%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Voice Cloning
A2E Free And Uncensored AI Videos
a2e.ai is an AI tool that offers functions such as AI Avatar, lip sync, voice cloning, and text-to-video. The product has advantages such as high clarity, high consistency, and efficient generation speed, and is suitable for various scenarios, providing a complete set of AI Avatar tools.
Lip Sync
37.0K
English Picks
Dia AI
Dia is a text-to-speech (TTS) model developed by Nari Labs, featuring 160 million parameters, capable of generating highly realistic conversations directly from text. The model supports emotion and intonation control and can generate non-verbal communication such as laughter and coughs. Its pre-trained model weights are hosted on Hugging Face and are suitable for English generation. This product is crucial for research and educational purposes, enabling advancements in conversational AI technology.
Text-to-Speech
38.4K

Weclone
WeClone is a project based on fine-tuning a large language model using WeChat chat logs, primarily used for high-quality voice cloning and digital avatars. It combines WeChat voice messages and a 0.5B large model, allowing users to interact with their digital avatars through a chatbot. This technology has significant application value in the fields of digital immortality and voice cloning, allowing users to continue communicating with others even when they are absent. This project is undergoing rapid iteration and is suitable for users interested in AI and language models. It is currently in the free development stage.
Speech and Language Processing
38.6K
Podcastle AI Voices
This is a powerful text-to-speech generator with over 1000 high-quality AI voices. Suitable for various use cases such as podcasts, education, and business content creation. Users can leverage this platform to generate clear, natural-sounding voice content, supporting voice cloning and audio/video editing. Reasonably priced at only $39.99 per month, it's suitable for both individuals and businesses.
Text to Speech
51.3K
Zonos TTS
Zonos TTS is an advanced AI text-to-speech technology supporting multiple languages, emotion control, and zero-shot voice cloning. It generates natural, expressive speech suitable for various scenarios, including education, audiobooks, video games, and voice assistants. The technology provides users with an efficient and personalized speech generation solution through high-quality audio output (44kHz) and fast real-time processing capabilities. While not entirely free, it offers flexible pricing plans to meet the needs of different users.
Text to Speech
76.7K
English Picks
Octave TTS
Octave TTS is a next-generation speech synthesis model developed by Hume AI. It not only converts text to speech but also understands the semantics and emotions of the text to generate expressive speech output. The core advantage of this technology lies in its deep understanding of language, allowing it to generate natural and vivid speech based on context. It is suitable for various application scenarios, including audiobooks, virtual assistants, and expressive voice interaction. The emergence of Octave TTS marks the development of speech synthesis technology from simple text reading to a more expressive and interactive direction, providing users with a more personalized and emotional voice experience. Currently, this product is primarily aimed at developers and creators, providing services through APIs and platforms. Future expansion to more languages and application scenarios is expected.
Text to Speech
83.4K
Supertone Play
Supertone Play is a platform dedicated to voice cloning and AI voice content creation. Leveraging advanced AI technology, it empowers users to create personalized voice content through simple voice inputs. This technology has wide-ranging applications in entertainment, education, business, and more, providing users with a novel means of expression and creation. The platform's voice cloning feature allows users to rapidly create unique voice models, while AI voice content creation generates high-quality voice content based on user requirements. The key advantages of this technology are its efficiency, personalization, and innovative nature, catering to diverse user needs in voice creation.
Speech Recognition
61.3K

