%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Multimodal Learning
Chinese Picks
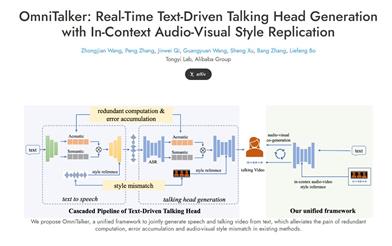
Omnitalker
OmniTalker is a unified framework proposed by Alibaba's Tongyi Lab with the aim of generating audio and video in real time to enhance human-computer interaction experiences. Its innovation lies in solving common issues in traditional text-to-speech and speech-driven video generation methods, such as out-of-sync audio-video, inconsistent styles, and system complexity. OmniTalker adopts a dual-branch diffusion transformer architecture, achieving high-fidelity audio-video outputs while maintaining efficiency. Its real-time inference speed reaches 25 frames per second, making it suitable for various interactive video chat applications and enhancing user experiences.
Video Generation
39.2K
Deepseek VL2 Small
DeepSeek-VL2 is a series of advanced large-scale mixture of experts (MoE) visual language models, significantly improved compared to its predecessor DeepSeek-VL. This model series demonstrates exceptional capabilities across various tasks, including visual question answering, optical character recognition, document/table/chart understanding, and visual localization. Comprising three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, with 1 billion, 2.8 billion, and 4.5 billion active parameters respectively, DeepSeek-VL2 achieves competitive or state-of-the-art performance against existing dense and MoE-based open-source models, even with a similar or fewer number of active parameters.
AI Model
54.9K

Mmaudio
MMAudio is a multimodal joint training technology aimed at high-quality video-to-audio synthesis. This technology can generate synchronized audio from video and text inputs, suitable for various applications such as film production and game development. Its significance lies in improving the efficiency and quality of audio generation, making it ideal for creators and developers in need of audio synthesis.
Video Production
63.2K

Internvit 300M 448px V2 5
InternViT-300M-448px-V2_5 is an enhanced version of InternViT-300M-448px, utilizing incremental learning with ViT and NTP loss (Stage 1.5) to enhance the visual encoder's capability to extract visual features. It is particularly effective in underrepresented domains in large-scale network datasets, such as multilingual OCR data and mathematical graphs. This model is part of the InternViT 2.5 series and retains the same 'ViT-MLP-LLM' architecture as its predecessors while integrating incrementally pre-trained InternViT with various pre-trained LLMs, such as InternLM 2.5 and Qwen 2.5, using randomly initialized MLP projectors.
AI Model
55.5K
Florence VL
Florence-VL is a visual language model that enhances the processing capabilities of visual and language information by introducing generative visual encoders and deep breadth fusion technology. The significance of this technology lies in its ability to improve machines' understanding of images and text, achieving better performance in multimodal tasks. Florence-VL is developed based on the LLaVA project, providing code for pre-training and fine-tuning, model checkpoints, and demonstrations.
AI Model
48.9K
Llava O1
LLaVA-o1 is a visual language model developed by the Yuan Group at Peking University, capable of spontaneous and systematic reasoning, similar to GPT-01. This model has outperformed others in six challenging multimodal benchmarks, including Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct. LLaVA-o1 demonstrates its unique advantages in visual language modeling by solving problems through step-by-step reasoning.
Step-by-Step Reasoning
48.6K
Ppllava
PPLLaVA is an efficient large-scale video language model that combines fine-grained visual prompt alignment, a convolutional-style pooling mechanism for visual token compression based on user instructions, and CLIP context extension. This model has achieved new state-of-the-art results on datasets such as VideoMME, MVBench, VideoChatGPT Bench, and VideoQA Bench, using only 1024 visual tokens, achieving an 8-fold improvement in throughput.
Video Production
45.0K
Agent S
Agent S is an open agent framework designed for autonomous interaction with computers through a graphical user interface (GUI). It transforms human-computer interaction by automating complex, multi-step tasks. The framework introduces an experience-enhanced hierarchical planning approach that leverages online network knowledge and narrative memory, extracting high-level experiences from past interactions to decompose complex tasks into manageable subtasks and provide step-by-step guidance using situational memory. Agent S continuously optimizes its actions and learns from experience, achieving adaptive and effective task planning. In the OSWorld benchmark, Agent S outperformed the baseline with a success rate increase of 9.37% (an 83.6% relative improvement), demonstrating extensive versatility in the WindowsAgentArena benchmark.
Smart Body
49.4K

