%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Text-to-image

Dynamiccontrol
DynamicControl is a framework designed to enhance the control of text-to-image diffusion models. It dynamically combines various control signals and supports adaptive selection of different numbers and types of conditions to synthesize images more reliably and in detail. The framework first utilizes a dual-loop controller, employing pre-trained conditional generation and discriminator models to generate initial real score rankings for all input conditions. Then, a multimodal large language model (MLLM) constructs an efficient condition evaluator to optimize the condition ordering. DynamicControl jointly optimizes MLLM and the diffusion model, leveraging the inference capabilities of MLLM to facilitate multi-condition text-to-image tasks. The final ordered conditions are input into a parallel multi-control adapter to learn dynamic visual condition feature maps and integrate them to adjust ControlNet, enhancing control over the generated images.
AI Model
47.7K
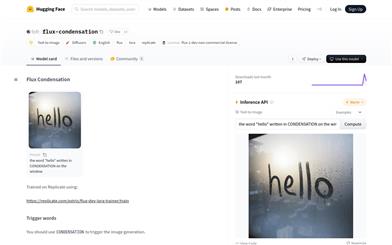
Flux Condensation
fofr/flux-condensation is an AI model that generates images based on text, utilizing the Diffusers library and LoRAs technology. It is trained on Replicate and operates under the non-commercial flux-1-dev license. This model represents the latest advancements in text-to-image generation technology, providing powerful visual tools for designers, artists, and content creators.
Image Generation
59.9K
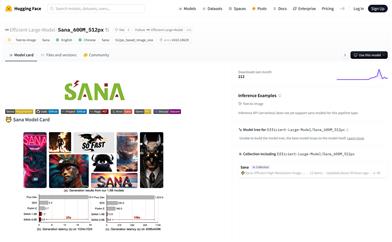
Sana 600M 512px
Sana is a text-to-image generation framework developed by NVIDIA, designed to efficiently generate images with resolutions of up to 4096×4096 pixels. Notable for its rapid performance and strong text-image alignment capabilities, Sana can be deployed on laptop GPUs, marking a significant advancement in image generation technology. The model is based on a linear diffusion transformer and utilizes a pre-trained text encoder along with a spatially compressed latent feature encoder to generate and modify images based on text prompts. The open-source code for Sana is available on GitHub, with promising research and application prospects, particularly in areas like art creation, educational tools, and model research.
Image Generation
64.6K
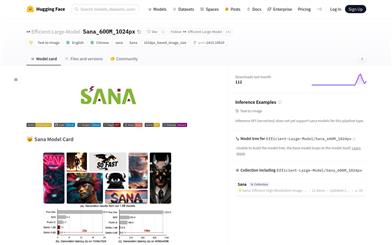
Sana 600M 1024px
Sana is a text-to-image generation framework developed by NVIDIA, capable of efficiently producing images up to 4096×4096 resolution. With its rapid processing speed and robust text-image alignment capabilities, it can even be deployed on laptop GPUs. It is based on a linear diffusion transformer (text-to-image generative model) with 1648M parameters, specifically designed for generating multi-scale images at a base resolution of 1024px. Key advantages of the Sana model include high-resolution image generation, rapid synthesis speed, and strong text-image alignment capabilities. The model's background reveals that it is developed using open-source code, available on GitHub, and adheres to specific licensing (CC BY-NC-SA 4.0 License).
Image Generation
49.7K
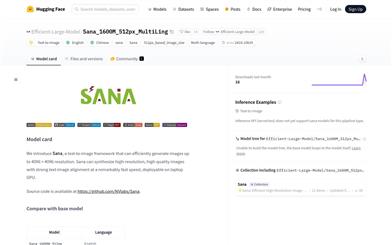
Sana 1600M 512px MultiLing
Sana is a text-to-image framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an extremely fast speed, featuring strong text-image alignment capabilities and deployable on laptop GPUs. The model is based on linear diffusion transformers, utilizing a fixed pre-trained text encoder and a space-compressed latent feature encoder, supporting mixed prompts in English, Chinese, and emojis. The key advantages of Sana include high efficiency, high-resolution image generation capability, and multilingual support.
Image Generation
43.9K
Sana 1600M 1024px
Sana is a text-to-image generation framework developed by NVIDIA that efficiently produces high-definition images with resolutions of up to 4096×4096. It maintains high text-image consistency and operates at high speed, making it deployable on laptop GPUs. The Sana model is based on linear diffusion transformers and uses pre-trained text encoders along with spatially compressed latent feature encoders. This technology is significant for its ability to rapidly generate high-quality images, having a revolutionary impact on artistic creation, design, and other creative fields. The Sana model is licensed under CC BY-NC-SA 4.0, and its source code is available on GitHub.
