%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
高品質新製品
Cogview4
CogView4は、清華大学が開発した高度なテキストツーイメージ生成モデルであり、拡散モデル技術に基づいて、テキストの説明から高品質な画像を生成できます。中国語と英語の入力をサポートし、高解像度の画像を生成できます。CogView4の主な利点は、強力な多言語サポートと高品質な画像生成能力であり、高効率な画像生成を必要とするユーザーに適しています。このモデルはECCV 2024で発表され、重要な研究および応用価値を有しています。
画像生成
44.7K

Diffsplat
DiffSplatは、テキストプロンプトと単一視点画像から3Dガウシアン点群を高速に生成できる革新的な3D生成技術です。大規模に事前学習されたテキストツーイメージ拡散モデルを活用することで、効率的な3Dコンテンツ生成を実現しています。従来の3D生成手法におけるデータセットの限定性や、2D事前学習モデルの有効活用が難しいという問題を解決しつつ、3Dの一貫性を維持しています。DiffSplatの主な利点としては、高速な生成速度(1~2秒で完了)、高品質な3D出力、そして多様な入力条件への対応が挙げられます。本モデルは、特に高品質な3Dモデルの高速生成が必要な場面において、学術研究や産業用途で幅広い将来性を持っています。
3Dモデリング
49.4K
Vmix
VMixは、テキストツーイメージ拡散モデルの美的品質を向上させる技術です。革新的な条件制御手法であるValue-Mixed Cross-Attentionにより、画像の美的表現を体系的に強化します。プラグアンドプレイ型の美的アダプターとして、視覚的な概念の汎用性を維持しながら、生成画像の品質を向上させます。VMixの重要な洞察は、既存の拡散モデルの美的表現を強化しつつ、画像とテキストの整合性を維持するために、優れた条件制御手法を設計することです。VMixは十分に柔軟性があり、再トレーニングなしでより優れた視覚的性能を実現するために、コミュニティモデルにも適用できます。
画像生成
46.6K
Sana 600M 512px
SanaはNVIDIAが開発したテキストツーイメージ生成フレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性と強力なテキストと画像の整合性により、ノートパソコンのGPUでも動作し、画像生成技術の大きな進歩を示しています。このモデルは線形拡散変換器をベースとし、事前学習済みのテキストエンコーダと空間圧縮潜在特徴エンコーダを使用して、テキストプロンプトに基づいて画像の生成と変更を行います。SanaのオープンソースコードはGitHubで公開されており、芸術創作、教育ツール、モデル研究など、幅広い研究と応用が期待されます。
画像生成
61.0K
Grok Aurora
AuroraはGrokが提供する次世代の自己回帰型画像生成モデルです。数十億件のインターネットサンプルで学習されており、世界に対する深い理解能力を備えています。Auroraは写真のようなリアルなレンダリングとテキスト指示への正確な追従に優れ、マルチモーダル入力をサポートし、ユーザーが提供した画像からインスピレーションを得たり、ユーザー画像を直接編集したりできます。Auroraの新機能は、??プラットフォームの一部の国で既に利用可能となっており、1週間以内に全ユーザーへの展開を予定しています。
画像生成
38.6K
Sana 1600M 1024px
SanaはNVIDIAが開発したテキストツーイメージ生成フレームワークであり、最大4096×4096ピクセルの高解像度で、テキストと画像の一貫性が高い画像を高速に生成できます。ノートパソコンのGPUでも展開可能です。Sanaモデルは線形拡散トランスフォーマーに基づいており、事前学習済みのテキストエンコーダーと空間圧縮された潜在特徴エンコーダーを使用しています。この技術の重要性は、高品質な画像を迅速に生成できる点にあり、芸術創作、デザイン、その他の創造的な分野に革命的な影響を与えます。SanaモデルはCC BY-NC-SA 4.0ライセンスに従い、ソースコードはGitHubで公開されています。
