%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Blip 3o
Blip 3o は Hugging Face プラットフォームを基盤とするアプリケーションで、先進的な生成モデルを利用してテキストから画像を生成したり、既存の画像に関する分析結果や答えを提供したりします。この製品はユーザーにとって強力な画像生成と理解の能力を提供し、デザイナー、アーティスト、および開発者の間で非常に人気があります。この技術の主な利点は、その高速な画像生成速度と質の高い生成結果です。また、複数の入力形式をサポートしているため、ユーザーエクスペリエンスが向上しています。この製品は無料であり、広く一般のユーザーに公開されています。
画像生成
37.8K
Cogview4 6B
CogView4-6Bは、清華大学知識工学グループが開発したテキストから画像への生成モデルです。深層学習技術に基づいており、ユーザーが入力したテキストの説明に基づいて高品質な画像を生成できます。このモデルは複数のベンチマークテストで優れた性能を示しており、特に中国語テキストからの画像生成において顕著な利点があります。主な利点としては、高解像度画像生成、複数言語入力のサポート、効率的な推論速度などがあります。このモデルは、クリエイティブデザイン、画像生成などの分野に適しており、ユーザーがテキストの説明を視覚的なコンテンツに迅速に変換するのに役立ちます。
画像生成
48.0K
Fashion Hut Modeling LoRA
Fashion-Hut-Modeling-LoRAは、Diffusion技術に基づいたテキストから画像を生成するモデルです。主に、高品質なファッションモデルの画像生成に使用されます。特定の学習パラメータとデータセットによって、テキストプロンプトに基づき、特定のスタイルとディテールを持つファッション写真の画像を生成できます。ファッションデザイン、広告制作などの分野で重要な応用価値があり、デザイナーや広告担当者がクリエイティブなコンセプト画像を迅速に生成するのに役立ちます。現在、モデルは学習段階にあり、生成結果が不十分な場合がありますが、大きな可能性を示しています。このモデルの学習データセットは14枚の高解像度画像で構成され、AdamWオプティマイザーと一定の学習率スケジューラなどのパラメータを使用し、画像のディテールと品質に重点を置いて学習が行われました。
画像生成
75.9K
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRAは、深層学習に基づくテキストから画像を生成するモデルであり、自然言語による記述から高品質な画像を生成することを目指しています。このモデルはDiffusionアーキテクチャに基づいており、LoRA技術と組み合わせることで、効率的な微調整とスタイル化された画像生成を実現します。主な利点としては、高解像度出力、多様なスタイルのサポート、複雑なシーンに対する優れた表現力などが挙げられます。このモデルは、デザイナー、アーティスト、コンテンツクリエイターなど、高品質な画像生成を必要とするユーザーに適しており、創造的な構想の迅速な実現を支援します。
画像生成
59.3K

Neuralsvg
NeuralSVGは、テキストプロンプトからベクトルグラフィックを生成するための暗黙的神経表現手法です。ニューラル放射場(NeRFs)に着想を得ており、シーン全体を小さな多層パーセプトロン(MLP)ネットワークの重みにエンコードし、分数蒸留サンプリング(SDS)を用いて最適化します。ドロップアウトベースの正規化技術を導入することで、生成されるSVGに階層構造を促し、各形状が全体のシーンにおいて独立した意味を持つようにします。さらに、その神経表現は推論時の制御という利点も提供し、ユーザーは提供された入力に基づいて、色、縦横比など、生成されたSVGを動的に調整できます。これは、学習済みの表現のみを用いて実現されます。広範な定性的および定量的評価により、NeuralSVGは、構造化され柔軟なSVGの生成において、既存の手法を上回ることが示されています。このモデルはテルアビブ大学とMIT CSAILの研究者によって共同開発されましたが、現時点ではコードは公開されていません。
AI設計ツール
47.7K
Story Adapter
Story-Adapterは、トレーニング不要の反復型フレームワークであり、長編ストーリーの視覚化のために設計されています。反復パラダイムとグローバル参照クロスアテンションモジュールにより、画像生成プロセスを最適化し、ストーリーのセマンティックな一貫性を維持しながら、計算コストを削減します。この技術の重要性は、長編ストーリーにおいて高品質で詳細な画像を生成できる点にあり、セマンティックな一貫性と計算の実行可能性といった、従来のテキストから画像へのモデルが長編ストーリーの視覚化において抱えていた課題を解決します。