Image Generation
49.4K
Sana 1600M 512px
Sana is a text-to-image generation framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. Known for its speed, strong text-image alignment capabilities, and deployability on laptop GPUs, Sana is built on a linear diffusion transformer, utilizing pre-trained text encoders and spatially compressed latent feature encoders, representing the latest advancements in text-to-image generation technology. Sana's key advantages include high-resolution image generation, fast synthesis, deployability on laptop GPUs, and open-source code, providing significant value in both research and practical applications.
Image Generation
48.9K
MV Adapter
MV-Adapter is an adapter-based solution for multi-view image generation that enhances pre-trained text-to-image (T2I) models and their derivatives without altering the original network architecture or feature space. By updating fewer parameters, MV-Adapter achieves efficient training while retaining the embedded prior knowledge in the pre-trained models, thus reducing the risk of overfitting. This technology utilizes innovative designs, such as replicated self-attention layers and parallel attention architectures, allowing the adapter to inherit the powerful prior knowledge of pre-trained models for modeling new 3D knowledge. Moreover, MV-Adapter offers a unified conditional encoder that seamlessly integrates camera parameters and geometric information, supporting applications such as 3D generation based on text and images as well as texture mapping. MV-Adapter has demonstrated multi-view generation at a resolution of 768 on Stable Diffusion XL (SDXL), showcasing its adaptability and versatility for expansion into arbitrary view generation, unlocking broader application possibilities.
Image Generation
70.9K
Text To Pose
text-to-pose is a research project aimed at generating character poses from text descriptions and using these poses to create images. This technology combines natural language processing and computer vision, achieving text-to-image generation by enhancing the control and quality of diffusion models. The project is based on a paper published at the NeurIPS 2024 Workshop, showcasing innovation and cutting-edge advancements. The key advantages of this technology include improved accuracy and controllability in image generation, as well as potential applications in artistic creation and virtual reality.
Image Generation
52.4K
Flux.1 Lite
Flux.1 Lite is an 8B parameter text-to-image generation model published by Freepik, extracted from the FLUX.1-dev model. This version reduces RAM usage by 7GB compared to the original model and improves runtime speed by 23% while maintaining the same precision (bfloat16) as the original model. The release of this model aims to make high-quality AI models more accessible, especially for consumer-grade GPU users.
Image Generation
54.1K
Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Large Turbo is a multi-modal diffusion transformer (MMDiT) model for text-to-image generation, employing Adversarial Diffusion Distillation (ADD) technology to enhance image quality, layout, understanding of complex prompts, and resource efficiency, with a particular focus on reducing inference steps. This model excels in image generation, capable of understanding and generating complex text prompts, making it suitable for various image generation scenarios. It is published on the Hugging Face platform under the Stability Community License, allowing for free use by researchers, non-commercial use, and organizations or individuals with annual revenue under $1 million.
Image Generation
69.8K
FLUX.1 Dev LoRA Text Poster
FLUX.1-dev-LoRA-Text-Poster is a text-to-image generation model developed by Shakker-Labs, specifically tailored for creating artistic text posters. Utilizing LoRA technology, it generates images from text prompts, providing users with an innovative way to craft artistic works. The model was trained by copyright user cooooool and is shared on the Hugging Face platform to foster community interaction and development. The model adheres to the non-commercial use Flux-1-dev licensing agreement.
Image Generation
49.1K

Comfygen
ComfyGen is an adaptive workflow system focused on text-to-image generation that automates and tailors effective workflows by learning from user prompts. The emergence of this technology marks a shift from using a single model to incorporating multiple specialized components in complex workflows aimed at enhancing image generation quality. A key advantage of ComfyGen is its ability to automatically adjust workflows based on user text prompts, making it especially valuable for users who need to generate images in specific styles or themes.
AI image generation
61.5K
Fresh Picks
FLUX.1 Turbo Alpha
FLUX.1-Turbo-Alpha is an 8-step distilled Lora based on the FLUX.1-dev model, released by the Alimama Creative Team. This model employs a multi-head discriminator to enhance distillation quality and can be used for text-to-image (T2I), denoising control networks, and other FLUX-related models. It is recommended to set the guidance scale to 3.5 and the Lora scale to 1. The model is trained on 1M open source and internal images, using adversarial training to improve quality, with the original FLUX.1-dev transformer fixed as the backbone of the discriminator and adding multi-heads at each layer.
AI image generation
74.8K
Fresh Picks
Silo
Silo is a platform focused on multi-modal conversations that integrates various dialogue models to provide users with a rich and in-depth communication experience. The platform can handle both text dialogues and generate images, offering users a visual way to communicate. Silo represents an innovative attempt to break traditional dialogue limitations through technology, making interactions more vibrant and enjoyable. Currently, Silo offers a free trial, with specific pricing and positioning yet to be determined.