画像生成
47.2K
MV Adapter
MV-Adapterは、アダプターベースの多視点画像生成ソリューションです。既存のネットワーク構造や特徴空間を変更することなく、事前学習済みのテキストツーイメージ(T2I)モデルとその派生モデルを強化します。更新するパラメーターを最小限に抑えることで、効率的な学習を実現し、事前学習済みモデルに埋め込まれた事前知識を保持し、過学習のリスクを低減します。複製された自己注意層と並列注意アーキテクチャなどの革新的な設計により、アダプターは事前学習済みモデルの強力な事前知識を継承し、新しい3D知識をモデル化できます。さらに、MV-Adapterは統一された条件エンコーダーを提供し、カメラパラメーターと幾何情報をシームレスに統合することで、テキストと画像ベースの3D生成やテクスチャマッピングなどのアプリケーションをサポートします。MV-AdapterはStable Diffusion XL(SDXL)上で768解像度の多視点生成を実現し、その適応性と多機能性を示しています。任意の視点生成に拡張可能であり、より広範なアプリケーションの可能性を切り開きます。
画像生成
67.6K

Sana
Sanaは、最大4096×4096ピクセルの高解像度画像を効率的に生成できるテキストツーイメージフレームワークです。高速で高解像度?高品質の画像合成を実現し、強力なテキストと画像の整合性を維持しつつ、ノートパソコンのGPUでも展開可能です。Sanaの中核設計には、深層圧縮自己符号化器、線形拡散変換器(DiT)、デコーダーのみの小型言語モデル(テキストエンコーダーとして)、そして効率的な学習とサンプリング戦略が含まれています。Sana-0.6Bは、最新の巨大拡散モデルと比較して、モデルサイズは20分の1、スループットは100倍以上高速です。さらに、Sana-0.6Bは16GBのノートパソコンGPUで展開可能で、1024×1024ピクセルの画像を1秒未満で生成できます。Sanaは、低コストのコンテンツ制作を可能にします。
画像生成
50.5K
海外精選
FLUX.1 Tools
FLUX.1 Toolsは、Black Forest Labsが提供するモデルツールキットです。テキストベースの画像生成モデルFLUX.1の制御性と操作性を向上させ、実画像と生成画像の修正と再創作を可能にします。このツールキットは4つの異なる機能を含んでおり、オープンアクセスモデルとしてFLUX.1 [dev]モデルシリーズで提供され、BFL API(FLUX.1 [pro]対応)を補完します。FLUX.1 Toolsの主な利点としては、最先端の画像修復と拡張機能、構造化ガイド、画像変換、再構成などがあり、画像編集と創作分野において重要な役割を果たします。
テキストツーイメージ
71.8K
Stable Diffusion 3.5 Medium 2.6B
Stable Diffusion 3.5 Mediumは、Stability AIが提供するAIベースの画像生成モデルです。テキストによる記述から高品質な画像を生成できます。ゲームデザイン、広告、芸術創作など、クリエイティブ産業の発展に大きく貢献する技術です。高い画像生成能力、使いやすさ、低リソース消費でユーザーに好評です。現在、Hugging Faceプラットフォームで無料トライアル版を提供しています。
画像生成
80.3K
FLUX.1 Dev LoRA One Click Creative Template
FLUX.1-dev-LoRA-One-Click-Creative-Templateは、Shakker-Labsが提供するLoRAを用いて訓練された画像生成モデルです。クリエイティブな写真生成に特化しており、ユーザーのテキストプロンプトを創造的な画像に変換します。高度なテキストツーイメージ生成技術を採用しており、高品質な画像を迅速に生成する必要があるユーザーに最適です。Hugging Faceプラットフォームをベースとしており、容易に導入?利用できます。非商業利用は無料ですが、商業利用には該当するライセンス契約に従う必要があります。
