%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


Audiolm
Overview :
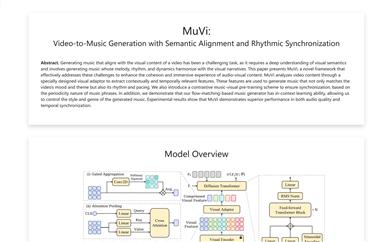
AudioLM is a framework developed by Google Research for high-quality audio generation with long-term consistency. It maps input audio to discrete token sequences and treats audio generation as a language modeling task in this representational space. By training on a large corpus of raw audio waveforms, AudioLM learns to generate natural and coherent audio continuations, producing grammatically and semantically plausible speech segments even without text or annotations while preserving the speaker's identity and prosody. Furthermore, AudioLM is capable of generating coherent piano music continuations, even though no symbolic representation of music was employed during training.
Target Users :
AudioLM targets audio engineers, music producers, speech technology researchers, and developers. It is well-suited for them as it provides an innovative method for generating high-quality audio content, including speech and music, without the need for complex manual editing or expensive recording equipment.
Use Cases
- Generate voice continuations of a specific speaker for speech synthesis applications using AudioLM.
- Create new piano music with AudioLM without needing sheet music or music theory knowledge.
- Use AudioLM to generate ambient sound effects and background music for movies or video games, enhancing the immersive experience.
Features
- Audio mapping: Maps input audio to discrete token sequences.
- Language modeling: Conducts language modeling tasks for audio generation in the representation space.
- Long-term structure capture: Utilizes discretized activations from pretrained masked language models to capture long-term structures.
- High-quality synthesis: Achieves high-quality synthesis through discrete codes generated by neural audio codecs.
- Natural audio generation: Generates natural and coherent audio continuations given a short prompt.
- Speech continuation: Produces grammatically and semantically plausible speech continuations without text or annotations.
- Music continuation: Learns to generate coherent piano music continuations even in the absence of symbolic representations of music.
- Mixed token framework: Combines the strengths and weaknesses of different audio tokenizers to achieve high-quality and long-term structural goals.
How to Use
1. Visit the AudioLM GitHub page to learn about the project details and installation guide.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Install the necessary dependencies and environment according to the guidelines.
3. Download and extract the AudioLM dataset, which contains the raw audio waveforms for model training.
4. Use the tools and scripts provided by AudioLM to start training the model.
5. Once training is complete, use the model to generate audio continuations or create new audio content.
6. Evaluate the quality of the generated audio and adjust model parameters as needed to optimize performance.
7. Integrate the generated audio into applications, websites, or other media projects.
Featured AI Tools
Suno AI
Suno AI is a product that creates music and voice using artificial intelligence. It leverages advanced algorithms and data models to generate high-quality music and voice output. Suno AI has the following features and advantages: 1. Creation of music in various styles, including pop, classical, and electronic; 2. Generation of natural and fluent voice, suitable for voice synthesis and dubbing; 3. Provision of rich music and voice effects, customizable to user needs; 4. Simple and user-friendly interface, easy to operate; 5. Support for multiple output formats, convenient for users to utilize on different platforms. Suno AI's pricing is determined based on user usage, for details, please visit the official website.
Music Production
3.3M
English Picks

Voicify.ai
Voicify AI is an AI music creation tool that enables users to create high-quality AI-generated vocal tracks. The platform offers hundreds of AI voice models uploaded by the community for users to utilize in their creations. Voicify AI supports cloning users' own voices, allowing them to build customized models. With Voicify AI, users can produce high-quality AI vocal tracks within seconds.
Music Production
1.8M