AI Conversational Agents
54.1K
SDXL Flash
SDXL Flash is a text-to-image generation model developed by the SD community in collaboration with Project Fluently. It offers faster processing speeds than LCM, Turbo, Lightning, and Hyper while maintaining high image quality. Based on the Stable Diffusion XL technology, the model achieves high efficiency and quality in image generation through optimized steps and CFG (Guidance) parameters.
AI image generation
106.3K
Instantstyle
InstantStyle is a general framework that utilizes two simple yet powerful techniques to effectively separate style and content from a reference image. Its principles involve isolating content from the image, injecting it only into the style block, and offering functionalities such as style synthesis and image generation. InstantStyle enables users to maintain style during text-to-image generation, providing a better overall experience.
AI image generation
79.2K
SPRIGHT
SPRIGHT is a large-scale visual language dataset and model focusing on spatial relationships. It constructs the SPRIGHT dataset by re-describing 6 million images, significantly increasing the spatial phrases in the descriptions. The model is fine-tuned on 444 images containing numerous objects to optimize the generation of images with spatial relationships. SPRIGHT achieves state-of-the-art spatial consistency in multiple benchmark tests while improving image quality scores.
AI image generation
70.7K
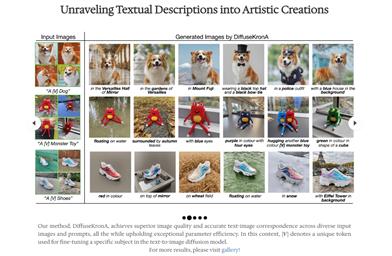
Diffusekrona
DiffuseKronA represents a parameter-efficient fine-tuning approach designed for personalized diffusion models. By introducing an adaptation module based on Kronecker multiplication, it significantly reduces the number of parameters and elevates the quality of image synthesis. This method minimizes sensitivity to hyperparameters, resulting in high-quality images under various hyperparameter conditions, making a significant advancement in the domain of text-to-image generation models.
AI Image Generation
102.4K

Opendit
OpenDiT is an open-source project providing a high-performance implementation of Diffusion Transformer (DiT) based on Colossal-AI. It is designed to enhance the training and inference efficiency of DiT applications, including text-to-video and text-to-image generation. OpenDiT achieves performance improvements through the following technologies:
* GPU acceleration up to 80% and 50% memory reduction;
* Core optimizations including FlashAttention, Fused AdaLN, and Fused layernorm;
* Mixed parallelism methods such as ZeRO, Gemini, and DDP, along with model sharding for ema models to further reduce memory costs;
* FastSeq: A novel sequence parallelism method particularly suitable for workloads like DiT, where activations are large but parameters are small. Single-node sequence parallelism can save up to 48% in communication costs and break through the memory limit of a single GPU, reducing overall training and inference time;
* Significant performance improvements can be achieved with minimal code modifications;
* Users do not need to understand the implementation details of distributed training;
* Complete text-to-image and text-to-video generation workflows;
* Researchers and engineers can easily use and adapt our workflows to real-world applications without modifying the parallelism part;
* Training on ImageNet for text-to-image generation and releasing checkpoints.
AI model training and inference
130.3K
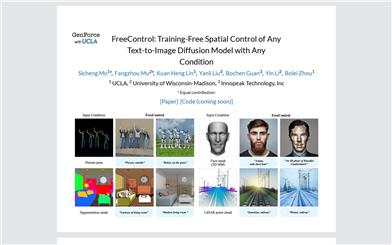
Freecontrol
FreeControl is a controllable method for text-to-image generation that can be used without any training. It supports simultaneous control over multiple conditions, architectures, and checkpoints. FreeControl aligns the structure of guided images through structural guidance and achieves visual similarity among generated images with the same seeds through visual guidance. The FreeControl system includes two stages: the analysis phase, where it queries the text-to-image model to generate a small number of seed images and constructs a linear feature subspace from the generated images, and the synthesis phase, where it applies guidance within the subspace for structural alignment of guided images and for visual alignment between images generated with and without guidance.
AI image generation
107.4K
Imggen AI
Use ImgGen's AI image generator (text-to-image) to create stunning images for free, watermark-free, and without registration. Includes features, advantages, pricing, and positioning.
Image Generation
386.7K

Bonkers
Bonkers is a free online AI image generation tool launched by Merlin AI. Users simply need to enter a few descriptive sentences, and Bonkers can generate high-quality images that meet their requirements. With a diverse range of image styles and fast generation speed, it is particularly suitable for creative professionals, designers, and others who need to quickly obtain image inspiration in their work and daily life.
