%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Text-to-Image

Blip 3o
Blip 3o is an application built on the Hugging Face platform that uses advanced generative models to create images from text or analyze and answer questions about existing images. This product provides users with powerful image generation and understanding capabilities, making it ideal for designers, artists, and developers. The main advantages of this technology are its efficient image generation speed and high-quality outputs, as well as its support for multiple input formats, which enhances user experience. The product is free and open to all users.
Image Generation
40.3K
Cogview4 6B
CogView4-6B is a text-to-image generation model developed by the Knowledge Engineering Group at Tsinghua University. Based on deep learning technology, it can generate high-quality images based on text descriptions provided by users. This model has performed excellently in multiple benchmark tests, particularly showing significant advantages in generating images from Chinese text. Its main advantages include high-resolution image generation, support for multiple language inputs, and efficient inference speed. This model is suitable for creative design, image generation, and other fields, helping users quickly transform text descriptions into visual content.
Image Generation
60.2K
Fresh Picks
Cogview4
CogView4 is an advanced text-to-image generation model developed by Tsinghua University. Based on diffusion model technology, it can generate high-quality images based on text descriptions. It supports both Chinese and English input and can generate high-resolution images. The main advantages of CogView4 are its strong multilingual support and high-quality image generation capabilities, making it suitable for users who need to efficiently generate images. The model was presented at ECCV 2024 and has significant research and application value.
Image Generation
54.4K
Fashion Hut Modeling LoRA
Fashion-Hut-Modeling-LoRA is a diffusion-based text-to-image generation model specifically designed to create high-quality images of fashion models. The model utilizes specific training parameters and datasets to generate fashion photography images with particular styles and details based on text prompts. It holds significant application value in fashion design and advertising, enabling designers and advertisers to swiftly generate creative concept images. The model is still in the training phase, which may result in some less-than-ideal generation outcomes, but it has already demonstrated considerable potential. The training dataset includes 14 high-resolution images and employs parameters like the AdamW optimizer and a constant learning rate scheduler, with a focus on image detail and quality during training.
Image Generation
79.2K
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRA is a deep learning-based text-to-image generation model designed to generate high-quality images from natural language descriptions. Built on a Diffusion architecture and incorporating LoRA technology, it enables efficient fine-tuning and stylized image generation. Its main advantages include high-resolution output, diverse style support, and excellent performance in complex scenes. This model is intended for users who need high-quality image generation, such as designers, artists, and content creators, facilitating the rapid realization of their creative concepts.
Image Generation
63.8K
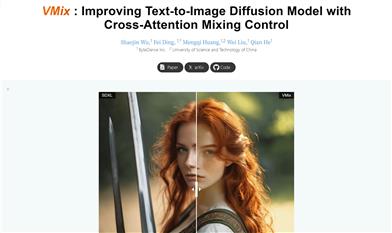
Vmix
VMix is a technology for improving the aesthetic quality of text-to-image diffusion models through an innovative conditional control method—Value-Mixing Cross-Attention—that systematically enhances the aesthetic presentation of images. As a plug-and-play aesthetic adapter, VMix enhances the quality of generated images while maintaining the generality of visual concepts. The core insight behind VMix is to design a superior conditional control method that enhances the aesthetic performances of existing diffusion models while ensuring alignment between images and text. VMix is flexible enough to be applied to community models for better visual performance without the need for retraining.
Image Generation
48.9K
Luminabrush
LuminaBrush is an interactive tool designed for drawing lighting effects on images. The tool employs a two-stage approach: the first stage converts the image to a 'uniform lighting' appearance, while the second stage generates lighting effects based on user doodles. This breakdown simplifies the learning process, avoiding the external constraints (like light transport consistency) that a single-stage approach might require. LuminaBrush constructs paired data to train the final interactive lighting sketch model by extracting 'uniform lighting' appearances from high-quality field images. Additionally, the tool can independently use the 'uniform lighting stage' to 'de-light' images, providing diverse visual effects.
AI design tools
143.5K
Sana 1600M 1024px MultiLing
Sana is a text-to-image framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at remarkable speeds while maintaining robust text-image alignment, making it deployable on laptop GPUs. The Sana model is based on linear diffusion transformers, utilizing pre-trained text encoders and spatially compressed latent feature encoders, supporting Emoji, Chinese, and English inputs, as well as mixed prompts.
Image Generation
45.8K
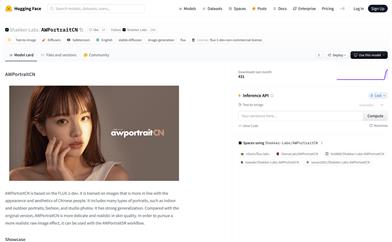
Awportraitcn
AWPortraitCN is a text-to-image generation model developed based on FLUX.1-dev, specifically trained on the appearance and aesthetics of Chinese individuals. It includes various types of portraits, such as indoor and outdoor portraits, fashion, and studio photographs, demonstrating strong generalization capabilities. Compared to the original version, AWPortraitCN offers more delicate and realistic skin textures. For an even more authentic image effect, it can be used in conjunction with the AWPortraitSR workflow.