Step Audio
Step-Audio is the first production-level open-source intelligent voice interaction framework, integrating voice understanding and generation capabilities. It supports multilingual dialogue, emotional intonation, dialects, speech rate, and prosodic style control. Its core technologies include a 130B parameter multimodal model, a generative data engine, fine-grained voice control, and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open-source models and tools, and is suitable for a variety of voice application scenarios.
Speech Recognition
71.5K
Zonos V0.1 Hybrid
Developed by Zyphra, Zonos-v0.1-hybrid is an open-source text-to-speech model capable of generating highly natural speech based on text prompts. The model is trained on extensive English voice data, employing eSpeak for text normalization and phoneme processing, and predicting DAC tokens via a transformer or hybrid backbone network. It supports multiple languages, including English, Japanese, Chinese, French, and German, and allows for fine control over speech speed, pitch, audio quality, and emotion. Additionally, it features zero-shot voice cloning, requiring only 5 to 30 seconds of speech samples to achieve high-fidelity voice replication. The model operates with a real-time factor of about 2x on an RTX 4090, offering fast performance. It is equipped with an easy-to-use gradio interface and can be easily installed and deployed using Docker. Currently, the model is available on Hugging Face for free, but users need to deploy it themselves.
Text to Speech
106.0K
Zonos V0.1
Zonos-v0.1 is a real-time text-to-speech (TTS) model developed by the Zyphra team, equipped with high-fidelity voice cloning features. This model includes a 1.6B parameter transformer model and a 1.6B parameter hybrid model, both released under the Apache 2.0 open source license. It can generate natural and expressive speech from text prompts and supports multiple languages. Additionally, Zonos-v0.1 enables high-quality voice cloning from 5 to 30-second voice clips and can be adjusted based on speaking speed, pitch, quality, and emotion. Its key advantages include high generation quality, support for real-time interaction, and flexible voice control capabilities. The release of this model aims to advance research and development in TTS technology.
Speech-to-Text
197.3K
Fresh Picks
Scam AI
Scam AI is a platform focused on detecting AI fraud. Through advanced technological methods, it can rapidly analyze and identify deepfakes, voice cloning, and other potential fraudulent information. In today’s fast-developing AI landscape, the speed and concealment of misinformation have significantly increased, making Scam AI a necessary protective tool for users. It requires no technical background, enabling users to quickly verify the authenticity of various content, helping them remain vigilant in the digital world and avoid falling victim to fraud. Currently, the platform is in beta testing, aiming to continually improve its detection algorithms and user experience.
Content Inspection
56.6K
Aigcpanel
AigcPanel is a straightforward and user-friendly one-stop AI digital persona system, supporting video synthesis, sound synthesis, and voice cloning, while simplifying local model management and one-click model integration. Leveraging the latest in artificial intelligence technology, it provides users with efficient and convenient solutions for creating digital personas, making it particularly suitable for professionals and enterprises needing to produce video and audio content. AigcPanel holds a firm position in the digital persona creation field thanks to its ease of use, efficiency, and powerful capabilities.
Digital Human
86.9K
Auralis
Auralis is a text-to-speech (TTS) engine that converts text into natural speech quickly, supports voice cloning, and boasts extremely fast processing speeds—capable of handling an entire novel in just minutes. The product is distinguished by its high speed, efficiency, easy integration, and high-quality audio output, making it suitable for scenarios requiring rapid text-to-speech conversion. Built on a Python API, Auralis supports long text streaming, built-in audio enhancement, automated language detection, and more. Developed by AstraMind AI, Auralis aims to provide a practical TTS solution for real-world applications. While product pricing is not explicitly stated on the page, the codebase is released under the Apache 2.0 License, allowing for free use in projects.
Text-to-Speech
106.3K
Outetts 0.2 500M
OuteTTS-0.2-500M is a text-to-speech synthesis model built on Qwen-2.5-0.5B. It has been trained on a larger dataset, achieving significant improvements in accuracy, naturalness, vocabulary range, voice cloning capability, and multilingual support. Special thanks to Hugging Face for the GPU funding that supported this model's training.
Speech Synthesis
104.1K
Fresh Picks
Voicv
Voicv is a cutting-edge voice cloning platform that can transform your voice into digital assets in just minutes, supporting multiple languages and zero-shot learning. The platform combines advanced AI technology with user-friendly design, offering professional-grade voice cloning capabilities. Key advantages of Voicv include zero-shot voice cloning, multi-language support, real-time processing, high accuracy, cross-platform support, and enterprise readiness. Background information shows that Voicv is dedicated to assisting content creators, voice actors, and other users in producing multilingual content while maintaining their personal brand and vocal characteristics.
AI Technology
118.4K
Maibrain
Maibrain is a platform that leverages artificial intelligence technology to allow users to store and archive memories, experiences, photos, multimedia, and texts from their loved ones. It provides voice cloning services that enable users to interact and chat with the voices of deceased relatives. The main advantage of this platform is its ability to create lasting emotional connections, helping to maintain memories of loved ones and fostering family and social ties through shared recollections. Maibrain offers trial and premium plans to cater to different user needs.
Emotional Companion
60.4K
Outetts
OuteTTS is an experimental text-to-speech model that generates speech using pure language modeling techniques. Its significance lies in harnessing advanced language modeling technology to transform text into natural-sounding speech, which is crucial for applications like speech synthesis, voice assistants, and automated dubbing. Developed by OuteAI, it supports both Hugging Face and GGUF models and offers advanced features such as voice cloning through the interface.
Text to Speech
93.0K
Cartesia Voice Changer
Voice Changer is an audio modulation model launched by Cartesia that allows users to transform audio voices while maintaining the original expression and emotion. This technology is based on Cartesia's groundbreaking work in state-space model (SSM) architecture, capable of processing and generating high-resolution sound with astonishing quality. Key advantages of Voice Changer include the preservation of natural speech, precise control over delivery, diverse usage scenarios, and integration with Sonic voice generation technology.
Speech Recognition
75.9K

