%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

ImgSearch
ImgSearchは、無料で高品質なAI生成画像を提供するサイトで、AI技術を利用して画像を生成し、ユーザーに迅速で便利なストック画像検索サービスを提供しています。
画像生成
37.8K

Blip 3o
Blip 3o は Hugging Face プラットフォームを基盤とするアプリケーションで、先進的な生成モデルを利用してテキストから画像を生成したり、既存の画像に関する分析結果や答えを提供したりします。この製品はユーザーにとって強力な画像生成と理解の能力を提供し、デザイナー、アーティスト、および開発者の間で非常に人気があります。この技術の主な利点は、その高速な画像生成速度と質の高い生成結果です。また、複数の入力形式をサポートしているため、ユーザーエクスペリエンスが向上しています。この製品は無料であり、広く一般のユーザーに公開されています。
画像生成
37.3K
海外精選

F Lite
F Liteは、FreepikとFalによって作成された大規模な拡散モデルで、100億パラメーターを持ちます。著作権クリアかつ安全な作業環境(SFW)に特化して訓練されました。モデルはFreepikの内部データセットに基づいており、約8000万枚の合法的な画像データを含んでいます。これは、このスケールのモデルが法的?安全なコンテンツに焦点を当てた最初の取り組みです。技術報告書にはモデルの詳細が記載されており、CreativeML Open RAIL-Mライセンスのもとで配布されています。モデルの設計はオープンでアクセスしやすいAIの促進を目指しています。
画像生成
37.0K
Cogview4 6B
CogView4-6Bは、清華大学知識工学グループが開発したテキストから画像への生成モデルです。深層学習技術に基づいており、ユーザーが入力したテキストの説明に基づいて高品質な画像を生成できます。このモデルは複数のベンチマークテストで優れた性能を示しており、特に中国語テキストからの画像生成において顕著な利点があります。主な利点としては、高解像度画像生成、複数言語入力のサポート、効率的な推論速度などがあります。このモデルは、クリエイティブデザイン、画像生成などの分野に適しており、ユーザーがテキストの説明を視覚的なコンテンツに迅速に変換するのに役立ちます。
画像生成
47.7K
高品質新製品
Cogview4
CogView4は、清華大学が開発した高度なテキストツーイメージ生成モデルであり、拡散モデル技術に基づいて、テキストの説明から高品質な画像を生成できます。中国語と英語の入力をサポートし、高解像度の画像を生成できます。CogView4の主な利点は、強力な多言語サポートと高品質な画像生成能力であり、高効率な画像生成を必要とするユーザーに適しています。このモデルはECCV 2024で発表され、重要な研究および応用価値を有しています。
画像生成
44.2K
Fakeatweet
FakeATweetは、リアルなTwitter/Xスクリーンショットを生成するオンラインツールです。高度な画像生成技術を利用して、本物のTwitter/X投稿と見分けがつかないほどリアルなスクリーンショットをすばやく生成します。主なメリットは、ウォーターマークがなく、登録不要で、完全無料であることです。悪ふざけ、ミーム作成、クリエイティブなプロジェクトなど、Twitter/Xスクリーンショットの迅速な生成が必要なユーザーに最適です。シンプルで使いやすいインターフェースで、モバイルとデスクトップの両方のプレビューに対応し、様々なユーザーのニーズを満たします。
画像生成
44.7K

Janus Pro
Janus Proは、DeepSeekテクノロジーを搭載した高度なAI画像生成と理解プラットフォームです。革新的な統一トランスフォーマーアーキテクチャを採用し、複雑なマルチモーダル操作を効率的に処理することで、画像生成と理解において卓越したパフォーマンスを実現します。9000万以上のサンプル(合成美学データポイント7200万個を含む)でトレーニングされており、生成される画像は視覚的に魅力的で、コンテキストも正確です。Janus Proは、開発者や研究者に強力なビジュアルAI機能を提供し、アイデアからビジュアルストーリーへの変換を支援します。高品質の画像生成と分析を必要とするユーザー向けに無料トライアルを提供しています。
画像生成
79.5K
ホットドッグ判定アプリ
