%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

LGM
Overview :
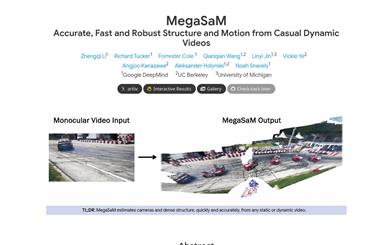
LGM is a novel framework for generating high-resolution 3D models from textual prompts or single-view images. Its key insights include: (1) 3D Representation: We propose a multi-view Gaussian feature as an efficient yet powerful representation that can be fused for differentiable rendering. (2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operation for multi-view images, which can be utilized to generate from text or single-view image inputs using multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our method. Notably, we achieve high-resolution 3D content generation while maintaining fast rendering speed for 3D objects, even when training resolution is increased to 512x512.
Target Users :
["3D Content Creation","3D Object Design","Virtual World Development"]
Use Cases
Generate a 3D model of a 'chair' described in text
Generate a 3D model of a 'car' from photographs
Generate a 3D model of a room from images taken from multiple angles
Features
Generate 3D models from text prompts
Generate 3D models from single-view images
Achieve high-resolution (512x512) 3D content generation
Differentiable rendering



Featured AI Tools
English Picks

Luma AI
Luma AI is an AI-focused technology company that enables users to quickly generate 3D models using their phones through its innovative technology. Founded by a team with extensive experience in 3D computer vision, Luma AI's technology is based on Neural Radiance Fields, allowing for 3D scene modeling from a limited number of 2D images. Dream Machine is an AI model capable of directly generating high-quality, realistic videos from text and images. It is a highly scalable and efficient transformer model trained specifically for video, capable of generating physically accurate, consistent, and event-filled shots. Dream Machine represents the first step toward building a universal imagination engine, now accessible to everyone.
3D Modeling
3.6M
Mootion
Mootion is an AI-native 3D creation platform dedicated to unleashing creativity for everyone in the digital realm. It transforms professional workflows into universal and user-friendly processes. Mootion aims to build an AI-powered creative hub encompassing 3D, video, animation, and game development, serving as a platform for inspiration, sharing, and collaboration.
3D Modeling
491.6K