%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Streamvc
Overview :
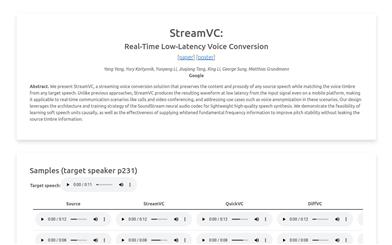
StreamVC is a real-time low-latency voice conversion solution developed by Google. It is capable of matching the target voice's timbre while preserving the source voice content and prosody. This technology is particularly suitable for real-time communication scenarios such as phone and video conferences, and can also be used for applications such as voice anonymization. StreamVC achieves lightweight and high-quality voice synthesis through the architecture and training strategies of the SoundStream neural audio codec. It also demonstrates the effectiveness of learning the causality of soft speech units while providing whitening base frequency information to improve pitch stability without revealing the source voice timbre.
Target Users :
StreamVC is designed for enterprises and individuals requiring real-time voice conversion, such as customer service representatives, video conference participants, and voice synthesis artists. It offers high-quality voice conversion while maintaining low latency to meet the demands of real-time communication.
Use Cases
Customer service representatives use StreamVC for voice conversion to provide anonymization services.
Voice conversion is used in video conferences with StreamVC to accommodate participants of various languages.
Voice synthesis artists employ StreamVC to create synthetic voices with specific timbres.
Features
Real-time low-latency voice conversion
Preserving source voice content and prosody
Matching the target voice's timbre
Compatible with mobile platforms
Suitable for real-time communication scenarios
Utilizing the SoundStream neural audio codec architecture
Learning the causality of soft speech units
Providing whitening base frequency information to improve pitch stability
How to Use
1. Download and install the StreamVC model.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Prepare source voice and target timbre sample.
3. Configure necessary parameters according to StreamVC's documentation.
4. Run the StreamVC model and input the source voice.
5. StreamVC will convert the voice in real-time and output a voice matched with the target timbre.
6. Adjust parameters as needed to optimize conversion results.




Featured AI Tools

GPT SoVITS
GPT-SoVITS-WebUI is a powerful zero-shot voice conversion and text-to-speech WebUI. It features zero-shot TTS, few-shot TTS, cross-language support, and a WebUI toolkit. The product supports English, Japanese, and Chinese, providing integrated tools such as voice accompaniment separation, automatic training set splitting, Chinese ASR, and text annotation to help beginners create training datasets and GPT/SoVITS models. Users can experience real-time text-to-speech conversion by inputting a 5-second voice sample, and they can fine-tune the model using only 1 minute of training data to improve voice similarity and naturalness. The product supports environment setup, Python and PyTorch versions, quick installation, manual installation, pre-trained models, dataset formats, pending tasks, and acknowledgments.
AI Speech Synthesis
5.8M

Clone Voice
Clone-Voice is a web-based voice cloning tool that can use any human voice to synthesize speech from text using that voice, or convert one voice to another using that voice. It supports 16 languages including Chinese, English, Japanese, Korean, French, German, and Italian. You can record voice online directly from your microphone. Functions include text-to-speech and voice-to-voice conversion. Its advantages lie in its simplicity, ease of use, no need for N card GPUs, support for multiple languages, and flexible voice recording. The product is currently free to use.
AI Speech Synthesis
3.6M