%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Vision-Language Model

Aya Vision 8B
CohereForAI's Aya Vision 8B is an 800-million parameter multilingual vision-language model optimized for various visual language tasks, supporting OCR, image captioning, visual reasoning, summarization, and question answering. Based on the C4AI Command R7B language model and incorporating the SigLIP2 visual encoder, it supports 23 languages and features a 16K context length. Key advantages include multilingual support, powerful visual understanding capabilities, and broad applicability. Released with open-source weights, it aims to advance the global research community. Users must adhere to C4AI's acceptable use policy under the CC-BY-NC license.
AI Model
73.4K
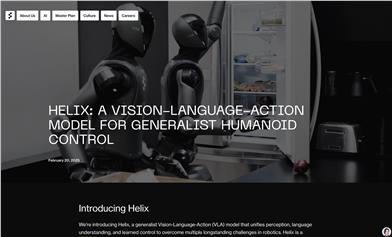
Figure AI Helix
Helix is an innovative vision-language-action model designed for general-purpose control of humanoid robots. It addresses several long-standing challenges in robotic manipulation in complex environments by combining visual perception, language understanding, and action control. Key advantages of Helix include strong generalization capabilities, efficient data utilization, and a single neural network architecture that eliminates the need for task-specific fine-tuning. The model aims to provide robots in home environments with on-the-fly behavior generation capabilities, enabling them to handle unseen objects. The emergence of Helix marks a significant step forward in robotics' ability to adapt to everyday life scenarios.
Smart Body
56.3K

Siglip2
SigLIP2 is a multilingual vision-language encoder developed by Google, featuring improved semantic understanding, localization, and dense features. It supports zero-shot image classification, enabling direct image classification via text descriptions without requiring additional training. The model excels in multilingual scenarios and is suitable for various vision-language tasks. Key advantages include efficient image-text alignment, support for multiple resolutions and dynamic resolution adjustment, and robust cross-lingual generalization capabilities. SigLIP2 offers a novel solution for multilingual visual tasks, particularly beneficial for scenarios requiring rapid deployment and multilingual support.
AI model
60.4K
Paligemma2 3b Pt 224
Developed by Google, PaliGemma 2 is a vision-language model that combines the capabilities of the SigLIP visual model and the Gemma 2 language model. It is capable of processing both image and text inputs to generate corresponding text outputs. This model excels in various vision-language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and outstanding performance across diverse tasks. PaliGemma 2 was developed to tackle complex interactions between vision and language, aiding researchers and developers in achieving breakthroughs in their respective fields.
AI Model
46.6K
Paligemma2 3b Pt 448
PaliGemma 2 is a vision-language model developed by Google, inheriting the capabilities of the Gemma 2 model, enabling it to handle image and text inputs to generate text outputs. The model excels in various visual language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and extensive applicability. This model is suitable for a wide range of applications that require processing visual and textual data, such as social media content generation and intelligent customer service.
AI Model
43.6K
Florence 2 Base Ft
Florence-2 is a high-performance visual foundation model developed by Microsoft, utilizing a prompt-based approach to handle a wide range of visual and vision-language tasks. This model can interpret simple text prompts and perform tasks such as image description, object detection, and segmentation. It is trained on the FLD-5B dataset, containing 5.4 billion annotations across 126 million images, demonstrating expertise in multi-task learning. Its sequence-to-sequence architecture allows for strong performance in both zero-shot and fine-tuning settings, proving to be a competitive visual foundation model.
AI image generation
59.1K
Pixelprose
PixelProse, created by the tomg-group-umd, is a large-scale dataset generating over 16 million detailed image descriptions using the advanced vision-language model Gemini 1.0 Pro Vision. This dataset is crucial for developing and improving image-to-text conversion technologies and can be used for tasks like image captioning and visual question answering.
AI image detection and recognition
54.9K
Fresh Picks
Paligemma
PaliGemma is an advanced vision-language model released by Google. It combines the image encoder SigLIP and the text decoder Gemma-2B to understand both images and text, achieving interactive understanding through joint training. This model is designed for specific downstream tasks such as image description, visual question answering, and segmentation, serving as a crucial tool in research and development.
AI image detection and recognition
51.3K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.6K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.9K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
45.3K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
44.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.2K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M