AI画像生成
67.3K
FLUX 1.net
FLUX AI画像生成器は、革新的な画像生成モデルです。テキストプロンプトに基づいて、高品質な画像を生成できます。FLUX.1の重要性は、高品質なコンテンツ作成ツールを民主化し、専門家やアマチュアに簡素化されたソリューションを提供することにあります。これにより、広範な技術知識やリソースを必要とせずに、プロレベルのビジュアルを作成できます。
画像生成
59.9K
Pony Diffusion
Pony Diffusion V6 XLは、ポニーをテーマにした高品質なアート作品を生成するために設計されたテキストツーイメージ拡散モデルです。約8万枚のポニー画像のデータセットで微調整されており、生成される画像は関連性が高く、かつ美しくなります。ユーザーフレンドリーなインターフェースを採用しており、使いやすく、CLIPによる美的ランキングにより画像品質が向上しています。Pony DiffusionはCreativeML OpenRAILライセンスの下で提供されており、ユーザーは自由にモデルを使用、再配布、修正できます。
画像生成
74.0K
Auraflow V0.3
AuraFlow v0.3は、完全にオープンソースのフローベースのテキストツーイメージ生成モデルです。以前のバージョンであるAuraFlow-v0.2と比較して、より多くの計算によるトレーニングと、美的データセットによるファインチューニングが行われ、様々なアスペクト比に対応し、最大1536ピクセルの幅と高さをサポートしています。GenEvalにおいて最先端の結果を達成しており、現在ベータテスト段階にあり、継続的に改善されています。コミュニティからのフィードバックは非常に重要です。
AI画像生成
72.6K
FLUX.1 Dev ControlNet Union Alpha
FLUX.1-dev-ControlNet-Union-alphaは、Diffusersシリーズに属するテキストツーイメージ生成モデルであり、ControlNet技術を用いて制御を行います。現在公開されているのはアルファ版であり、完全なトレーニングは完了していませんが、コードの有効性を既に示しています。このモデルは、オープンソースコミュニティの急速な成長を通じて、Fluxエコシステムの発展を促進することを目指しています。完全トレーニング済みのUnionモデルは、姿勢制御などの特定の分野では専門的なモデルに劣る可能性がありますが、トレーニングの進展に伴い、性能は向上していきます。
AI画像生成
70.9K
Flux RealismLoRA
flux-RealismLoRAは、XLabs AIチームによって公開されたFLUX.1-devモデルに基づくLoRA技術で、リアルな画像を生成するために使用されます。テキストプロンプトから画像を生成し、アニメスタイル、ファンタジー、自然映画風など、様々なスタイルに対応しています。XLabs AIは、ユーザーがモデルのトレーニングと使用を容易に行えるよう、トレーニングスクリプトと設定ファイルを提供しています。
AI画像生成
63.5K
Kolors
Kolorsは、快手Kolorsチームが開発した大規模テキストツーイメージ生成モデルです。潜在拡散モデルに基づき、数十億のテキストと画像のペアでトレーニングされています。視覚的品質、複雑な意味の正確性、そして中国語と英語のテキストレンダリングにおいて、オープンソースおよびクローズドソースのモデルを上回っています。Kolorsは中国語と英語の入力をサポートしており、特に中国語特有の内容の理解と生成において優れた性能を発揮します。
AI画像生成
83.1K
水彩イラストレーション
これは、stabilityai/stable-diffusion-xl-base-1.0をベースとしたLoRA適応ウェイトモデルであり、水彩イラスト風の画像生成を専門としています。LoRA技術により、元のモデルの特定のスタイル生成能力を強化し、ユーザーが生成画像のスタイルをより正確に制御できるようにします。
AI画像生成
52.7K

Stable Diffusion 3 無料オンライン版