本アプリは画像認識技術を利用し、アップロードされた画像がホットドッグかどうかを判定します。深層学習モデルに基づいており、ホットドッグ画像を迅速かつ正確に認識できます。この技術は、日常生活における画像認識の楽しい応用を示すとともに、人工知能技術の普及性とエンターテインメント性を体現しています。AI技術への楽しい探求から生まれた本アプリは、シンプルな画像認識機能を通じて、ユーザーにAIの魅力を感じてもらうことを目的としています。現在無料で利用でき、新しい技術を試してみたい方や、楽しい体験を求めるユーザーを主な対象としています。
画像生成
49.1K
高品質新製品
Google Imagen 3 API
Google Imagen 3はGoogleが提供する画像生成モデルであり、Gemini APIを通じて開発者に公開されています。ユーザーが入力したテキストプロンプトに基づいて高品質な画像を生成でき、超現実主義、印象派、抽象芸術など、様々な芸術スタイルに対応しています。画像の詳細と色彩処理において優れたパフォーマンスを発揮し、芸術創作、広告デザイン、ゲーム開発などのクリエイティブな作業に適しています。主な利点としては、効率的なプロンプト追跡能力、豊富なカスタマイズオプション、そしてコスト効率などが挙げられます。さらに、不正使用を防ぐため、生成されたすべての画像には不可視の透かしが埋め込まれています。価格は1画像あたり0.03ドルで、大量の画像生成が必要な開発者や企業に適しています。
画像生成
64.6K
1prompt1story
1Prompt1Storyは、追加の学習なしに、単一の指示プロンプトから一貫性のある画像シーケンスを生成できる革新的なテキストツーイメージ生成技術です。言語モデルの文脈的一貫性を活用し、単一の指示プロンプトで全ての記述を連結することで、同一性の一貫した画像を生成します。複数キャラクタの生成、空間制御による生成、実写画像のパーソナライズ化などをサポートし、幅広い応用が期待できます。本モデルは、効率的で一貫性のある画像生成を必要とするクリエイターや開発者を対象としており、物語創作、アニメーション制作などの分野で活用可能です。
画像生成
53.3K
Animagine XL 4.0
Animagine XL 4.0は、Stable Diffusion XL 1.0を微調整したアニメテーマの生成モデルです。840万枚もの多様なアニメ風画像を用いて、2650時間にわたるトレーニングが実施されました。このモデルは、テキストプロンプトによるアニメテーマ画像の生成と修正に特化しており、様々な特殊タグに対応し、画像生成の様々な側面を制御できます。主な利点としては、高品質な画像生成、豊富なアニメスタイルのディテール、特定のキャラクターやスタイルの正確な再現などが挙げられます。Cagliostro Research Labによって開発され、CreativeML Open RAIL++-Mライセンスを採用しているため、商用利用と改変が可能です。
画像生成
109.3K
Fashion Hut Modeling LoRA
Fashion-Hut-Modeling-LoRAは、Diffusion技術に基づいたテキストから画像を生成するモデルです。主に、高品質なファッションモデルの画像生成に使用されます。特定の学習パラメータとデータセットによって、テキストプロンプトに基づき、特定のスタイルとディテールを持つファッション写真の画像を生成できます。ファッションデザイン、広告制作などの分野で重要な応用価値があり、デザイナーや広告担当者がクリエイティブなコンセプト画像を迅速に生成するのに役立ちます。現在、モデルは学習段階にあり、生成結果が不十分な場合がありますが、大きな可能性を示しています。このモデルの学習データセットは14枚の高解像度画像で構成され、AdamWオプティマイザーと一定の学習率スケジューラなどのパラメータを使用し、画像のディテールと品質に重点を置いて学習が行われました。
画像生成
75.6K
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRAは、深層学習に基づくテキストから画像を生成するモデルであり、自然言語による記述から高品質な画像を生成することを目指しています。このモデルはDiffusionアーキテクチャに基づいており、LoRA技術と組み合わせることで、効率的な微調整とスタイル化された画像生成を実現します。主な利点としては、高解像度出力、多様なスタイルのサポート、複雑なシーンに対する優れた表現力などが挙げられます。このモデルは、デザイナー、アーティスト、コンテンツクリエイターなど、高品質な画像生成を必要とするユーザーに適しており、創造的な構想の迅速な実現を支援します。