Fakeshield
FakeShield is a multimodal framework designed to address two primary challenges in the field of Image Forensics Detection and Localization (IFDL): the black-box nature of detection mechanisms and the limited generalization across different tampering methods. By leveraging GPT-4o to enhance existing IFDL datasets, FakeShield has created a Multimodal Tampering Description Dataset (MMTD-Set) to train its tampering analysis capabilities. The framework includes domain label-guided interpretable detection modules (DTE-FDM) and localization modules (MFLM) that can interpret various types of tampering detection and guide localization through detailed textual descriptions. FakeShield outperforms other methods in detection accuracy and F1 scores, providing a superior and interpretable solution.
Image Editing
46.9K
Llava Video
LLaVA-Video is a large multimodal model (LMM) focused on video instruction tuning, addressing the challenge of acquiring high-quality raw data from the internet by creating a high-quality synthetic dataset, LLaVA-Video-178K. This dataset includes detailed video descriptions, open-ended questions, and multiple-choice questions, aimed at enhancing the understanding and reasoning capabilities of video language models. The LLaVA-Video model has demonstrated outstanding performance across various video benchmarks, validating the effectiveness of its dataset.
AI Model
55.5K

NVLM 1.0
NVLM 1.0 is a series of advanced multimodal large language models (LLMs) that have achieved state-of-the-art results on visual-language tasks, comparable to leading proprietary and open-access models. Notably, NVLM 1.0 surpasses its LLM backbone model in text performance following multimodal training. We have made the model weights and code open-source for the community.
AI Model
50.5K
Longllava
LongLLaVA is a multimodal large language model that extends efficiently to 1,000 images through a hybrid architecture, aimed at enhancing image processing and understanding capabilities. The model achieves effective learning and inference on large-scale image data through innovative architecture design, making it significant for fields like image recognition, classification, and analysis.
AI Model
50.0K

EAGLE
EAGLE is a series of high-resolution, vision-centric multimodal large language models (LLMs) designed to enhance the perception capabilities of multimodal LLMs through a combination of visual encoders and varied input resolutions. The model features a 'CLIP+X' fusion based on channel connections, suitable for visual experts trained on different architectures (ViT/ConvNets) and domains (detection/segmentation/OCR/SSL). The EAGLE model family supports input resolutions over 1K and excels in multimodal LLM benchmarks, particularly in resolution-sensitive tasks such as optical character recognition and document understanding.
AI Model
59.6K
Slowfast LLaVA
SlowFast-LLaVA is a zero-training multimodal large language model designed for video understanding and reasoning. It achieves performance comparable to or even better than state-of-the-art video large language models across various video question-answering tasks and benchmarks, without the need for fine-tuning on any data.
AI Model
51.9K
Llama3 S V0.2
Llama3-s v0.2 is a multimodal checkpoint developed by Homebrew Computer Company, focusing on improving speech comprehension capabilities. This model enhances its performance through early integration of semantic tagging and community feedback to streamline its structure, improve compression efficiency, and ensure consistent feature extraction from speech. Llama3-s v0.2 demonstrates stable performance across multiple speech understanding benchmarks and offers a live demo for users to experience its functionalities firsthand. Although the model is still in early development and has certain limitations—such as sensitivity to audio compression and a maximum handling time of 10 seconds for audio—the team intends to address these issues in future updates.
Speech Recognition
52.2K
Llama3 S
llama3-s is an open and ongoing research experiment aiming to extend large language models (LLMs) based on text to have native 'hearing' abilities. The project draws inspiration from Meta's Chameleon paper, focusing on token passability by incorporating audio tokens into the LLM vocabulary, potentially expanding to various input types in the future. As an open-source scientific experiment, both the codebase and datasets are publicly available.
AI Model
46.9K
MAVIS
MAVIS is a mathematical visual instruction tuning model designed for multimodal large language models (MLLMs). It enhances MLLMs' capabilities in visual mathematical problem-solving by improving visual encoding of mathematical graphs, graph-language alignment, and mathematical reasoning skills. The model includes two newly curated datasets, a mathematical visual encoder, and a mathematical MLLM, achieving leading performance in the MathVerse benchmark test through a three-phase training paradigm.
AI Model
51.6K
Longva
LongVA is a long context transformer model capable of processing over 2000 frames or 200K visual tokens. It achieves leading performance in Video-MME among 7B models. The model is tested on CUDA 11.8 and A100-SXM-80G and can be quickly deployed and used through the Hugging Face platform.
AI Model
48.9K
MG LLaVA
MG-LLaVA is a machine learning language model (MLLM) designed to enhance the visual processing capabilities of models. It achieves this by incorporating a multi-granularity visual pipeline, encompassing low-resolution, high-resolution, and object-centric features. An additional high-resolution visual encoder is introduced to capture finer details, and a Conv-Gate fusion network is used to integrate these high-resolution features with the base visual features. Furthermore, object-level features derived from offline detector bounding boxes are integrated to further refine the model's object recognition abilities. Trained via instruction tuning on publicly available multimodal data, MG-LLaVA exhibits exceptional perceptual skills.
AI Model
44.7K

