも可能です。MagicAvatarの強みは、複数の入力モードを組み合わせることで、高品質のアバターとアニメーションを生成できる点にあります。
AI顔画像生成
61.0K
Imagetopromptai
ImageToPromptAIは、画像をテキストプロンプトに変換できるAIツールです。ユーザーは画像をアップロードして一連のテキストプロンプトを作成すると、AIが画像に基づいて適切なテキスト記述を生成します。このツールはStable Diffusionで使用し、比較可能な画像/絵画のバリエーションを作成できます。ユーザーは必要に応じて様々なプランを選択でき、サブスクリプションは不要です。
提案語
89.4K
Runway Gen 2
Gen-2は、テキスト、画像、またはビデオクリップから斬新なビデオを生成できるマルチモーダルAIシステムです。画像またはテキストプロンプトの構図とスタイルをソースビデオの構造に適用する(ビデオからビデオ)か、テキストのみを使用する(テキストからビデオ)ことで実現します。まるで新しいコンテンツを撮影したかのように見えますが、実際には何も撮影していません。Gen-2は、あらゆる画像、ビデオクリップ、またはテキストプロンプトを魅力的な映像作品に変換できる様々なモードを提供します。
AI動画生成
1.1M
Img2prompt
Img2promptは、画像からテキストプロンプトを生成するモデルです。OpenAI CLIPモデルとBLIPキャプションを使用して、与えられた画像を様々なアーティスト、メディア、スタイルと比較し、類似した画像を作成するためのテキストプロンプトを提供します。これらのテキストプロンプトはStable Diffusionなどで使用できます。
AI画像生成
83.9K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M