画像生成
85.6K

Dynamiccontrol
DynamicControlは、テキストから画像への拡散モデルの制御力を向上させるためのフレームワークです。多様な制御信号を動的に組み合わせることで、様々な数と種類の条件を適応的に選択し、より信頼性が高く詳細な画像合成を可能にします。このフレームワークはまず、事前学習済みの条件生成モデルと識別モデルを用いた二重ループコントローラーを使用して、すべての入力条件に対する初期の真偽スコア順序を生成します。次に、多様なモダリティを持つ大規模言語モデル(MLLM)を用いて効率的な条件評価器を構築し、条件の順序を最適化します。DynamicControlはMLLMと拡散モデルを統合的に最適化し、MLLMの推論能力を活用して多条件テキストから画像へのタスクを促進し、最終的に順位付けされた条件を入力として並列マルチコントロールアダプターに渡し、動的な視覚条件の特徴マップを学習し、それらを統合してControlNetを調整することで、生成画像の制御を強化します。
AIモデル
47.7K
Luminabrush
LuminaBrushは、画像上にライティング効果を描画するためのインタラクティブツールです。このツールは二段階の手法を採用しています。第一段階では画像を均一な照明の外観に変換し、第二段階ではユーザーの落書きに基づいて照明効果を生成します。この分解された手法により、学習プロセスが簡素化され、単一段階では考慮が必要となる外部制約(光伝達の一貫性など)を回避できます。LuminaBrushは、高品質の野外画像から抽出した均一な照明の外観を利用して、最終的なインタラクティブな照明描画モデルをトレーニングするためのペアデータを作成します。さらに、このツールは「均一照明段階」を独立して使用して、画像の「照明除去」を行うこともできます。
AI設計ツール
46.9K
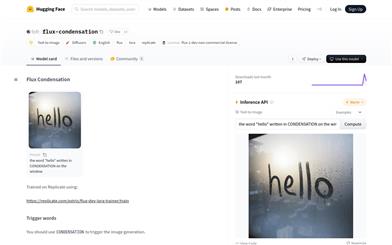
Flux Condensation
fofr/flux-condensationは、テキストから画像を生成するAIモデルです。DiffusersライブラリとLoRAs技術を用いており、ユーザーが提供したテキストプロンプトに基づいて対応する画像を生成します。Replicate上でトレーニングされており、非商業的なflux-1-devライセンスで提供されています。このモデルは、テキストから画像を生成する技術の最新の発展を示しており、デザイナー、アーティスト、コンテンツクリエイターに強力な視覚表現ツールを提供します。
画像生成
59.9K
Sana 600M 1024px
SanaはNVIDIAが開発したテキスト画像生成フレームワークであり、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性と強力なテキスト画像アライメント機能を備えており、ノートパソコンのGPUでも展開可能です。線形拡散変換器(text-to-image generative model)に基づくモデルで、1648Mパラメータを持ち、1024pxをベースとしたマルチスケールな高解像度画像生成に特化しています。主な利点としては、高解像度画像生成、高速な合成速度、そして強力なテキスト画像アライメント機能が挙げられます。Sanaモデルはオープンソースコードに基づいて開発されており、GitHubでソースコードを入手でき、CC BY-NC-SA 4.0 Licenseに従います。
画像生成
47.5K
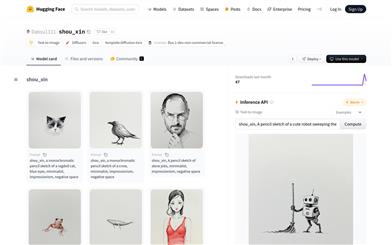
Shou Xin
shou_xinは、テキストから画像を生成するモデルです。ユーザーが提供したテキストプロンプトに基づいて、手訫スタイルの鉛筆スケッチ画像を生成できます。このモデルはdiffusersライブラリとLoRA技術を使用し、高品質の画像生成を実現しています。shou_xinモデルは、その独特の芸術的スタイルと効率的な画像生成能力により、画像生成分野で独自の地位を築いており、特定の芸術的スタイルの画像を迅速に生成する必要があるユーザーに最適です。
画像生成
76.7K
Sana 1600M 1024px 多言語対応