AI image generation
114.5K
RPG DiffusionMaster
RPG-DiffusionMaster is a novel zero-shot text-to-image generation/editing framework that leverages the chaining reasoning ability of multi-modal LLMs to enhance the composability of text-to-image diffusion models. This framework utilizes an MLLM as the global planner, decomposing the complex image generation process into multiple simple generation tasks within subregions. Simultaneously, it proposes complementary regional diffusion to achieve compositional generation. Furthermore, the proposed RPG framework integrates text-guided image generation and editing in a closed-loop manner, augmenting its generalization capability. Extensive experiments demonstrate that RPG-DiffusionMaster outperforms state-of-the-art text-to-image diffusion models such as DALL-E 3 and SDXL in multi-category object composition and text-image semantic alignment. Notably, the RPG framework exhibits broad compatibility with diverse MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet).
AI image generation
71.2K
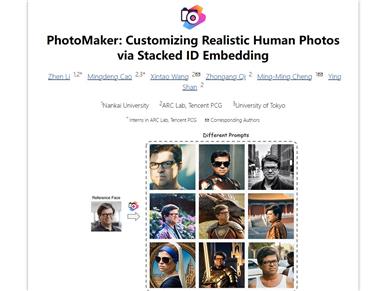
Photomaker
PhotoMaker is an efficient and personalized text-to-image generation method that primarily encodes any number of input ID images into stacked ID embeddings to preserve ID information. This embedding, as a unified ID representation, can not only comprehensively encapsulate the features of the same input ID but also accommodate the features of different IDs for subsequent integration. This paves the way for more interesting and practically valuable applications. Moreover, to drive the training of our PhotoMaker, we propose an ID-oriented data construction pipeline to assemble training data. Nurtured by the dataset constructed via the proposed pipeline, our PhotoMaker demonstrates better ID retention capability compared to methods based on test-time fine-tuning, while simultaneously providing significant speed improvement, high-quality generation results, strong generalization ability, and wide applicability.
AI image generation
2.2M
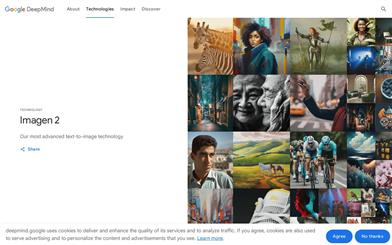
Imagen 2
Imagen 2 is our most advanced text-to-image diffusion technology, capable of generating high-quality, realistic images that closely align with user prompts. It produces more realistic images by leveraging the natural distribution of training data rather than relying on pre-programmed styles. Imagen 2's powerful text-to-image technology is available to developers and cloud customers through the Imagen API on Google Cloud Vertex AI. The Google Arts & Culture team has also deployed our Imagen 2 technology in its cultural artifact experiment, allowing users to explore, learn, and test their cultural knowledge through Google AI.
AI image generation
345.6K
Deep Floyd
Deep floyd is an open-source text-to-image model with high realism and language understanding capabilities. It consists of a frozen text encoder and three cascaded pixel diffusion modules: a base model generates 64x64 pixel images based on text prompts, and two super-resolution models generate images with gradually increasing resolutions: 256x256 pixels and 1024x1024 pixels. All stages of the model utilize a frozen T5 transformer-based text encoder to extract text embeddings, which are then input into a UNet architecture enhanced with cross-attention and attention pooling. This efficient model surpasses current state-of-the-art models, achieving a zero-shot FID score of 6.66 on the COCO dataset. Our work highlights the potential of larger UNet architectures in the first stage of cascaded diffusion models and demonstrates a promising future for text-to-image synthesis.
AI image generation
48.6K
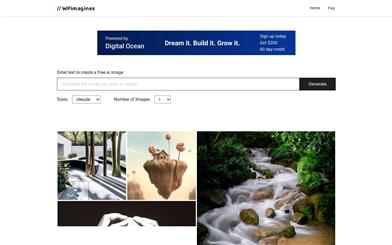
Wpimagines
WPimagines is a free and open-source AI image generation platform. Users only need to input text descriptions to generate high-quality images. The platform supports both Chinese and English, and has customizable features for generating image size and quantity. Its core competitive advantage is its complete free access, allowing usage without login. Suitable for all types of users who need to automatically generate images, including designers, writers, developers, etc.
Image Generation
68.4K
Maya Ai
Maya AI Text-to-Image Generator is an advanced text-to-image generation tool. It can transform your text into stunning works of art, helping you bring your creative visions to reality. The product offers the following advantages: 1. High-quality image generation with lifelike details; 2. Powerful creative inspiration to help you unleash your boundless creativity; 3. A user-friendly interface for easy operation; 4. Multiple pricing plans to meet the needs of different users; 5. Widely applicable in design, art, advertising and other fields. Visit our official website to learn more.
Image Generation
69.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.6K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.9K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
45.3K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
44.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.2K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M