Talking Avatar
Talking Avatar is an AI-powered tool that allows users to update narration by editing text, changing voices—including accents, tones, and emotions—without re-recording. It supports one-click lip-syncing for multiple speakers to ensure a natural and immersive viewing experience. Additionally, it features one-sentence voice cloning technology, enabling users to clone any voice from a simple audio sample to generate any speech. This product is a powerful resource for video creators, advertising agencies, marketers, and educators to effortlessly transform classic video clips into new trending content or optimize videos for various platforms.
AI video editing
94.1K
Fresh Picks
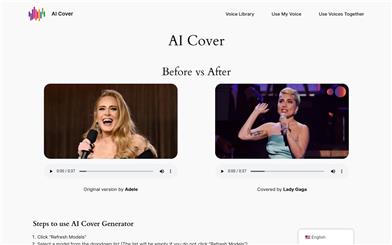
AI Cover
AI Cover is a music creation tool that leverages artificial intelligence technology, enabling users to mimic the voices of different artists and quickly generate song covers. This technology utilizes advanced algorithms to analyze and replicate an artist's vocal characteristics, allowing users to create covers that sound like they were sung by the original artist without requiring professional skills. The development of AI Cover technology offers endless possibilities for content creators and music enthusiasts, saving time, providing creative flexibility, and opening new avenues for monetization through platforms like YouTube and TikTok.
Music Production
88.0K
Fresh Picks

Your Best Accent
Your Best Accent is an innovative application that combines voice cloning technology and artificial intelligence, developed by multilingual experts Kamil and Sébastien. It helps learners acquire languages in a more natural and immersive way by mimicking their own voice, all while prioritizing data security and user privacy.
Language and Speech Recognition
60.4K
Chattts OpenVoice
ChatTTS-OpenVoice is a voice cloning model that combines ChatTTS and OpenVoice technologies. By uploading a 10-second audio clip, it can clone personalized voices and produce more natural-sounding speech. This technology is significant in the field of voice synthesis as it provides a new way to generate realistic voices suitable for various applications, including virtual assistants and audiobooks.
AI Speech Synthesis
116.5K
Linly Dubbing
Linly-Dubbing is an intelligent video dubbing and translation tool powered by AI technology. It offers high-quality multilingual video dubbing and translation services by leveraging advanced speech recognition, language model translation, voice cloning, and digital avatar technology. The product is designed to meet the demands of international education and global entertainment content localization, assisting teams in spreading quality content worldwide.
AI video dubbing
143.0K

Pandrator
Pandrator is a tool based on open-source software that converts text, PDF, EPUB, and SRT files into voice audio in multiple languages. It includes features for voice cloning, LLM-based text preprocessing, and directly saving generated audio subtitles into video files, blending them with original audio tracks. It is designed for ease of use and installation, featuring a one-click installer and a graphical user interface.
AI speech synthesis
81.4K
Metahuman Stream
metahuman-stream is an open-source project for real-time interactive digital human models, facilitating synchronized audio and video dialogues between the digital persona and users. This project supports various digital human models, including ernerf, musetalk, and wav2lip, and features capabilities like voice cloning, interruption during speech, and full-body video stitching, showcasing significant commercial application potential.
AI Digital Human
90.0K
Deepfuze
DeepFuze is an advanced deep learning tool seamlessly integrated with ComfyUI, revolutionizing facial transformation, lipsyncing, video generation, voice cloning, and lipsync translation. Leveraging cutting-edge algorithms, DeepFuze enables users to combine audio and video with unparalleled realism, ensuring perfect facial motion synchronization. This innovative solution is perfect for content creators, animators, developers, and anyone seeking to elevate their video editing projects with advanced AI-driven functionality.
AI video editing
74.0K
AI Clone Voice Free
AI Voice Cloning is a technology that utilizes machine learning to generate voices similar to a specific person's voice. No special equipment is required; high-quality cloned voices can be generated quickly in the browser. Pricing includes a free basic service and a paid premium service, offering more voice customization options.
Speech Recognition
179.7K
Dub AI
Dub AI is an AI-powered voice cloning and translation tool that helps you effortlessly add translations and voiceovers to your videos, expanding your global reach.
Language and Speech Recognition
115.9K
Applio
Applio is an open-source ecosystem that primarily offers advanced AI voice cloning technology. Its key advantages lie in its innovativeness, open-source nature, and cutting-edge AI voice cloning capabilities. Applio, as an open-source ecosystem, is dedicated to driving innovation in artificial intelligence voice cloning technology. Public pricing information is not yet available.
Development & Tools
78.7K
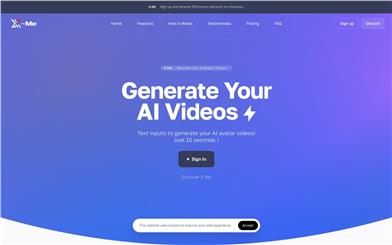
X
X Me is an AI avatar video generation tool that allows you to quickly generate personalized AI avatar videos by simply inputting text. It utilizes lightweight AI models, eliminating the need for complex training processes and enabling the rapid generation of realistic digital character videos. X Me offers a variety of AI celebrity avatar options for users to choose from and supports cloning user facial features and voices into the generated avatar videos. Users can freely create personalized AI avatar videos based on their preferences and needs.
Video Generation
96.0K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.5K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M