画像生成
58.5K

Tokenverse
TokenVerseは、革新的な多概念パーソナライズ手法です。事前学習済みテキストツーイメージ拡散モデルを活用し、単一画像から複雑な視覚要素と属性を分離し、シームレスな概念組み合わせ生成を実現します。この手法は、概念の種類や広さに関する既存技術の限界を突破し、物体、アクセサリー、材質、ポーズ、照明など、多様な概念をサポートします。TokenVerseの重要性は、画像生成分野により柔軟でパーソナライズされたソリューションを提供し、様々な場面におけるユーザーの多様なニーズを満たせる点にあります。現在、TokenVerseのコードは公開されていませんが、パーソナライズされた画像生成における潜在能力は、広く注目を集めています。
画像生成
53.3K
中国語精選
秒画趣拍
秒画趣拍は、若者向けに設計されたAIポートレート写真コミュニティアプリです。高度なAI技術により、ユーザーは高画質のポートレート写真を迅速に生成し、様々なシーンでの撮影ニーズを満たすことができます。このアプリの最大の強みは、その効率的な生成能力とプライバシー保護対策であり、多様なテンプレートとシンプルで使いやすいユーザーインターフェースを提供しています。秒画趣拍は無料で提供され、ユーザーに全く新しいデジタル創作体験を提供することを目指しています。
画像生成
79.5K
Humva
Humvaは、バーチャルアバター作成に特化したツールです。豊富なテンプレートとカスタマイズオプションを提供することで、ユーザーは自分のニーズに合ったバーチャルアバターを簡単に作成できます。本製品は主に、バーチャルアバターを用いたコンテンツ制作、ソーシャルメディアでの交流、またはビジネス用途での展示を必要とするユーザーを対象としています。その技術的な強みは、多様なスタイルの選択と便利なカスタマイズ機能を提供することにあり、ユーザーは専門的なデザインスキルがなくても、高品質のバーチャルアバターを迅速に生成できます。Humvaは、シンプルで効率的、そして創造性に富んだバーチャルアバター作成プラットフォームを提供し、ユーザーがデジタル世界でより良く自己表現できるよう支援することを目指しています。
画像生成
55.2K
Flex.1 Alpha
Flex.1-alphaは、80億パラメータの修正流変換器アーキテクチャに基づく強力なテキストから画像生成モデルです。FLUX.1-schnellの特性を受け継ぎ、訓練済み埋め込みを使用することで、CFGなしで画像を生成できます。本モデルはファインチューニングに対応し、オープンソースライセンス(Apache 2.0)のため、DiffusersやComfyUIなど様々な推論エンジンで利用可能です。主な利点として、高品質な画像を効率的に生成できること、柔軟なファインチューニング機能、そしてオープンソースコミュニティによるサポートが挙げられます。開発背景としては、画像生成モデルの圧縮と最適化、そして継続的な訓練による性能向上を目指しています。
画像生成
64.6K
海外精選
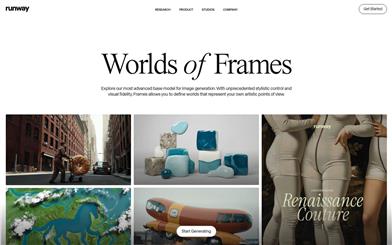
Framesの世界
FramesはRunwayの中核製品の一つであり、画像生成分野に特化しています。深層学習技術を用いて、高度にスタイル化された画像生成機能をユーザーに提供します。このモデルは、ユーザーが独自の芸術的視点で、高い視覚的忠実度を持つ画像を生成することを可能にします。主な利点としては、強力なスタイル制御機能、高品質な画像出力、そして柔軟な創作空間が挙げられます。Framesは、クリエイティブな専門家、アーティスト、デザイナーを対象としており、創造的なアイデアを迅速に実現し、創作効率を向上させることを目的としています。Runwayは様々な使用シナリオとツールサポートを提供しており、ユーザーはニーズに合わせて異なる機能モジュールを選択できます。価格については、Runwayは有料と無料トライアルのオプションを提供しており、様々なユーザーのニーズに対応しています。
画像生成
55.5K
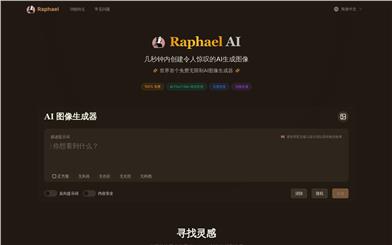
Raphael