Image Generation
52.2K
FLUX.1 Dev IP Adapter
FLUX.1-dev-IP-Adapter is an IP-Adapter developed by the InstantX Team, based on the FLUX.1-dev model. This model processes images with the same flexibility as text, making image generation and editing more efficient and intuitive. It supports image references but is not suitable for fine-grained style transfer or character consistency. The model is trained on a dataset of 10 million open-source images, using a batch size of 128 and 80,000 training steps. It offers innovative solutions in the field of image generation, although there may be limitations in style or conceptual coverage.
Text-to-Image
65.4K
English Picks
FLUX.1 Tools
FLUX.1 Tools is a suite of modeling tools developed by Black Forest Labs, aimed at increasing control and operability for the text-based image generation model FLUX.1. It enables modifications and recreations of both real and generated images. The toolkit includes four distinct features available through open access in the FLUX.1 [dev] model series and complements the BFL API, supporting FLUX.1 [pro]. Key advantages of FLUX.1 Tools include advanced capabilities for image repair and expansion, structured guidance, image transformation, and reconstruction, all of which are significant for the field of image editing and creation.
Text-to-Image
72.9K
Edify Image
Edify Image is an image generation model launched by NVIDIA that can produce realistic images with pixel-level accuracy. This model utilizes a cascaded pixel space diffusion process and is trained through a novel Laplacian diffusion method that attenuates image signals at different rates across frequency bands. Edify Image supports various applications, including text-to-image synthesis, 4K upscaling, ControlNets, 360° HDR panoramic image generation, and customized fine-tuning. It represents the latest advancements in image generation technology, offering broad applications and significant commercial value.
Image Generation
51.1K
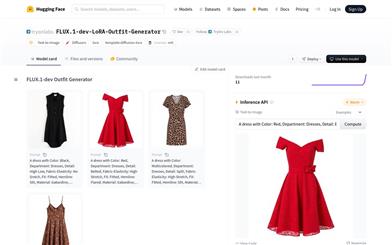
FLUX.1 Dev LoRA Outfit Generator
The FLUX.1-dev LoRA Outfit Generator is a text-to-image AI model capable of generating clothing according to detailed user descriptions involving color, pattern, fit, style, material, and type. It was trained using the H&M Fashion Captions Dataset and developed based on Ostris's AI Toolkit. Its significance lies in its ability to assist designers in quickly realizing their ideas, accelerating innovation and production processes in the fashion industry.
Image Generation
88.9K
Regional Prompting FLUX
Regional-Prompting-FLUX is a training-independent regional prompting diffusion transformer model that provides fine-grained combined text-to-image generation capabilities for diffusion transformers (such as FLUX) without the need for training. The model not only delivers impressive results but also exhibits high compatibility with LoRA and ControlNet, minimizing GPU memory usage while maintaining high speed.
Image Generation
56.3K
Stable Diffusion 3.5 Medium 2.6B
Stable Diffusion 3.5 Medium is an AI-based image generation model provided by Stability AI, capable of generating high-quality images based on text descriptions. This technology is significant for advancing the creative industries, including game design, advertising, and artistic creation. Users favor Stable Diffusion 3.5 Medium for its efficient image generation capabilities, ease of use, and low resource consumption. Currently, the model is available to users on the Hugging Face platform for free trial.
Image Generation
83.4K
Stable Diffusion 3.5 Large
Stable Diffusion 3.5 Large is a multi-modal diffusion transformer (MMDiT) model developed by Stability AI for generating images from text. The model shows significant improvements in image quality, layout, understanding complex prompts, and resource efficiency. It employs three fixed pretrained text encoders and enhances training stability through QK normalization techniques. Additionally, the model utilizes synthesized and filtered publicly available data in its training data and strategies. The Stable Diffusion 3.5 Large model is free for research, non-commercial use, and commercial use for organizations or individuals with annual revenues under $1 million, in compliance with community licensing agreements.
Image Generation
59.1K
Fresh Picks
Cogview3 Plus 3B
Developed by a team from Tsinghua University, this open-source text-to-image generation model has broad application prospects in the field of image generation, featuring high-resolution output among other advantages.
AI image generation
66.2K
English Picks
![FLUX1.1 [pro]](https://p1.chinaz.com/ai-2024-10-08-202410081033531725.jpg/392/259/W/jpg)
FLUX1.1 [pro]
FLUX1.1 [pro] is the latest image generation model released by Black Forest Labs, featuring significant enhancements in speed and image quality. This model offers six times the speed of its predecessor while improving image quality, prompt adherence, and diversity. FLUX1.1 [pro] also provides advanced customization options and superior cost-effectiveness, making it suitable for developers and businesses that require efficient, high-quality image generation.