Stable Diffusion 3 Free Online
Stable Diffusion 3, developed by Stability AI, is the latest text-to-image generation model with significantly improved image fidelity, multi-subject handling, and text alignment capabilities. Utilizing the Multimodal Diffusion Transformer (MMDiT) architecture, it provides separate image and language representations, supporting API, download, and online platform access for diverse application scenarios.
Image Generation
71.8K
Emo Visual Data
emo-visual-data is a publicly available emoji visual annotation dataset. It collects 5329 emojis through visual annotation completed using the glm-4v and step-free-api projects. This dataset can be used to train and test multimodal large models and is crucial for understanding the relationship between image content and textual descriptions.
AI image detection and recognition
52.4K

Cumo
CuMo is an extension architecture for multimodal large language models (LLMs). It enhances model scalability by incorporating sparse Top-K gated expert-mixing (MoE) blocks within both the visual encoder and MLP connector, while adding virtually no activation parameters during inference. CuMo pre-trains MLP blocks and initializes experts within the MoE blocks, utilizing auxiliary loss during the visual instruction fine-tuning stage to ensure balanced expert loading. CuMo outperforms other similar models on various VQA and visual instruction following benchmarks, trained entirely on open-source datasets.
AI Model
50.2K
Bunny
Bunny is a series of lightweight yet powerful multimodal models, providing various plug-and-play view encoders and language backbone networks. By selecting from a broader and more carefully curated dataset, we have constructed richer training data to compensate for the reduced model size. The Bunny-v1.0-3B model outperforms similar-sized and even larger MLLMs (7B) in performance and matches the levels of a 13B model.
AI Model
53.8K
Fresh Picks
Llava Llama 3 8b V1 1
llava-llama-3-8b-v1_1 is an optimized LLaVA model by XTuner, based on meta-llama/Meta-Llama-3-8B-Instruct and CLIP-ViT-Large-patch14-336. It has been fine-tuned with ShareGPT4V-PT and InternVL-SFT. Designed for the combination of image and text processing, the model features strong multimodal learning capabilities and is suitable for various downstream deployment and evaluation toolkits.
AI Model
67.9K
Mygo
MyGO is a tool for multimodal knowledge graph completion. It processes discrete modal information as fine-grained labels to enhance completion accuracy. MyGO utilizes the transformers library to embed text labels and trains and evaluates on multimodal datasets. It supports custom datasets and provides training scripts for replicating experimental results.
AI Data Mining
67.3K

Stable Diffusion 3 API
Stable Diffusion 3 is an advanced text-to-image generation system that rivals or surpasses top-tier systems like DALL-E 3 and Midjourney v6 in terms of layout and prompt following. This system employs a novel Multimodal Diffusion Transformer (MMDiT) architecture, utilizing different weight sets to enhance the representation of both images and language, thereby improving text understanding and spelling ability. The Stable Diffusion 3 API is now available on the Stability AI developer platform, offering fast and reliable API services in collaboration with Fireworks AI. It also promises to release model weights for self-hosting through Stability AI membership in the near future.
AI image generation
305.3K

MATHVERSE
The MATHVERSE project aims to evaluate the ability of multimodal large language models to handle and understand visual math problems, particularly in parsing and comprehending graphical information within problems.
AI Model
54.9K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M