Stable Diffusion 3は、Stability AIが開発した最新のテキスト生成画像モデルです。画像の忠実度、複数主体処理、テキストの一致度が大幅に向上しています。マルチモーダル拡散トランスフォーマー(MMDiT)アーキテクチャを採用し、画像とテキスト表現を別々に処理することで、API、ダウンロード、オンラインプラットフォームへのアクセスをサポートし、様々な用途に適しています。
画像生成
69.0K
海外精選
Stable Diffusion 3 Medium
Stable Diffusion 3 Mediumは、Stability AIがこれまで発表した中で最も高度なテキストツーイメージ生成モデルです。2億のパラメータを備え、優れたディテール、色彩、ライティング効果を提供し、様々なスタイルに対応しています。長文や複雑なプロンプトにも高い理解力があり、空間推論、構図要素、動き、スタイルを備えた画像を生成できます。さらに、前例のないテキスト品質を実現し、スペルミス、文字間隔、文字形成、間隔のエラーを削減しています。モデルのリソース効率が高く、標準的な一般消費者向けGPUで動作し、微調整も可能で、少量のデータセットから微妙なディテールを学習できるため、カスタマイズに最適です。
AI画像生成
227.1K
高品質新製品

Hyperdreambooth
HyperDreamBoothは、Google Researchによって開発された、テキストツーイメージモデルを高速にパーソナライズするための超ネットワークです。一枚の人物画像から小型のパーソナライズ済みウェイトを生成し、高速微調整と組み合わせることで、様々なコンテキストやスタイルにおいて、高い主題詳細度を持つ人物画像を生成できます。同時に、多様なスタイルや意味の変更に対するモデルの重要な知識も維持します。
AI画像生成
102.1K
高品質新製品
Imagen 3
Imagen 3は、Googleの高度なテキストツーイメージ生成モデルです。非常に高いディテールレベルとリアルな効果を持つ画像を生成でき、以前のモデルと比較して、視覚的なノイズが大幅に削減されています。自然言語の理解がより深くなり、プロンプトの意図をより正確に捉え、長いプロンプトからも詳細な情報を抽出できます。さらに、Imagen 3はテキストのレンダリングにも優れており、パーソナライズされた誕生日メッセージ、プレゼンテーションのスライドタイトルなど、新たな可能性を提供します。
AI画像生成
57.4K
Animagine XL 3.1
Animagine XL 3.1は、テキストプロンプトに基づいて高品質なアニメスタイルの画像を生成するテキストツーイメージ生成モデルです。Stable Diffusion XLをベースに構築されており、アニメスタイルに特化して最適化されています。より広範なアニメキャラクターに関する知識、最適化されたデータセット、新しい美的タグを備えているため、生成される画像の品質と精度が向上しています。アニメ愛好家、アーティスト、コンテンツクリエイターにとって貴重なリソースとなることを目指しています。
AI動画画像生成
242.1K

PIXART Σ
PIXART-Σは、4K解像度の画像を直接生成する拡散トランスフォーマーモデルです。前身であるPixArt-αと比較して、より高い画像忠実度とテキストプロンプトとの優れた整合性を提供します。PIXART-Σの重要な特徴には、効率的なトレーニングプロセスが含まれます。これは、より高品質なデータを使用することで、「弱い」ベースラインモデルから「より強力な」モデルへと進化させる「弱から強へのトレーニング」と呼ばれるプロセスです。PIXART-Σの改良には、より高品質なトレーニングデータの使用と効率的なトークン圧縮が含まれます。
AI画像生成
481.3K
Fable Prism
Fable Prismは、人工知能を搭載したビジュアル生成デザインツールです。自然言語による記述からイラスト、ロゴ、製品モデルなどのビジュアルイメージを生成します。色、スタイル、オブジェクトなど、生成したいビジュアルイメージを詳しく記述することで、Fable Prismは独創的で創造性に富んだ選択肢を提案します。現在はアーリーアクセス段階にあり、利用には登録が必要です。