Raphaelは、最先端のFlux.1-Devモデルをコアとした強力なAI画像生成ツールです。完全に無料で、ユーザー登録やログインなしで、高品質なAI画像を無制限に生成できます。クリエイターに強力な画像生成能力を提供するだけでなく、ゼロデータ保持ポリシーによってユーザーのプライバシーを保護します。世界最大の無料AI画像生成ツールを目指しており、アート制作、マーケティングデザイン、ゲーム開発など、画像生成が必要なあらゆるシーンで使用できます。
画像生成
95.8K
中国語精選
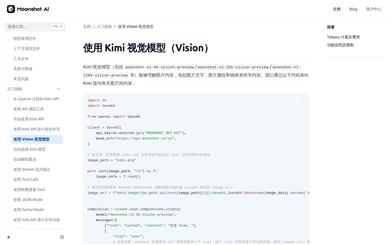
Moonshot V1 Vision Preview
Kimiビジョンモデルは、Moonshot AIオープンソースプラットフォームが提供する高度な画像理解技術です。テキスト、色、オブジェクトの形状など、画像内のコンテンツを正確に認識し理解することで、強力なビジュアル分析機能をユーザーに提供します。このモデルは効率的で正確であり、画像コンテンツの説明、ビジュアルQ&Aなど、さまざまなシナリオに適しています。価格はmoonshot-v1シリーズのモデルと同様で、モデル推論の総トークン数に基づいて課金され、画像1枚あたりのトークン消費量は固定値の1024です。
画像生成
51.3K
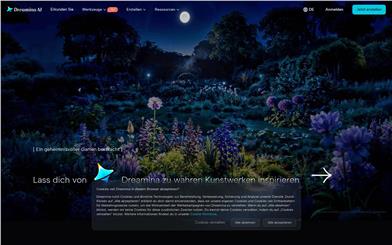
Dreamina
Dreaminaは、最先端のAI技術を用いたAI画像生成プラットフォームです。簡単なテキストプロンプトから、精緻な画像やアート作品を生成できます。強みは、高度な意味理解と創造性。ユーザーのアイデアを正確に捉え、高品質なビジュアルコンテンツを生み出します。キャラクターデザイン、ファッション?ビューティー、ゲーム素材など、あらゆるクリエイティブニーズに対応し、時間とコストを削減、制作効率を向上させます。現在、無料でご利用いただけます。ユーザーの創造性とインスピレーションを刺激することを目指しています。
画像生成
96.9K
Vmix
VMixは、テキストツーイメージ拡散モデルの美的品質を向上させる技術です。革新的な条件制御手法であるValue-Mixed Cross-Attentionにより、画像の美的表現を体系的に強化します。プラグアンドプレイ型の美的アダプターとして、視覚的な概念の汎用性を維持しながら、生成画像の品質を向上させます。VMixの重要な洞察は、既存の拡散モデルの美的表現を強化しつつ、画像とテキストの整合性を維持するために、優れた条件制御手法を設計することです。VMixは十分に柔軟性があり、再トレーニングなしでより優れた視覚的性能を実現するために、コミュニティモデルにも適用できます。
画像生成
46.6K
1.58 Bit FLUX
1.58-bit FLUXは、{-1, 0, +1}の値を用いてFLUX.1-devモデルを量子化することで、1024x1024画像の生成性能を維持しながら、高度なテキストから画像生成を実現するモデルです。本手法は画像データへのアクセスを必要とせず、FLUX.1-devモデルの自己教師学習に完全に依存しています。さらに、1.58ビット演算を最適化したカスタムカーネルを開発し、モデルサイズは7.7倍、推論メモリは5.1倍の削減、推論遅延の改善を実現しました。GenEvalとT2I Compbenchベンチマークにおける広範な評価により、1.58-bit FLUXは生成品質を維持しつつ、計算効率を大幅に向上させることが示されました。
画像生成
70.1K
Story Adapter
Story-Adapterは、トレーニング不要の反復型フレームワークであり、長編ストーリーの視覚化のために設計されています。反復パラダイムとグローバル参照クロスアテンションモジュールにより、画像生成プロセスを最適化し、ストーリーのセマンティックな一貫性を維持しながら、計算コストを削減します。この技術の重要性は、長編ストーリーにおいて高品質で詳細な画像を生成できる点にあり、セマンティックな一貫性と計算の実行可能性といった、従来のテキストから画像へのモデルが長編ストーリーの視覚化において抱えていた課題を解決します。
画像生成
85.6K
高品質新製品
Pngfree.ai
PNGFree.aiは、数百万枚もの無料PNG画像を提供するウェブサイトです。高品質の無料PNGコンバーターとAI PNGツールも提供しています。デザイナー、クリエイター、一般ユーザーにとって豊富なリソースとなり、必要な透明背景画像を迅速に見つけ、クリエイティブな作業やデザイン作業を支援します。無料、高品質、そして手軽なサービスで画像分野において確固たる地位を築いており、ユーザーは著作権を気にすることなく安心して画像を使用できます。
画像生成
55.8K