AI image generation
88.6K
Openflux.1
OpenFLUX.1 is a fine-tuned version of the FLUX.1-schnell model that eliminates the distillation process, allowing for fine-tuning and is licensed under the open-source and permissive Apache 2.0 license. This model generates stunning images and can be completed in just 1-4 steps. It aims to remove the distillation process to create a fine-tunable open-source licensed model.
AI image generation
53.3K
Pony Diffusion
Pony Diffusion V6 XL is a text-to-image diffusion model specifically designed to create high-quality artworks themed around ponies. It has been fine-tuned on a dataset of approximately 80,000 pony images, ensuring that the generated images are both relevant and aesthetically pleasing. The model features a user-friendly interface for easy use and employs CLIP for aesthetic ranking to enhance image quality. Pony Diffusion is offered under the CreativeML OpenRAIL license, allowing users to freely use, redistribute, and modify the model.
Image Generation
101.6K
RECE
RECE is a concept erasure technology for text-to-image diffusion models that reliably and efficiently removes specific concepts by introducing regularization terms during model training. This technology is significant in enhancing the safety and controllability of image generation models, especially in scenarios where generating inappropriate content needs to be avoided. The primary advantages of RECE technology include high efficiency, high reliability, and easy integration into existing models.
AI image generation
51.6K
Flux Image Generator.net
Flux Image Generator is a text-to-image generation model developed by Black Forest Labs that utilizes advanced AI technology to create high-quality images based on textual prompts. It excels in image quality and detail compared to other models, making it particularly suitable for digital artists and content creators.
Image Generation
56.0K
Auraflow V0.3
AuraFlow v0.3 is a completely open-source flow-based text-to-image generation model. Compared to the previous version, AuraFlow-v0.2, this model has undergone more computational training and fine-tuning on aesthetic datasets. It supports a variety of aspect ratios with width and height up to 1536 pixels. The model has achieved state-of-the-art results on GenEval and is currently in beta testing, constantly improving with community feedback being crucial.
AI image generation
79.8K
Flux RealismLora
flux-RealismLora, developed by the XLabs AI team, utilizes LoRA technology based on the FLUX.1-dev model to generate realistic images. This technology generates images from text prompts and supports various styles, including animation, fantasy, and natural cinema styles. XLabs AI provides training scripts and configuration files to facilitate model training and usage.
AI image generation
64.9K
Flux Controlnet Canny
flux-controlnet-canny is a ControlNet Canny model developed by the XLabs AI team, built on the FLUX.1-dev model for text-to-image generation. This model is trained to produce high-quality images based on text prompts, widely used in creative design and visual arts.
AI image generation
69.6K
Fresh Picks
Phantasma Anime
The Phantasma Anime model is a tool focused on generating fantasy-themed anime-style illustrations through text-to-image conversion technology, providing users with anime illustrations that have specific detailed effects. This model excels in flexibility and the representation of fantasy elements, making it suitable for users who need to quickly generate anime-style images.
AI image generation
55.2K
Fresh Picks
FLUX.1 Dev
FLUX.1-dev is a refined flow transformer with 1.2 billion parameters capable of generating images from text descriptions. It represents the latest advancements in text-to-image generation technology, delivering superior output quality, second only to its professional model, FLUX.1 [pro]. The model enhances efficiency through guided distillation training and offers open weights to facilitate novel scientific research, empowering artists to develop innovative workflows. The generated outputs can be utilized for personal, scientific, and commercial purposes, as specified in the flux-1-dev-non-commercial-license.
AI image generation
65.4K
Adobe Firefly Vector AI
Adobe Firefly Vector AI is a suite of creative generative AI models introduced by Adobe, aimed at enhancing creative work through generative AI capabilities. The Firefly models and services are integrated within Adobe's creative applications such as Photoshop, Illustrator, and Lightroom. It offers features like text-to-image, generative fill, and generative expansion, allowing users unprecedented control and creativity in generating rich, realistic images and artworks. Firefly's training data includes licensed content from Adobe Stock, publicly licensed content, and works in the public domain, ensuring safe commercial use. Adobe is committed to responsibly developing generative AI and continuously improves the technology through close collaboration with the creative community, supporting and enhancing the creative process.
AI image generation
96.3K
Auraflow
AuraFlow v0.1 is a fully open-source, streaming-based text-to-image generation model that achieves state-of-the-art results on GenEval. Currently in the beta stage, the model is continuously improving with invaluable community feedback. We thank two engineers, @cloneofsimo and @isidentical, for making this project a reality and the researchers who laid the groundwork for it.
AI Image Generation
93.6K
Kolors
Kolors is a large-scale text-to-image generation model developed by the Kwai Kolors team, based on latent diffusion models and trained on billions of text-image pairs. It outperforms both open-source and closed-source models in terms of visual quality, semantic accuracy, and rendering of both Chinese and English text. Kolors supports both Chinese and English input, particularly excelling in understanding and generating content specific to Chinese.
AI Image Generation
85.0K
- 1
- 2
- 3
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M