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。このモデルは驚異的な速度で高解像度かつ高品質な画像を合成し、強力なテキストと画像の整合性を維持しながら、ノートパソコンのGPUにも展開可能です。Sanaモデルは線形拡散トランスフォーマーに基づいており、事前学習済みのテキストエンコーダーと空間圧縮された潜在特徴エンコーダーを使用し、絵文字、中国語、英語、およびそれらを組み合わせたプロンプトにも対応しています。
画像生成
45.3K
Bylo.ai
Bylo.aiは、テキストの説明を迅速に高品質な画像に変換できる、高度なAI画像生成ツールです。ネガティブプロンプトとFlux AI画像生成ツールなどの様々なモデルに対応しており、ユーザーは自由に創作できます。Bylo.aiは、無料のオンラインアクセス、迅速かつ効率的な生成、高度なカスタマイズオプション、柔軟な画像設定、高品質な画像出力といった特長から、個人やビジネス用途の理想的な選択肢となっています。
画像生成
69.0K
Awportraitcn
AWPortraitCNは、FLUX.1-devを基に開発されたテキストから画像を生成するモデルで、中国人の容貌と美的感覚に合わせて訓練されています。室内外ポートレート、ファッション写真、スタジオ写真など、様々なタイプの肖像画を生成でき、高い汎化能力を備えています。オリジナル版と比較して、肌の質感はより繊細でリアルになっています。よりリアルな元の画像効果を求める場合は、AWPortraitSRワークフローと併用できます。
画像生成
49.7K
Sana 1600M 512px MultiLing
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。Sanaは、高速で高解像度かつ高品質の画像合成が可能であり、強力なテキストと画像の整合性も備えています。ノートパソコンのGPUでも動作します。このモデルは線形拡散変換器をベースとし、固定された事前学習済みテキストエンコーダと空間圧縮潜在特徴エンコーダを使用しており、英語、中国語、絵文字を組み合わせたプロンプトにも対応しています。Sanaの主な利点としては、高い効率性、高解像度画像生成能力、そして多言語対応が挙げられます。
画像生成
44.4K
Sana 1600M 512px
SanaはNVIDIAが開発したテキストから画像を生成するフレームワークで、最大4096×4096ピクセルの高解像度画像を効率的に生成できます。高速性、強力なテキストと画像の整合性、そしてノートパソコンのGPUでも動作するという特徴があります。線形拡散変換器をベースとし、事前学習済みのテキストエンコーダと空間圧縮された潜在的特徴エンコーダを使用しており、テキストから画像を生成する技術の最新進歩を代表しています。主な利点として、高解像度画像生成、高速合成、ノートパソコンのGPUでの展開可能性、そしてオープンソースコードが挙げられ、研究と実用アプリケーションの両方で大きな価値を持っています。
画像生成
46.4K
Text To Pose
text-to-poseは、テキスト記述から人物のポーズを生成し、そのポーズを用いて画像を生成することを目的とした研究プロジェクトです。自然言語処理とコンピュータビジョンの技術を融合し、拡散モデルの制御と品質を向上させることで、テキストから画像への生成を実現しています。NeurIPS 2024 Workshopで発表された論文に基づいており、革新的かつ最先端の技術です。主な利点としては、画像生成の精度と制御性の向上、ならびに芸術創作や仮想現実などの分野における応用可能性が挙げられます。
画像生成
47.7K
Stable Diffusion 3.5 ControlNets
Stable Diffusion 3.5 ControlNetsは、Stability AIが提供するテキストから画像を生成するAIモデルです。Cannyエッジ検出、深度マップ、高解像度アップサンプリングなど、複数の制御ネットワーク(ControlNets)に対応しています。このモデルは、テキストプロンプトに基づいて高品質な画像を生成でき、イラスト、建築レンダリング、3Dアセットテクスチャなどの用途に特に適しています。精細な画像制御機能を提供し、生成画像の品質とディテールを向上させることが重要です。製品背景情報としては、学術界での引用(arxiv:2302.05543)と、Stability Community Licenseへの準拠があります。価格については、非商業利用、年収100万ドル以下の商業利用は無料です。それ以上の場合は、企業ライセンスについてお問い合わせください。
画像生成
49.1K
FLUX.1 Dev IP アダプター
