%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Character Animation
Genie 2
Genie 2, developed by Google DeepMind, is a large-scale foundational world model capable of generating endless, operable, and playable 3D environments based on a single prompt image, designed for training and evaluating embodied agents. Genie 2 represents a significant advancement in the field of deep learning and artificial intelligence, showcasing various emergent capabilities in large-scale generative models, such as object interaction, complex character animation, and physical simulation, by simulating virtual worlds and their consequences. The research behind Genie 2 fosters new creative workflows for prototyping interactive experiences and opens up new possibilities for the development of future general AI systems and agents.
3D Modeling
73.4K
Joyvasa
JoyVASA is an audio-driven character animation technique based on diffusion models that generates facial dynamics and head movements by separating dynamic facial expressions from static 3D facial representations. This technology enhances video quality and lip-sync accuracy, expands into animal facial animation, supports multiple languages, and improves training and inference efficiency. Key advantages of JoyVASA include the ability to generate longer videos, motion sequence generation independent of character identity, and high-quality animation rendering.
Audio-Driven
60.2K

Animate X
Animate-X is a universal animation framework based on LDM, designed for various character types (collectively termed X), including humanoid characters. This framework enhances motion representation by introducing pose indicators, allowing for a more comprehensive capture of motion patterns from driving videos. The primary advantages of Animate-X include in-depth modeling of motion and the ability to understand motion patterns in driving videos, applying them flexibly to target characters. Additionally, Animate-X introduces the Animated Anthropomorphic Benchmark (A2Bench) to evaluate its performance on universal and widely applicable animated images.
AI image generation
70.4K
Protomotions
ProtoMotions is a project dedicated to creating interactive physics-based virtual agents. It supports IsaacGym and IsaacSim and is built on Hydra and OmegaConfig, facilitating simple configuration management. This project offers researchers and developers a platform to develop and test physics-based character animation techniques, applicable not only to academic research but also in fields such as gaming, film, and virtual reality.
AI Virtual Human
55.8K
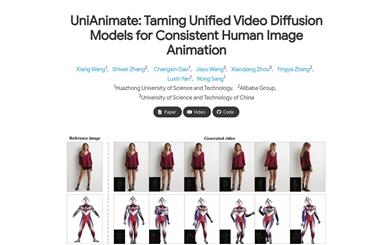
Unianimate
UniAnimate is a unified video diffusion model framework for character image animation. It maps reference images, pose guidance, and noisy video to a shared feature space, reducing optimization difficulty and ensuring temporal coherence. UniAnimate can handle long sequences, supports random noise input and first-frame conditioning input, significantly improving its ability to generate long-term videos. Additionally, it explores alternative time modeling architectures based on state-space models to replace the original computationally intensive time Transformer. UniAnimate achieves superior synthetic results compared to existing state-of-the-art techniques in both quantitative and qualitative evaluations, and can generate highly consistent one-minute videos through iterative use of the first-frame conditioning strategy.
AI video generation
107.1K
Rokoko
Rokoko is a sensor-based motion capture system that offers high-quality body, finger, and facial animation solutions for 3D digital creators. With its user-friendly interface and affordable price, it allows users to easily achieve realistic character animation.
AI design tools
77.6K
Vid2densepose
Vid2DensePose is a powerful tool designed to apply the DensePose model to videos, generating detailed 'body landmark' visualizations for each frame. This tool is particularly useful for enhancing animation, especially when used in conjunction with MagicAnimate, enabling seamless and temporally coherent character animation.
AI video editing
101.6K

Animate Anyone
Animate Anyone aims to generate character videos from static images driven by signals. Leveraging the power of diffusion models, we propose a novel framework tailored for character animation. To maintain consistency of complex appearance features present in the reference image, we design ReferenceNet to merge detailed features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guidance module to direct character movements and adopt an effective temporal modeling approach to ensure smooth cross-frame transitions between video frames. By extending the training data, our method can animate any character, achieving superior results in character animation compared to other image-to-video approaches. Moreover, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
AI video generation
11.4M
Rokoko Vision
Rokoko Vision is a free AI motion capture tool. Users can upload videos or use webcams for motion capture and edit and adjust them using the animation editor. The tool offers high-precision motion capture technology, allowing users to quickly create realistic character animations. Rokoko Vision's pricing varies depending on the user's location.
AI Action Capture
139.7K

Story To Motion
Story-to-Motion is a novel task that takes a story (top green area) and generates motion and trajectories consistent with the textual description. The system utilizes modern large language models as a text-driven motion scheduler, extracting a series of (text, location) pairs from long texts. It also develops a text-driven motion retrieval scheme, combining classic motion matching with motion semantics and trajectory constraints. Furthermore, it designs a progressive masking transformer to address common problems in transition motions, such as unnatural poses and sliding. The system excels in three different subtasks: trajectory following, temporal action combination, and action mixing, outperforming previous motion synthesis methods.
AI video generation
131.9K

Puppetry
Puppetry is a tool that uses your facial features to add animation to images. It allows you to quickly and easily create multiple variations for game characters, storyboard characters, or intermediate images. No binding, headgear, makeup, or lengthy shooting process is required, just your camera and some magic!
AI-powered image generation
56.9K
Movmi
Movmi is an AI-powered motion capture tool that captures human body movements from 2D media data (images and videos), providing developers with high-quality human motion capture solutions. The entire capture process is completed in the cloud, requiring no high-end equipment. Movmi supports capturing footage from various cameras, including smartphones and professional cameras, suitable for diverse life scenarios and even supporting multi-character scenes. Movmi also offers a full-text atlas character library for various animation projects. Movmi's membership plans are divided into Bronze, Silver, and Gold, offering different levels of features and experiences. Users can use the output FBX files in any 3D environment.
AI design tools
301.7K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M