AI設計ツール
152.1K
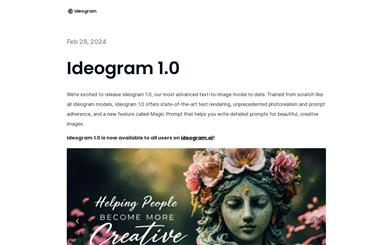
Ideogram 1.0
Ideogram 1.0は、テキストから高精細な画像を生成するテキストツーイメージ生成モデルです。最先端のテキストレンダリング機能、比類のない写真のようなリアリティとプロンプトの一致度、そして「魔法のプロンプト」と呼ばれる新機能を備えており、ユーザーは美しい創造的な画像のための詳細なプロンプトを作成することができます。Ideogram 1.0は、ideogram.aiの全ユーザー向けに公開されました!ideogram.aiで無料登録して、グローバルなクリエイターコミュニティに参加し、新しい仲間と出会い、作品やプロンプトを共有し、仲間の創造性からインスピレーションを得ましょう。毎日無料生成枠に加え、優先生成、プライベート生成、画像アップロード、Ideogramエディターへのアクセスなどの機能を提供する有料サブスクリプションプランもご用意しています。
AI画像生成
292.6K
Stable Cascade
Stable Cascadeは、Würstchenアーキテクチャに基づくテキストツーイメージ生成モデルです。他のモデルと比べて、より小さな潜在空間を用いて訓練と推論を行うため、訓練と推論速度が大幅に向上しています。このモデルは一般消費者向けハードウェアで動作するため、使用障壁が低くなっています。Stable Cascadeは、ヒューマンエバリュエーションにおいて、プロンプトの一致性と画像品質の両方で他のモデルを上回っています。総じて、効率的で使いやすく、高性能なテキストツーイメージAIモデルです。
AI画像生成
156.5K
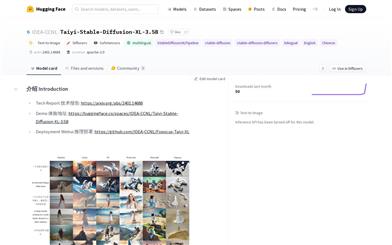
太乙扩散XL
Taiyi-Diffusion-XLは、Stable Diffusionを基に訓練されたオープンソースのバイリンガルテキストツーイメージ生成モデルです。英語と中国語のテキストによる画像生成に対応しており、以前の中国語テキストツーイメージモデルと比べて大幅な性能向上を実現しています。テキストの説明に基づいて写真のように写実的な画像を生成でき、様々な画像スタイルに対応し、高い生成品質と多様性を備えています。本モデルは革新的な訓練方法を採用し、単語表と位置符号を拡張することで長文と中国語に対応させ、大規模バイリンガルデータセットで訓練することで、強力な中国語と英語の生成能力を確保しています。
AI画像生成
117.0K
Cogview
CogViewは、汎用ドメインのテキストから画像を生成するための事前学習済みTransformerモデルです。410億個のパラメータを含み、高品質で多様な画像を生成できます。モデルの学習アプローチは抽象的なものから具体的なものへと段階的に進めるもので、まず事前学習によって汎用的な知識を獲得し、その後、特定のドメインでファインチューニングを行い画像を生成することで、生成品質を大幅に向上させています。特筆すべき点として、論文では大規模モデルの安定した学習を支援する2つの手法、PB-relaxとSandwich-LNが提案されています。
AI画像生成
61.3K
AI絵文字ジェネレーター
AI絵文字ジェネレーターは、Stable Diffusionの強力な機能を活用して、テキストをユニークな絵文字に変換します。この革新的なツールは無料で利用でき、任意のテキストを入力して簡単に個性的な絵文字を作成できます。ワンクリックで手軽に独自の絵文字を作成可能です。テクノロジーと創造性を完璧に融合し、個性的な絵文字のシームレスな生成をサポートします。デジタルコミュニケーションの強化や絵文字アートの探求など、AI絵文字ジェネレーターは創造的な表現の可能性を広げます。
画像生成
47.7K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
37.8K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M