FLUX.1-dev-IPアダプターは、InstantXチームが開発したFLUX.1-devモデルに基づくIPアダプターです。このモデルは、画像処理をテキストのように柔軟に行うことができ、画像生成と編集をより効率的で直感的におこないます。画像参照に対応していますが、きめ細かいスタイル変換やキャラクターの一貫性には適していません。1000万件のオープンソースデータセットでトレーニングされ、バッチサイズは128、トレーニングステップは8万回です。画像生成分野において革新的なモデルであり、多様な画像生成ソリューションを提供しますが、スタイルや概念の網羅性が不足している可能性があります。
テキストから画像
58.8K
中国語精選
千圖網AIイラスト
千圖網AIイラストは、人工知能技術を用いて、ユーザーのテキスト説明を画像に変換するプラットフォームです。深層学習アルゴリズムにより、ユーザーの創造的なニーズを理解し、それに対応する視覚コンテンツを生成します。この技術の重要性は、アート制作のハードルを大幅に下げ、専門知識のない人でも簡単にプロレベルの画像作品を作成できる点にあります。製品背景情報によると、千圖網AIイラストはユーザーの想像力と創造性を解き放ち、シンプルで使いやすいAIクリエイティブツールを提供することを目指しています。価格については、無料トライアルを提供しており、ユーザーはAIイラストの魅力を体験できます。より高度なニーズに対応するため、有料サービスも提供しています。
画像生成
91.6K
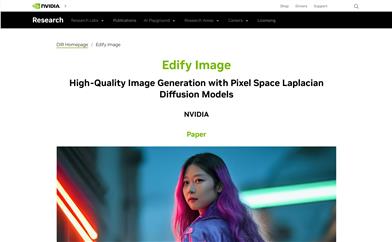
Edify Image
Edify Imageは、NVIDIAが開発した画像生成モデルです。ピクセルレベルの精度でリアルな画像コンテンツを生成できます。このモデルは、カスケード型ピクセル空間拡散モデルを採用し、新規のラプラス拡散プロセスを用いてトレーニングされています。このプロセスは、異なる周波数帯域で画像信号を異なる速度で減衰させることができます。Edify Imageは、テキストから画像の合成、4Kアップサンプリング、ControlNets、360°HDRパノラマ画像生成、画像のカスタム微調整など、幅広い用途に対応しています。画像生成技術の最新の発展を体現しており、広範な応用可能性と大きな商業的価値を秘めています。
画像生成
50.2K
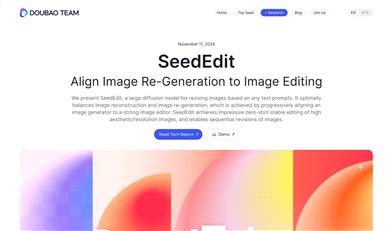
Seededit
SeedEditは、Doubao Teamが開発した大規模拡散モデルで、あらゆるテキストプロンプトに基づいて画像を修正するために使用されます。画像生成器と強力な画像エディターを段階的に連携させることで、画像の再構成と再生の最適なバランスを実現しています。SeedEditは、高審美性/高解像度の画像のゼロショット安定編集を可能にし、画像の連続修正にも対応しています。この技術の重要性は、ペア画像データの不足という画像編集における中心的な課題を解決できる点にあります。テキストから画像への生成モデル(T2I)を弱編集モデルと見なし、新しいプロンプトを含む新しい画像を生成することで「編集」を実現し、それを蒸留して画像条件付き編集モデルに合わせ込むことで実現しています。
画像編集
187.1K
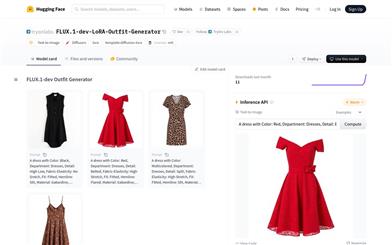
FLUX.1 Dev LoRA Outfit Generator
FLUX.1-dev LoRA Outfit Generatorは、テキストから画像を生成するAIモデルです。ユーザーが指定した色、柄、フィット感、スタイル、素材、種類などの詳細な説明に基づいて、衣服画像を生成します。H&M Fashion Captions Datasetデータセットを用いてトレーニングされており、OstrisのAI Toolkitを用いて開発されました。デザイナーがデザインアイデアを迅速に実現し、アパレル業界のイノベーションと生産プロセスを加速させる上で重要な役割を果たします。
画像生成
82.5K
Regional Prompting FLUX
Regional-Prompting-FLUXは、訓練不要の地域プロンプティング拡散変換器モデルです。訓練なしで、拡散変換器(FLUXなど)にきめ細かい組み合わせによるテキストから画像への生成能力を提供します。このモデルは、効果が顕著であるだけでなく、LoRAおよびControlNetと高度に互換性があり、高速性を維持しながらGPUメモリの使用量を削減できます。
画像生成
52.2K
Stable Diffusion 3.5 Medium
