%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Emilia
Overview :
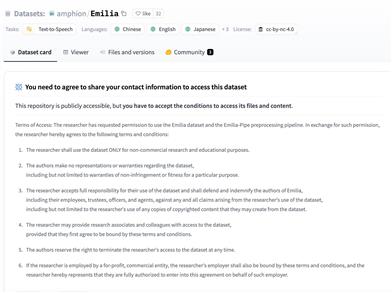
Emilia is an open-source multilingual field voice dataset specifically designed for large-scale voice generation research. It includes over 10,100 hours of high-quality voice data in six languages with corresponding text transcriptions, covering a variety of speaking styles and content types such as stand-up comedy, interviews, debates, sports commentary, and audiobooks.
Target Users :
The Emilia dataset is designed for scholars and researchers engaged in large-scale voice generation studies, particularly professionals focusing on multilingual voice synthesis and speech recognition technologies.
Use Cases
Develop multilingual voice synthesis systems
Serve as a training dataset to improve the accuracy of speech recognition algorithms
Used for language learning and voice teaching in educational settings
Features
Provides over 10,100 hours of high-quality voice data in six languages
Includes voice and text transcriptions in Chinese, English, Japanese, Korean, German, and French
Derived from diverse online video platforms and podcasts with a rich variety of content
Supports preprocessing using the open-source Emilia-Pipe pipeline
Allows researchers to download original audio files and reconstruct the dataset
Emilia-Pipe supports custom preprocessing of voice data to meet specific research needs
How to Use
1. Visit the Emilia dataset page and agree to the terms of use
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Download the required original audio files
3. Preprocess the data using the Emilia-Pipe preprocessing pipeline
4. Reconstruct the dataset according to research needs
5. Utilize preprocessed data for voice generation or other related research
6. Cite the Emilia dataset and Emilia-Pipe in research findings








Featured AI Tools

Openvoice
OpenVoice is an open-source voice cloning technology capable of accurately replicating reference voicemails and generating voices in various languages and accents. It offers flexible control over voice characteristics such as emotion, accent, and can adjust rhythm, pauses, and intonation. It achieves zero-shot cross-lingual voice cloning, meaning it does not require the language of the generated or reference voice to be present in the training data.
AI speech recognition
2.4M

Azure AI Studio Speech Services
Azure AI Studio is a suite of artificial intelligence services offered by Microsoft Azure, encompassing speech services. These services may include functions such as speech recognition, text-to-speech, and speech translation, enabling developers to incorporate voice-related intelligence into their applications.
AI speech recognition
271.3K