%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Flex.1 Alpha
Flex.1-alphaは、80億パラメータの修正流変換器アーキテクチャに基づく強力なテキストから画像生成モデルです。FLUX.1-schnellの特性を受け継ぎ、訓練済み埋め込みを使用することで、CFGなしで画像を生成できます。本モデルはファインチューニングに対応し、オープンソースライセンス(Apache 2.0)のため、DiffusersやComfyUIなど様々な推論エンジンで利用可能です。主な利点として、高品質な画像を効率的に生成できること、柔軟なファインチューニング機能、そしてオープンソースコミュニティによるサポートが挙げられます。開発背景としては、画像生成モデルの圧縮と最適化、そして継続的な訓練による性能向上を目指しています。
画像生成
64.6K
高品質新製品
Silo
Siloは、複数の対話モデルを統合することで、豊かで深いコミュニケーション体験を提供することに特化したプラットフォームです。テキストによる会話だけでなく、画像生成機能も備え、視覚的なコミュニケーション方法を提供します。革新的な試みとして、従来の会話の限界を技術によって打破し、より活気があり面白いコミュニケーションを実現することを目指しています。現在、無料トライアルを提供しており、具体的な価格やポジショニングについてはまだ明確ではありません。
AI会話機械人間
53.3K
Half Illustration
half_illustrationは、Flux Dev 1モデルをベースとしたテキストから画像を生成するモデルです。写真とイラストの要素を組み合わせ、芸術的な画像を作成することができます。LoRA技術を用いており、特定のトリガーワードでスタイルの一貫性を保つことができ、芸術創作やデザイン分野に最適です。
AI画像生成
64.6K
Glyph ByT5
Glyph-ByT5は、テキストから画像を生成するモデルにおける視覚テキストのレンダリング精度を向上させるために設計された、カスタムテキストエンコーダです。文字を認識するByT5エンコーダを微調整し、厳選されたペアワイズのグリフテキストデータセットを使用して実現しました。Glyph-ByT5をSDXLと統合することで、Glyph-SDXLモデルが形成され、デザイン画像生成におけるテキストレンダリング精度は20%未満から90%近くにまで向上しました。このモデルは、段落テキストの自動的な複数行レイアウトレンダリングも可能にし、数十文字から数百文字まで、高いスペル精度を維持します。さらに、視覚テキストを含む高品質の現実画像を少量使用して微調整することで、Glyph-SDXLは、オープンワールドの現実画像におけるシーンテキストのレンダリング能力も大幅に向上しました。これらの有望な成果は、さまざまな困難なタスク向けにカスタムテキストエンコーダを設計するためのさらなる探求を促すものです。
AI画像生成
73.1K

Lavi Bridge
LaVi-Bridgeは、テキストから画像への拡散モデル用に設計された橋渡しモデルです。様々な事前学習済み言語モデルと視覚生成モデルを接続できます。LoRAとアダプターを活用することで、柔軟でプラグアンドプレイ方式を実現し、元の言語モデルと視覚モデルの重みを変更する必要はありません。様々な言語モデルと視覚生成モデルに対応しており、異なる構造にも対応可能です。このフレームワークにおいて、より高度なモジュール(より高度な言語モデルや視覚生成モデルなど)を統合することで、テキストとの整合性や画像品質などの能力を大幅に向上できることを実証しました。本モデルは広範囲な評価を経て、その有効性が確認されています。
AI画像生成
72.9K
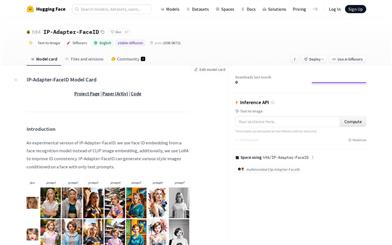
IP Adapter FaceID
これは、顔認証モデルから抽出した顔ID埋め込みを用いた、実験的な画像生成モデルです。LoRAを用いてIDの一貫性を向上させています。IP-Adapter-FaceIDは、テキストプロンプトのみで様々なスタイルの人物画像を生成できます。
AI画像生成
904.5K
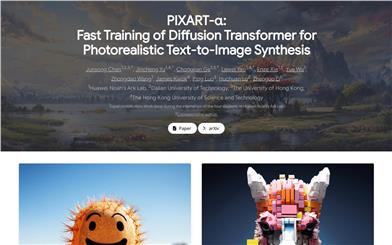
PIXART α
PIXART-αは、Transformerベースのテキストから画像生成モデルです。最先端の画像生成器と同等の画像生成品質を誇り、高解像度画像合成に対応しています。既存の大規模T2Iモデルと比較して、トレーニング速度が大幅に向上し、トレーニングコストを削減(約30万ドルの節約)、CO2排出量を90%削減することに成功しました。PIXART-αは、画像品質、芸術性、セマンティック制御において優れた性能を発揮し、AIGCコミュニティやスタートアップ企業に新たな知見を提供し、高品質で低コストな生成モデルの構築を促進します。
AI画像生成
100.2K
中国語精選
文心大模型
文心大模型は、テキスト生成、テキストから画像生成、インテリジェントな対話などの機能を備えており、文化メディア、芸術創作、教育研究、金融保険、医療健康など、幅広い用途に活用できます。本製品は、効率性、知能性、多様性に優れた設計となっており、柔軟な価格設定により、個人ユーザーと企業ユーザーの双方にご利用いただけます。
AIモデル
490.5K

Aiquickhelp
AiQuickHelpはAIアシスタントです。カスタムプロンプト、音楽再生、テキストから画像生成、画像から画像生成、コード問題解決などの機能を通じて、作業効率の向上を支援します。お客様のニーズに合わせて、パーソナライズされたプロンプトや提案を提供し、音楽でリラックスしたり、テキストのサマリーやキーワードを生成したり、画像の説明やタグを生成したり、コードの問題を解決したりできます。AiQuickHelpは様々なシーンで活用でき、より効率的な作業を支援します。
個人補助
44.2K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.5K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.4K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.4K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M