Stable Diffusion 3.5 Mediumは、Stability AIによって開発されたテキストから画像を生成するモデルです。画像品質、レイアウト、複雑なプロンプトの理解、そしてリソース効率が向上しています。このモデルは、3つの固定された事前学習済みテキストエンコーダを使用し、QK正規化によって訓練の安定性を高め、最初の12の変換層にデュアルアテンションブロックを導入しています。高解像度画像生成、一貫性、そして様々なテキストから画像へのタスクへの適応性において優れた性能を発揮します。
画像生成
59.3K
Flux.1 Lite
Flux.1 Liteは、Freepikによって公開された80億パラメーターのテキストから画像への生成モデルです。FLUX.1-devモデルから派生しており、オリジナルモデルと比較してRAM使用量が7GB削減され、実行速度が23%向上しました。精度はbfloat16を使用することでオリジナルモデルと同等に維持されています。このモデルは、特に消費電力GPUユーザーにとって、高品質なAIモデルをよりアクセスしやすくすることを目的としています。
画像生成
54.9K
Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Large Turboは、テキストから画像を生成するマルチモーダル拡散変換器(MMDiT)モデルです。敵対的拡散蒸留(ADD)技術を採用することで、画像品質、レイアウト、複雑なプロンプトの理解、リソース効率が向上し、特に推論ステップの削減に重点が置かれています。このモデルは画像生成において優れた性能を発揮し、複雑なテキストプロンプトを理解して生成できます。様々な画像生成シーンに適しています。Hugging Faceプラットフォームで公開されており、Stability Community Licenseに従い、研究、非商業利用、および年間収益が100万ドル未満の組織または個人は無料で使用できます。
画像生成
69.0K
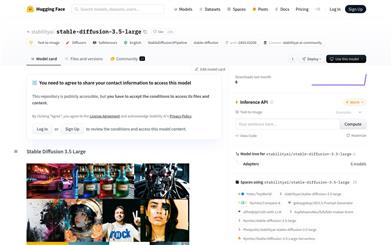
Stable Diffusion 3.5 Large
Stable Diffusion 3.5 Largeは、Stability AIが開発した、テキストから画像を生成する多様なモードを持つ拡散変換器(MMDiT)モデルです。画像品質、レイアウト、複雑なプロンプトの理解、リソース効率において大幅な改善が見られます。3つの固定された事前学習済みテキストエンコーダを使用し、QK正規化技術により訓練の安定性を向上させています。さらに、合成データとフィルタリングされた公開利用可能なデータを含むデータと戦略を用いて訓練されています。Stable Diffusion 3.5 Largeモデルは、コミュニティライセンス契約に従い、研究、非営利目的、および年間収入100万米ドル未満の組織や個人の商業利用に無料で利用できます。
画像生成
58.0K
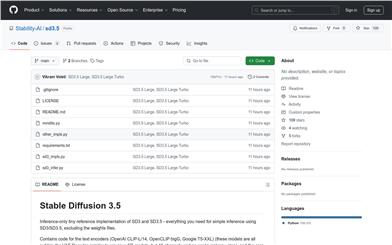
Sd3.5
Stable Diffusion 3.5は、簡素化された推論のための軽量モデルです。テキストエンコーダ、VAEデコーダ、そして中核となるMM-DiT技術を搭載しています。本モデルは、パートナー組織によるSD3.5の実装を支援することを目的としており、高品質な画像生成に使用できます。その重要な特長は、効率的な推論能力とリソースの低消費であり、幅広いユーザーが画像生成の楽しさを体験できるようになっています。本モデルはStability AI Community License Agreementに従い、無料で使用できます。
画像生成
64.3K
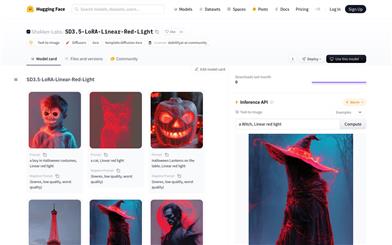
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Lightは、テキストから画像を生成するAIモデルです。LoRA(Low-Rank Adaptation)技術を用いることで、ユーザーが提供するテキストプロンプトに基づき、高品質な画像を生成できます。この技術の重要性は、計算コストを抑えつつモデルのファインチューニングを実現し、生成画像の多様性と品質を維持できる点にあります。本モデルはStable Diffusion 3.5 Largeモデルをベースに、特定の画像生成ニーズに合うよう最適化?調整されています。
画像生成
61.0K
- 1
- 2
- 3
- 4
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
37.8K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M