Image To Prompt AI
Image to Prompt AIは、人工知能技術を用いて画像を詳細なテキスト記述に変換するツールです。高度なAI技術により画像の内容を正確に分析し、詳細な説明と洞察を提供することで、ユーザーが視覚コンテンツをテキストに変換し、アクセシビリティとSEO(検索エンジン最適化)を向上させる支援をします。本製品は様々な画像フォーマットに対応しており、毎日20回の無料画像テキスト変換サービスを提供しています。コンテンツクリエイター、マーケティング担当者、企業オーナーに最適です。
画像生成
48.0K
AIGIF
AIGIFは、人工知能技術を活用した、パーソナライズされたGIF表情を作成できるオンラインプラットフォームです。ユーザーは自撮り写真をアップロードするだけで、様々な流行GIF、映画シーン、バズ動画などに自分の顔をシームレスに置き換えることができます。表情や動きを自然に保つ技術により、素早く、簡単に、そして楽しく、個性的な表情を作成できます。AIGIFの強みは、高度なAI顔交換技術、迅速な作成プロセス、高品質の結果出力、豊富なGIFライブラリ、そしてユーザーのプライバシー保護への配慮です。無料プランと有料プランを提供しており、ソーシャルメディアユーザー、コンテンツクリエイター、マーケティング担当者など、幅広いユーザーにご利用いただけます。
画像生成
62.7K
No More Copyright
No More Copyrightは、ユーザーが画像をアップロードして、独自の著作権問題のないバージョンに変換できるオンラインプラットフォームです。インスピレーションと創造的な探求のために設計されています。この技術の重要性は、著作権問題を解決し、ユーザーが生成された画像を自由に使用できる点にあります。プラットフォームは2024年に著作権を保有し、利用規約を提供し、チュートリアルビデオへのリンクがあります。価格については、ページには明示されていませんが、メールアドレス入力欄があり、登録またはサブスクリプションが必要であることを示唆しています。
画像生成
49.7K

Midjourneyムードボード
Midjourneyは1900万人以上のユーザーを擁する人気のAI画像生成ツールです。最近、Pinterest風の「ムードボード」機能と複数のカスタムAI画像モデルのサポートが導入され、ユーザーはMidjourney最新の画像生成AIモデルの複数カスタマイズ版を作成?切り替え、独自の美的感覚に合わせることができるようになりました。これらのアップデートは、個人やチームの創作プロセスを簡素化し、パーソナライズされたスタイルを様々なプロジェクトに容易に取り入れることを目指しています。Midjourneyのパーソナライズ化インフラは継続的に改善されており、同社は「アイデアと機能」チャンネルを通じてユーザーからのフィードバックを求め、クリエイターに直感的で強力なツールを提供することで、AI支援による創作の更なる発展を促進しています。
画像生成
50.5K
Flux Condensation
fofr/flux-condensationは、テキストから画像を生成するAIモデルです。DiffusersライブラリとLoRAs技術を用いており、ユーザーが提供したテキストプロンプトに基づいて対応する画像を生成します。Replicate上でトレーニングされており、非商業的なflux-1-devライセンスで提供されています。このモデルは、テキストから画像を生成する技術の最新の発展を示しており、デザイナー、アーティスト、コンテンツクリエイターに強力な視覚表現ツールを提供します。
画像生成
59.9K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
38.6K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.4K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
37.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
37.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
37.5K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
37.5K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M